在人工智能的广阔天地中,大型语言模型(LLM)已经证明了它们在多个任务上的卓越能力。然而,它们在创作长篇文本方面似乎遭遇了难以突破的障碍。不过,一项由清华大学携手智谱AI所取得的突破性进展,为这一难题提供了新的解决方案。这项被命名为"LongWriter"的成果,将AI在长文本生成方面的能力显著提升,从2000字一举扩展至超过10000字,同时确保了内容的高质量输出。这一进步得益于创新的数据构建技术、独到的模型训练方法以及严谨的评估流程,为AI在长篇文本创作领域的应用开辟了新天地。
在人工智能的广阔天地中,大型语言模型(LLM)已经证明了它们在多个任务上的卓越能力。然而,它们在创作长篇文本方面似乎遭遇了难以突破的障碍。不过,一项由清华大学携手智谱AI所取得的突破性进展,为这一难题提供了新的解决方案。这项被命名为"LongWriter"的成果,将AI在长文本生成方面的能力显著提升,从2000字一举扩展至超过10000字,同时确保了内容的高质量输出。这一进步得益于创新的数据构建技术、独到的模型训练方法以及严谨的评估流程,为AI在长篇文本创作领域的应用开辟了新天地。
论文链接:https://arxiv.org/pdf/2408.07055
项目地址:https://github.com/THUDM/LongWriter

本文所附图片均来源于论文开源项目。
01
在探索人工智能的广阔领域中,一项新的研究揭示了现有AI模型在创作长篇文本方面的一些挑战。研究者们对目前广泛使用的多篇章上下文大型语言模型(LLM)进行了深入的性能评估,他们开发了一套新颖的评估工具,名为"LongWrite-Ruler"。该工具要求模型生成不同长度的文章,范围从1000字延伸至30000字。
研究结果出人意料:即便是最前沿的模型,如GPT-4和Claude 3.5,也面临着生成超过2000字连贯文本的难题。为了深入理解这一现象并探究其根本原因,研究团队设计了两组细致的实验进行分析。
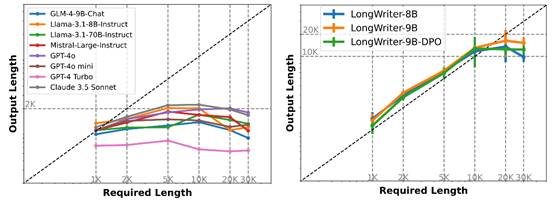
通过图1,我们可以直观地看到主流大型语言模型在长篇文本生成任务中的表现。模型理论上应能够精确达到所需的文本长度,但实验数据却显示出了明显的限制。无论是开源模型如GLM-4-9B-Chat、Llama系列,还是商业模型如GPT-4、Claude 3.5 Sonnet,当文本生成需求超过2000字时,模型的表现都趋于平稳,难以突破这一界限。
进一步的分析,如图2所示,揭示了这一限制可能的原因。研究者们使用GLM-4-9B模型,通过调整其训练数据集中的最大输出长度,观察了模型输出能力的变化。他们发现,模型的最大输出能力与其训练数据中的最长样本长度紧密相关。当训练数据限制在500字时,模型的输出也难以超越这一限制;而当训练数据扩展至2000字时,模型的输出能力也随之提升。
这一系列控制实验最终指向了一个关键的发现:模型的最大输出长度直接受其训练数据集中最长样本长度的限制。简而言之,模型的输出能力被其"阅读"过的内容所限制,这解释了为何当前模型普遍存在大约2000字的输出瓶颈——因为在现有的训练数据集中,缺乏足够长度的样本。
基于这些发现,研究团队为提升大型语言模型的长篇文本生成能力指明了方向:通过构建包含更多长文本的高质量训练数据集,有望显著提高模型的表现。这一策略不仅能够推动AI技术的发展,也为未来的长篇文本创作打开了新的可能性。
02
面对长篇文章创作中的挑战,我们的科研团队推出了一款创新的智能代理系统——AgentWrite。该系统采用了一种巧妙的策略,将复杂的长篇写作任务分解为一系列独立且易于管理的小任务。
AgentWrite的操作流程主要分为两个阶段:
1. 筹划阶段:在这一阶段,系统根据用户给出的写作指导,制定出一份详尽的写作计划。这份计划详细列出了每个段落的主要内容和预期字数。

2. 撰写阶段:遵循筹划阶段的计划,系统逐步生成文本内容。在生成新段落时,系统会利用之前生成的内容作为上下文,确保文本的连贯性。
AgentWrite的工作流程如图3所示,它采用了一种典型的“先规划再撰写”的方法。在面对如“撰写一篇关于罗马帝国历史的30,000字长文”这样的任务时,传统的大型语言模型往往难以产出丰富的文本。AgentWrite通过以下步骤巧妙地解决了这个问题:
1. 筹划阶段(STEP I:
Plan):系统首先创建一个详细的写作大纲,将长文任务分解为多个易于控制的段落,每个段落都有明确的主题和字数目标。
例如:
- 第一段:介绍罗马帝国的起源,预计700字。
- 第二段:描述罗马帝国的建立过程,覆盖800字内容。
-
...
- 第十五段:总结罗马帝国的历史,预计500字。
2. 撰写阶段(STEP II:
Write):根据筹划阶段的大纲,系统依次生成每个段落的文本。每个段落都严格遵循大纲中的主题和字数要求。

例如:
- 第一段标题:《I. 罗马帝国的起源:从王国到共和国》,深入分析罗马帝国的早期历史。
- 第二段标题:《II. 罗马帝国的形成:凯撒、屋大维和第二次三头同盟》,详细解读帝国建立的关键时期。
-
...
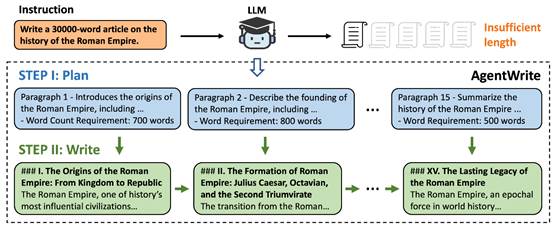
通过这种创新的方法,AgentWrite不仅充分利用了现有大型语言模型的能力,生成了结构严谨、内容连贯的长篇文本,而且有效克服了单个模型在长文生成方面的限制。这种“分而治之”的策略不仅确保了文本的长度,还保持了整篇文章的逻辑连贯性和高质量。
03
LongWriter-6k——塑造卓越的长文本训练数据源
在科技的浪潮中,一项创新的数据集——LongWriter-6k,以其卓越的长文本训练能力,为深度学习领域注入了新的活力。这个数据集的构建过程体现了科研团队的严谨和专业,具体步骤如下:
首先,研究者们在庞大的数据海洋中筛选出了3000篇中文和3000篇英文的长文本写作指令,这些指令的挑选过程极为严格,确保了数据集的高质量起点。
接着,利用AgentWrite工具和GPT-4o模型的强大能力,为这些指令生成了相应的长文本回应。这一步骤不仅展现了技术的力量,也体现了人工智能在文本生成领域的应用潜力。
最后,研究团队对生成的数据进行了细致的后处理,包括剔除不符合标准的短文本和清除无关的标识符,确保了数据集的纯净度和实用性。
LongWriter-6k数据集的输出长度跨度广泛,从2000字到10000字不等,这一特性不仅填补了长文本领域的空白,更为深度学习模型的训练提供了坚实的数据支撑。这一创新的数据集,无疑将成为推动人工智能发展的重要力量。
04
LongWriter模型——引领人工智能撰写长文本的新纪元
在人工智能领域,一项突破性的模型——LongWriter,标志着长文本撰写的新篇章。研究团队在开源模型的基础上,经过深入研究和多次试验,成功开发出了这一模型。LongWriter模型现已在Huggingface平台上公开,同时,社区用户也提供了GGUF量化版本,方便本地部署使用。
LongWriter模型包括两个版本:
- LongWriter-9B,基于GLM-4-9B模型架构。
- LongWriter-8B,基于Meta-Llama-3.1-8B模型架构。
模型训练过程的亮点在于:
1. 数据融合:LongWriter-6k与超过18万条通用SFT数据的巧妙结合。
2. 损失计算:采用token平均损失计算策略,避免长文本样本在训练中被忽略。
3. 硬件配置:使用8块H800 80G GPU,结合DeepSpeed+ZeRO3+CPU
offloading技术。
4. 训练参数:batch size设为8,学习率1e-5,packing
length32k,训练周期4个epoch。
为了进一步提升模型性能,研究人员对LongWriter-9B进行了直接偏好优化(DPO)。DPO数据包括:
1. 5万条通用DPO数据。
2. 4千条针对长文写作的专门数据,这些数据是从LongWriter-9B的输出中经过严格评分和筛选得出。
通过DPO微调,LongWriter-9B-DPO模型在输出质量和长度控制方面表现出色,成为综合性能最为优秀的模型。这一成果不仅提升了人工智能在文本生成领域的应用能力,也为科研工作者和技术开发者提供了强大的工具。
5
为深入探究人工智能在长文本生成领域的潜力,研究团队精心设计了一个名为"LongBench-Write"的评估平台。该平台汇集了超过120个多样化且具有特色的用户写作指令,全面覆盖了不同长度和类型的需求。
在"LongBench-Write"的评估体系中,我们特别关注两个关键指标:
1. 输出长度得分(S_l):衡量模型输出文章长度是否满足要求,反映其对指令的忠实度。
2. 输出质量得分(S_q):基于GPT-4o的评价标准,从六大维度(相关性、准确性、连贯性、清晰度、广度深度、阅读体验)全面评估文章质量。
"LongBench-Write"的评估结果为我们提供了对"LongWriter"模型在长篇写作任务中卓越表现的独到见解。图表数据详细列出并对比了多款专用模型、开源模型及"LongWriter"系列模型在不同长度约束下的实际表现。评估指标包括:
- 综合评分(整体热度值)
- 输出长度得分(满足长度要求的比例)
- 输出质量得分(六个维度分析所得分数)
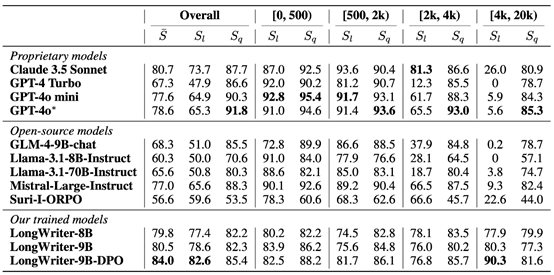
1. 整体表现全面领先:
"LongWriter-9B-DPO"模型以84.0分的优异成绩在综合评分方面遥遥领先,超越了包括GPT-4o(78.6分)和Claude 3.5 Sonnet(80.7分)在内的所有参比模型。
2. 长文生成能力卓越非凡:
在4000至20000字的超长文本生成任务中,"LongWriter-9B-DPO"模型的输出长度得分(S_l)高达90.3,远超其他模型。相比之下,大多数现有模型在此长度区间的得分几乎为零,显示出它们在处理大规模文本生成任务时的局限性。
3. 输出质量稳定如一:
即使在处理超长文本时,"LongWriter"模型依然保持极高的输出质量。在4000至20000字的范围内,"LongWriter-9B-DPO"模型的质量得分(S_q)达到81.6,与处理较短文本时的表现相差无几。
4. 各长度范围表现全线领先:
"LongWriter"系列模型在各个长度范围内均表现出色,尤其是在2000字以上的任务中,更是大幅度超越其他模型。这有力证明了我们研究方法的优越性,既提升了模型的长文生成能力,又确保了短文生成品质。
5. 开源模型的重大突破:
作为开源模型,"LongWriter"系列的表现甚至超越了许多知名的专用模型,这对推动开放式人工智能研究具有重大意义。
这些成果充分展现了"LongWriter"技术的强大效能。通过创新性的训练方式和精细化的数据构建策略,我们成功将模型的长文生成能力从传统的2000字左右大幅提升至10000字以上,同时保持了高质量的输出水平。这一突破性进展为人工智能辅助写作、内容生成等领域开启了新篇章,有望在学术研究、商业报告、创意写作等多个领域产生深远影响。
6 技术创新亮点及其潜在影响力
在科技的前沿,一系列创新技术正在重塑人工智能的长文本生成能力。以下是这些技术突破及其潜在影响的概述:
1. AgentWrite智能代理:这项技术通过独特的任务分解和连续生成方法,有效克服了人工智能在处理长篇文本时的障碍。
2. LongWriter-6k数据集:为长文本生成模型提供了丰富的训练材料,填补了现有数据集在长文本领域的空白。
3. 创新性训练策略:通过调整损失函数的计算方式,确保长文本样本在训练过程中得到充分重视。
4. DPO微调:这种精细的调整方法显著提升了模型在长文本生成的质量和长度控制上的表现。
这些技术突破预示着人工智能在以下领域的应用前景:
1. 内容创作:人工智能将助力创作者快速生成高质量的长篇文章、报告甚至书籍。
2. 教育培训:人工智能可以生成详尽的教学资料、课程大纲或学习指导,提升教育效率。
3. 商业报告:自动化生成全面的市场分析报告、财务报表等,提高商业决策的效率。
4. 科研辅助:帮助研究者快速生成文献综述或研究提案,加速科研进程。
在生成式人工智能领域,长文本生成一直是一个具有挑战性的任务。然而,随着这些技术问题的解决,中文Agent的发展有望达到新的高度。
对人工智能行业的潜在影响包括:
1. 重新定义AI写作能力:LongWriter技术有望彻底改变人们对人工智能写作能力的看法,使其在长文本创作领域更具竞争力。
2. 推动数据集建设:研究成果凸显了高质量长文数据集的重要性,可能会激发业界对此类数据集的关注和投入。
3. 促进AI应用创新:长文本生成能力的突破可能催生全新的AI应用场景,如自动编写书籍、生成详细的技术文档等。
清华大学与智谱AI的联合研究不仅攻克了人工智能长文生成的技术难题,更为人工智能在复杂写作任务中的应用开辟了新机遇。LongWriter技术的问世,展现了人工智能写作能力的显著提升,它不仅能够生成更长的文本,还注重保持文本的高质量和连贯性。展望未来,我们有理由期待人工智能在复杂写作任务中成为人类的可靠伙伴,并实现更多令人瞩目的突破。
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip