MimicTalk是浙江大学和字节跳动联合研发的项目,利用NeRF技术快速训练高质量3D说话头像模型,提高个性化数字人视频生成效率和质量,适用于娱乐、教育、社交等领域,支持快速个性化训练、高质量视频生成、上下文学习和音频驱动,可应用于虚拟主播、视频会议、VR/AR、社交媒体、客户服务等场景,并提供了详细的部署条件和步骤。
随着数字人技术的发展,生成高度逼真的「3D说话头像」(3D Talking Face)成为了一种趋势。这不仅对于娱乐行业有着重要的意义,同时在教育、社交等领域也展现出巨大的潜力。「MimicTalk」是由浙江大学和字节跳动联合研发的一个项目,它利用先进的NeRF(神经辐射场)技术,在「短时间内训练出高质量」的3D说话头像模型,极大地提高了个性化数字人视频的生成效率和质量。
技术背景
传统的3D说话头像生成方法往往需要大量的数据和长时间的训练过程,这对于资源有限的个人或小型团队来说是一个不小的障碍。MimicTalk通过引入「NeRF」技术,结合高效的微调策略和上下文学习能力的人脸动作生成模型,成功地解决了这一问题NeRF技术允许模型在三维空间中重建物体的形状和外观,而MimicTalk在此基础上进行了优化,使其能够快速适应新的身份特征,从而实现个性化3D头像的快速生成。
NeRF技术
NeRF(Neural Radiance Fields)是一种基于深度学习的3D重建技术,通过学习从不同视角拍摄的图像,可以重建出高精度的3D场景。NeRF的核心思想是「将场景建模为一个连续的3D辐射场,并通过神经网络预测给定位置和方向的辐射强度」。这种技术在保持高分辨率的同时,能够生成高质量的3D内容,非常适合用于3D说话头像的生成。
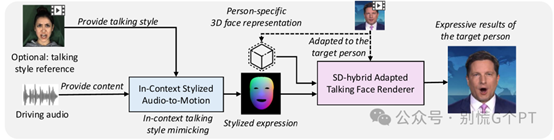
MimicTalk功能点
「快速个性化训练」
- 高效训练:MimicTalk能够在短短「15分钟」内完成对新身份的个性化调整,显著提高了训练效率,相比传统方法快了「47倍」。
- 样本效率:MimicTalk的设计注重样本效率,能够在「极短的时间」内用少量数据完成新身份的适应,减少了对大量标注数据的依赖。
「高质量视频生成」
- 视觉质量:MimicTalk生成的3D头像在视觉质量上超越了以往的技术,能够生成「高度逼真的面部细节和表情」。
- 动态表现力:通过上下文风格化的音频到运动模型(ICS-A2M),MimicTalk能够「捕捉和模仿目标人物的动态说话风格」,使生成的视频更加生动和富有表现力。
「上下文学习」
- 上下文感知:MimicTalk的ICS-A2M模型能够从「上下文中学习目标人的说话风格」,提高面部动作的自然度和真实感。这种上下文学习能力使得生成的视频更加贴近真实情况。
「音频驱动」
- 音频同步:MimicTalk支持用音频输入驱动特定人物的3D说话头像,实现「音频到面部动作的同步」。这种技术使得生成的视频更加自然和连贯。
应用场景
虚拟主播与数字人
- 「新闻播报」:创建虚拟主播进行新闻报道,降低成本并实现全天候播出。
- 「娱乐节目」:生成虚拟角色,提供更加自然和吸引人的观看体验。
视频会议与远程协作
- 「远程工作」:为用户提供个性化的虚拟形象,增加互动性和沉浸感,提升沟通效率。
虚拟现实(VR)与增强现实(AR)
- 「游戏体验」:生成高度真实的虚拟角色,提升游戏体验和互动质量。
社交媒体与娱乐
- 「虚拟形象」:用户可以创建自己的虚拟形象,在社交媒体上分享或在虚拟世界中互动。
客户服务与聊天机器人
- 「客户服务」:开发更加人性化的客户服务机器人,提供更加自然和亲切的客户体验。
MimicTalk 部署条件与部署步骤
部署条件
「硬件要求」:
- 「CPU」:建议使用多核处理器,如Intel Core i7或更高。
- 「GPU」:建议使用NVIDIA GPU,至少16GB显存,如RTX 3090或更高。
- 「内存」:至少32GB RAM。
- 「存储」:至少100GB可用磁盘空间。
「软件要求」:
- 「操作系统」:推荐使用Linux(如Ubuntu
18.04或更高版本),也可以在Windows和macOS上运行,但可能需要额外的配置。
- 「Python」:3.9或更高版本。
- 「CUDA」:确保安装了与GPU兼容的CUDA版本。
- 「PyTorch」:1.10或更高版本。
- 「其他依赖」:见requirements.txt文件。
部署步骤
「克隆项目仓库」:
git clone https://github.com/yerfor/MimicTalk.git
cd MimicTalk
「创建并激活Python环境」:
conda create -n mimictalk python=3.9
conda activate mimictalk
python3 -m venv mimictalk
source mimictalk/bin/activate
「安装依赖」:
pip install -r requirements.txt
「下载预训练模型」:
- 下载预训练模型文件,例如lrs3.zip和May.zip,并将它们解压到checkpoints目录中:
wget https://example.com/lrs3.zip
wget https://example.com/May.zip
unzip lrs3.zip -d checkpoints
unzip May.zip -d checkpoints
「准备数据」:
- 准备目标人物的视频数据,将其解压到data目录中:
unzip target_person_video.zip -d data
「训练模型」:
python train.py --config config.yaml
「生成3D说话头像」:
python infer.py --config config.yaml --input_audio input_audio.wav --output_video output_video.mp4
「验证结果」:
- 检查生成的3D说话头像视频,确保质量和同步效果符合预期。
示例脚本
以下是一个完整的示例脚本,展示了如何从克隆项目到生成3D说话头像的全过程:
# 克隆项目仓库
git clone https://github.com/yerfor/MimicTalk.git
cd MimicTalk
# 创建并激活Python环境
conda create -n mimictalk python=3.9
conda activate mimictalk
# 安装依赖
pip install -r requirements.txt
# 下载预训练模型
wget https://example.com/lrs3.zip
wget https://example.com/May.zip
unzip lrs3.zip -d checkpoints
unzip May.zip -d checkpoints
# 准备数据
unzip target_person_video.zip -d data
# 训练模型
python train.py --config config.yaml
# 生成3D说话头像
python infer.py --config config.yaml --input_audio input_audio.wav --output_video output_video.mp4
通过以上步骤,您可以成功部署并使用MimicTalk生成高质量的3D说话头像。
原文出自:https://mp.weixin.qq.com/s/x9feODwVN1VWpE1YoqQ6eA
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip