文章总结了关于OpenAI的o3模型的技术分析、能力理解、推理方式探讨、跨领域泛化、评论与展望等内容。指出o3作为o1的继承者,在能力上有大幅提升但成本也显著增加,采用可能的多路推理方式,并在推理成本和技术发展路径上进行了讨论,认为LLM尚未撞墙,并对未来2年发展保持乐观。同时,提到OpenAI内部可能有多线探索,o系列模型可能逐步成为主流。此外,还讨论了推理成本的优化可能性和o系列模型与Agent的关系。
目前o3放出的信息还不多,但还是有一些内容可以做技术分析的。以及o3的重要性值得做一个专篇讨论。
1、o3
1.1、o3的基本信息
o3其实是o1的继承者,不叫o2是因为有一个同名的公司,所以直接跳到o3。OpenAI官方也承认自己的命名很糟糕。
(我认为)o3并不是AGI,OpenAI也没有说o3是AGI。
LLM在某些方面超过人类,但并不是所有方面都超过人类。这句话从ChatGPT
3.5到现在都成立,只是LLM可以做的更好的事情越来越多了。
目前关于o3最多可信信息的材料是Arc Prize发布的报告:
https://arcprize.org/blog/oai-o3-pub-breakthrough
中文版 OpenAI o3是AGI吗
对于o3的成本有这张图:
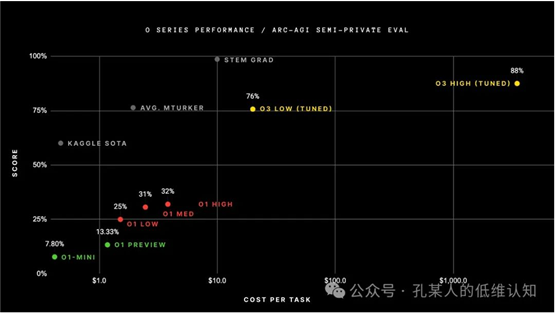
但这个图有几个注解:
- o3模型是针对该测试集优化过的,也就是图里Tuned所指的
- 目前o3的 high-compute 模式定价还没有确定,所以图例的定价并不对,大概只是Arc基于token数量进行线性推断的。
文中提到了一个sample size,但并没有指明其具体含义。只知道low-compute对应于6,high-compute对应于1024。
考虑到OpenAI在o3正式版发布时仍会进行不少调整,所以该图中的score和cost都可能会有显著调整。
但有两点我是相信的:o3正式版的能力会有大幅提升,成本也会有大幅提升。
1.2、如何理解o3的能力
大模型的能力与人并不相同,o3可以完成一些常人很难胜任的工作,但也有很多对人简单的问题o3很难完成。
但现在确实如何理解o3的能力对公众已经成了一个挑战。我们知道一些测试真的很难,但它到底有多难?
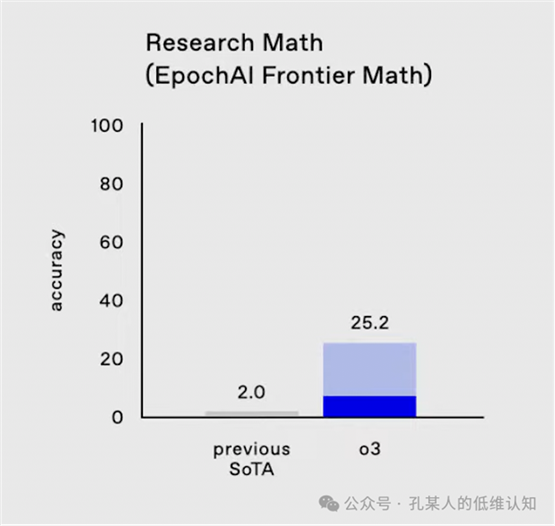
以FrontierMath这个测试为例,o3的成绩从之前的2%提升到25.2%。这意味着什么呢?
陶哲轩对这套测试题的难度评价是:
- “These are extremely challenging... I think they
will resist AIs for several years at least.”
- “这些都是极具挑战性的......我认为它们至少能抵抗人工智能几年。”
来自 https://epoch.ai/frontiermath
我找不到陶哲轩说这句话的时间,我猜他是在2024年说的,但现在这个测试集已经被解决了1/4。应该说顶级数学家评价非常有挑战性的问题,看到GPT4之后他仍然觉得会需要几年时间AI才能搞定的问题,现在已经沦陷了1/4。
估计到这里,读者才能感受到一些震撼,o3在某些方面的能力已经远远超出了公众的想象。不过,o3在很多问题上仍然束手无策,就像是一个非常偏科的学生。
实际上别说是o3,如何理解o1的优势,如何理解o1
pro mode的优势,能够较好的预判在具体场景中哪个的性价比更高都是个颇为困难的事情。至少我目前还没弄明白o1 pro mode相对于o1的具体提升到底在哪些方面。
现在如何构造出足够难的benchmark已经成为一个实质性的问题,而大部分人都无法理解这些benchmark到底意味着什么。
2、技术分析
2.1、推理方式分析
在o3发布前,一部分人能想象的是o系列模型的reasoning token会继续增长,按照之前的习惯,大概就是一个每多少个月提升多少倍的经验公式。但o3的信息着实吓了大家一跳,只过了3个月,推理成本可以增加2-3个数量级。
面对这个结果,确实我之前低估了软件领域的前进速度。这不像是芯片受到制造工艺迭代和物理条件等各方面限制,软件是可以快速吃掉所有硬件资源的。
有经验的工程师都知道,即使是软件方案,面对跨越数量级的规模增长时,都是没那么容易的。经常每提升3倍都会面对新的问题。而o3能这么快的将推理规模提升2个数量级以上,肯定不是因为OpenAI非凡的团队快速搞定了很多问题,3倍、3倍这样弄上去的。
而能够快速增加推理规模的方案就屈指可数了,最典型的就是以各种探索类算法为主,接近暴力的探索可以消耗很多算力,但实现方式并不复杂。从简单的广度优先搜索到MCTS,都符合这个特点。
有理由相信o3实装了多路推理。而且反过来说,我并不觉得o3模型能在单路推理的情况下将推理长度扩展2个数量级以上并维持效果始终有收益。
2.2、从o1到o3
在o1-preview刚发布时,我就写过一篇 o1模型的技术分析(1),指出o1系列应该使用的是单路推理。到目前为止,我仍然相信这个判断。但对于reasoning_effort参数,我目前对它没有一个我比较确信的猜测。
但o1 pro mode似乎有所不同,它的CoT概括的表现看起来跟o1并不一样。我目前对它的观察还不够,还不能直接基于其表现来给出一个我比较确信的猜测。希望o1 pro mode的API能够早点推出。
而o3看起来应该是使用某种多路推理的方式,虽然并不能确定到底是怎么产生的多路。
目前o1还有两个无法解释的地方:
- o1模型API不能控制temperature
- o1的reasoning token总是64的倍数
2.3、多路推理方式的推测(1)
一种最简单的方式就是多路采样+简单的多路结果归并。但这种方式其实很早就可以使用,且由于多路推理中经常有语义重复的部分,所以reasoning token的利用率很低,从技术品味上来说也很丑。拿来刷benchmark分数可以,但直接做产品化方案的话,总感觉有些问题。
从个人品味来说,我很不愿相信o3采用了这样的方案。但这确实是一种解释Arc报告中sample num的有效方式。以及考虑到偏好简单模型设计的风格,我确实得承认这个的可能性不小。
另一种常见思路是Beam Search类试图寻找Top K概率序列的方式,探索过程在生成过程中不断分叉。但根据我之前对于LLM Beam Search的实验 LLM Decode不需要Beam
Search——理解LLM输出的序列空间,这样的效果应该也较差。对多路reasoning token的利用率相对于上面并没有明显提升,但实现复杂度高了不少,还一定程度上影响了并行效率。所以我认为可以排除这种可能。
2.4、多路推理方式的推测(2)
本节讨论另一种实现的可能性,这也是我原本的第一猜测。它可能不一定能在o3上实装,但可能会在o4上实装。
如果没有采用上一节的方案,那么下一个适合的思路是:从单路开始,以某种方式进行多层次分叉的,类似Tree of Thought思路的方式。说到ToT,一个显然的问题是:o3是否实现了Thought的某种程度的结构化?
虽然我过去曾是LLM半结构化输出的鼓吹者,但我目前认为某种程度的细粒度Thought结构化是不容易实现的,考虑到OpenAI的开发时间,以及结构化并不能很好scaling到各个领域,这个方式也不像是符合OpenAI内部品味的,o3/o4大概不是用的细粒度结构化Thought的方式。
那么该如何在推理时找到合适的地方进行分叉,并如何产生分叉的不同路径呢?难道是每64token检查一次么?这种方案我无法接受。我目前推测(推测2)o3/o4可能采用更粗粒度(更大尺度)的某种结构化,例如Step,可以在每个Step结束后产生一个特殊标记,并能够输出多个后续Step方向。这种方案的实现方式不止一种,可以在训练数据中埋入经过处理好的Step标记,也可以后续在输出流中使用旁路模型进行划分,甚至可以训练每次只生成一个Step就停止(这样更接近于AutoGPT)。这方面的工作可能跟现在的分步CoT的概要提炼方案有技术重叠。
在token推理空间中,每个位置的分叉方案应该非常有限,所以也不需要很认真的概率计算或排序。对于分支的选择、分支的结束判定等,都仍然可以使用LLM来进行完成。整个方案其实跟标准的MCTS是比较类似的。
2.5、跨领域泛化的免费午餐还存在
无论是从推理还是数学还是代码生成,能合成数据的方面其实很有限。那么就有了一个问题:o1的这些方面能力提升是否能够帮助到其他方面?
我在9月的时候也有这方面的担忧,但我现在没有这个担忧了。我确实看到了一些在这些能力外的提升,跨领域泛化的免费午餐还在,这就够支撑一段时间了。当然虽然可以跨领域泛化,但不代表所有领域的能力都跟数学一样好。
3、评论与展望
3.1、LLM撞墙了么?
o3的发布已经说明至少目前LLM还没有撞墙。
但多路推理的使用在不同人来看有着不同的意味。有些人认为“都需要采用这么极限的方案,说明已经没着了,后面就要撞墙了”。我在一年前也大概会说类似的话。
但人是会成长的,我在 个人对大模型方向的认知回顾(1)就已经总结了,我过去1年多犯得一个主要错误就是错误低估了新技术方案的出现。原有的方案会撞墙,但新的修补方案也会出现。每个小方案快速达到顶峰,然后交棒给后续的方案,使得整体来看是持续发展的。
我目前对未来2年的LLM发展保持乐观。虽然我能够看到的未来跟Ilya说的一样,目前只看到了合成数据和推理时计算,但我对未来的未知保持乐观。
3.2、OpenAI内的其他路线
还有一个现在大家的分歧点是,o系列到底是不是“GPT正统路线”,OpenAI内部到底还有没有GPT-4.5、GPT-5的路线探索。这个问题其实很主观,我说下我的观点。
首先,我认为OpenAI内部是多线探索的。这也是OpenAI在过去2年内能够多线开花,尽量保持持续交付的方式之一。在这个组织状态下,没有什么只做A,不做B的问题,只有A获得了多少投入、B获得了多少投入的问题。
第二,我相信在o1推出时,OpenAI内部并没有认为这就是GPT-5,所以才给了它这样一个名字,在当时官方也有表态这是一个推理模型路线。他们现在内部是否还是这么认为我不清楚,但可能仍然没有“把o系列扶正”。
虽然人的意志可以一定程度上左右技术的发展,但大尺度上来说,技术的发展路径不以人的意志为转移。现在o系列模型已经表现出了它的短期(1-2年)价值,而GPT-5方面则持续难产。事实上,o1系列就是OpenAI在GPT-4之后的下一个突破,而GPT-5并没有赶上这一点。虽然现在我估计他们内部对于探索GPT-5的耐心还没有耗尽,但可能过不了半年就会耗尽,把o系列模型扶正。
打个比方来说:OpenAI只是上帝实现AGI的阶段性工具之一,但OpenAI自己并不是上帝。OpenAI自己的认知未必正确,OpenAI也未必明白它所做的所有事情意味着什么。
技术的发展是出人意料的,虽然目前看起来o系列模型价值很高,但再下一代模型很可能还有一些别的feature,这时候传统路线可以卷土重来,或者是又有另外的方案。每个具体方向的进展汇聚起来,有了整体技术路线的持续发展,但不能保证每个具体的技术路线在每年都能有进展。
3.3、大佬对LLM下一步发展的展望
目前还在OpenAI任职的人的意见可能受到Altman的控制,但12月已经连续有两位离开OpenAI的大佬公开表达了他们看好o系列的路线。
Ilya提到了下一步的两个价值很高的方向:合成数据与推理时计算。
合成数据也是一个被用烂了的词,但真正让人感受到其能力是《Physics of Language Models》系列工作,对此有兴趣的读者都建议去认真看下该系列的工作 论文解读:Physics of Language Models(面向应用层读者)。而到目前为止,o1系列在数学推理上的合成数据只是该方向的一个简单应用。
3.4、推理成本
可能会有不少人担心这快速增长的推理成本该如何处理。
Richard Sutton的Bitter
Lesson 教导我们,要正确预判未来会快速发展的领域,并去依赖它。我认为优化推理速度、降低推理成本是人类所擅长的,我相信我们还会看到一段时间的快速发展,至少4年内应该没问题。
而且这个问题你去问黄仁勋,他肯定不担心,在9.18的T-Mobile
Capital Markets Day 2024会上,黄仁勋提到:
Now you get one of the things that Sam introduced
recently, the reasoning capability of these AIs are gonna be so much smarter,
but it's gonna require so much more computation. And so, whereas each one of
the prompts today into ChatGPT is a one pass, in the future is going to be
hundreds of passes inside. It's gonna be reasoning, it's gonna be doing
reinforcement learning, is gonna be trying to figure out how to create a better
answer reason, a better answer for you. Well, that's the reason why in the Blackwell
platform, we in we improved inference performance by 50 x by improving the
inference performance by 50 x. That reasoning engine, which now could take up
to minutes to answer a particular prompt, could still now respond in seconds.
And so this is gonna be a great new world and I'm excited about that.
现在你知道了Sam最近介绍的一件事,这些AI的推理能力将会变得更加智能,但这也将需要更多的计算资源。当前,每个输入到ChatGPT的提示都是一次通过处理,而在未来,它将会进行数百次的处理。它会进行推理、强化学习,并尝试找出如何为你生成一个更好的回答、更合理的回答。这就是为什么在Blackwell平台上,我们通过提高50倍的推理性能来提升推理速度。通过将推理性能提高50倍,这个推理引擎,即便现在处理某个提示可能需要几分钟,也能在几秒钟内给出回应。所以,这将会是一个美好的新世界,我对此感到非常兴奋。
https://www.youtube.com/watch?v=r-xmUM5y0LQ 1:40:30
要说的话,也就是未来2年,国内的高端芯片采购有些问题,不能随意大量采购。但也并不是买不到,反而是各种倒卡的公司担心的是国内的这些人不训模型了,不买卡。
3.5、o系列与Agent
在o1-preview刚发布后,我就提到o1模型其实很像是一种简单Agent了。如果o3采用了多路推理,那么他就更像是一个传统意义上大家想象的Agent了。
顺便说一个我目前想到的区分Agent和Workflow方案的标准:如果开发者也不能在系统执行例如3步之后预测它的行动,那么它就更接近于Agent,否则就更类似于Workflow。这也符合Ilya最近提到的,越智能的系统越难预测。
后面推理模型的会变得更像是Agent,它们也能更好的赋能上面的一些真Agent架构,例如AutoGPT,而不是GraphRAG。这是我过去没有想到的。
原文出自:
https://mp.weixin.qq.com/s/WNAoPsRDyPqpqIW3wgRhRw
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip