随着LLM的蓬勃发展,企业、个人知识库越来越火。
但是随之而来的,也是两个问题:
一、搭建成本高。二:回答的内容结果不准。
第一个问题,其实之前写过一篇文章,教大家如何使用Dify极其简单的搭建自己私人知识库。
【有手就行】2分钟0代码,教你用Dify搭建专属AI知识库
但是随着而来的,就是很多人跟我反馈的:答的乱七八糟。
其实知识库的原理很简单。比如典型的Langchain-ChatGLM的架构图,加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到prompt中 -> 提交给LLM生成回答。
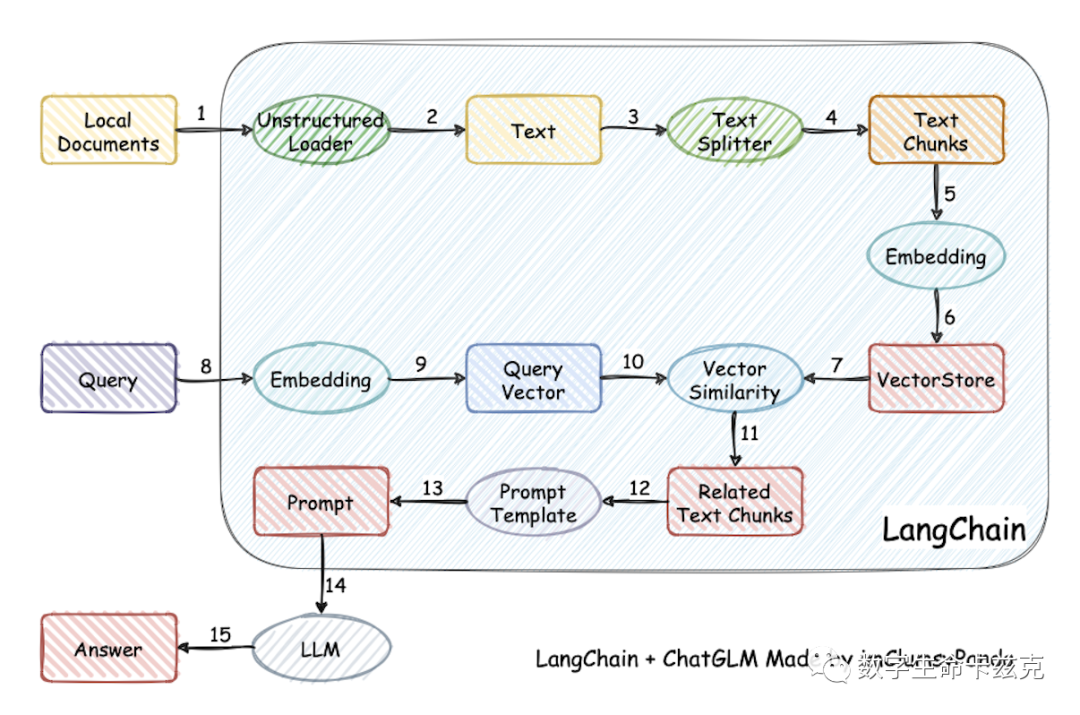
用大白话说,就是根据你的问题,去根据的你问题,去被切成N多块的文本块里,挨个搜索,找到一个或几个最相关的拿过来给大模型,让大模型根据这些搜出来的文本块作答。
而答得不准的原因,当然就是搜的不准。
搜的不准的原因,就是数据集太脏了。
我见过太多直接就把小说、把几十篇乱七八糟的文章往里面灌的,也太高看现在LLM的能力了,那里面的数据都乱成一团,一堆乱七八糟的口语化的甚至是无效信息,能准吗?所以就要做数据清洗,或者说,做一个结构化的数据集。
结构化的数据现在一般是两种,一种是树形结构,一种是问答对结构。
树形结构不多说了,适合超大型书或者一些超强的层级知识,这块推荐去看腾讯的teng大佬的文章:如何用 ChatGPT 搭建代码知识库,提升开发效率,写的很详细了。
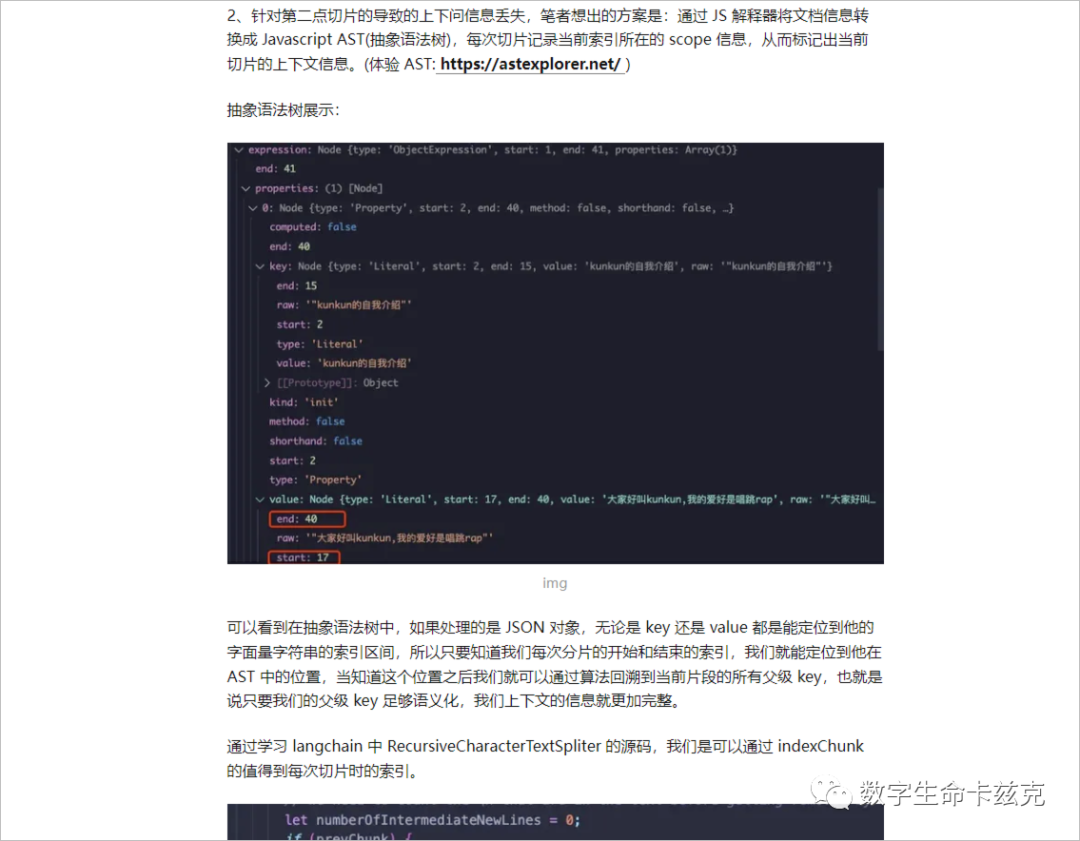
而另一种,就是我们常见的问答对格式,这里放一个GLM2的官方示例数据集你们就明白了。

我再写个示例
{"content":"介绍一下卡兹克","summary":"卡兹克其实是一个大智障,喜欢打游戏,任天堂死忠粉"}这个就叫问答对,把碎片化的大段的文章,转成一个一个的问答对数据集。
我到时候问卡兹克是谁,喜欢啥,大模型就不会瞎JB匹配,而是直接把这个问答对匹配出来,根据后面的答案进行回答,这样准确性就会高非常多。
但是又有很多人犯难了,这特么一个一个整理,那特么不得累死我?
那种微调质量的超高数据集,确实得一个一个手工处理。
但是你这就做个私人知识库,没必要,这里我教大家一个賊无脑的方法。直接拿GPT跑。
第一步,先让GPT对你的文档生成适合问答对的问题,第二步,让GPT根据生成出的问题和原内容,再按格式规范拼合成问答对。
我甚至都把Prompt写好了,直接拿去改吧改吧用就行。
这里直接用OpenAI的后台Playground跑了,因为有16K,而且可以锁system,方便。
https://platform.openai.com/playground
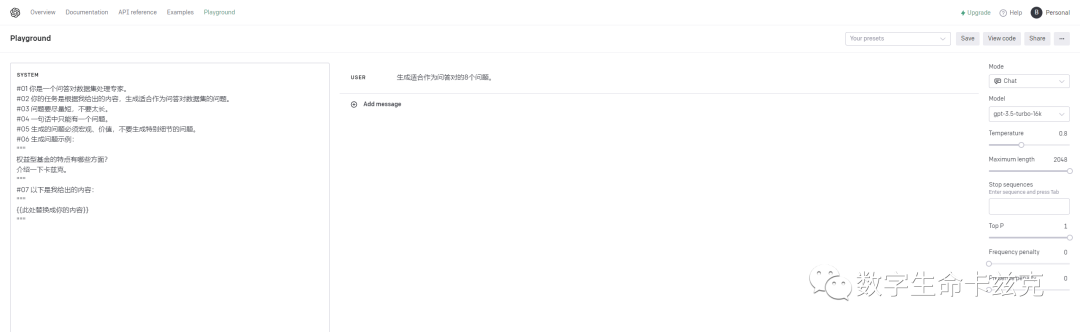
右边选16K模型,温度拉到0.8,最大输出直接拉满。
第一步,先生成问题。
system里面写我给的prompt。
#01 你是一个问答对数据集处理专家。
#02 你的任务是根据我给出的内容,生成适合作为问答对数据集的问题。
#03 问题要尽量短,不要太长。
#04 一句话中只能有一个问题。
#05 生成的问题必须宏观、价值,不要生成特别细节的问题。
#06 生成问题示例:
"""
权益型基金的特点有哪些方面?
介绍一下卡兹克。
"""
#07 以下是我给出的内容:
"""
{{此处替换成你的内容}}
"""在下面替换你的内容,Uesr那就是用户说的话,我就随便写了个生成8条问题。你想要10条、20条、40条都行。然后我随便找了我以前写的文章,扔了进去,8个问题就出来了。
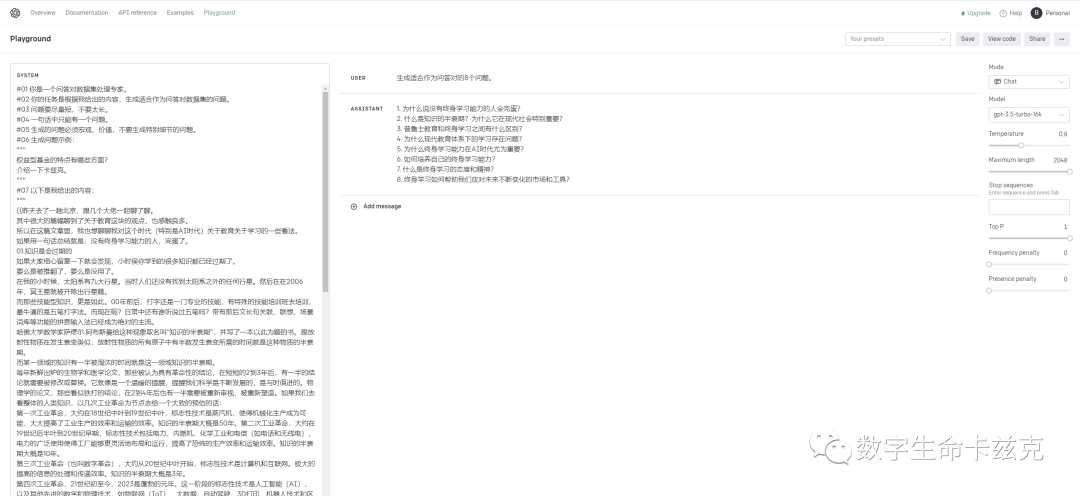
接下来这个窗口别动,也别关,我们新起一个一模一样的窗口。
第二步,根据问题和内容,生成问答对。
右边同样的参数,再把这个Prompt扔到System里。
#01 你是一个问答对数据集处理专家。
#02 你的任务是根据我的问题和我给出的内容,生成对应的问答对。
#03 答案要全面,多使用我的信息,内容要更丰富。
#04 你必须根据我的问答对示例格式来生成:
"""
{"content": "基金分类有哪些", "summary": "根据不同标准,可以将证券投资基金划分为不同的种类:(1)根据基金单位是否可增加或赎回,可分为开放式基金和封闭式基金。开放式基金不上市交易(这要看情况),通过银行、券商、基金公司申购和赎回,基金规模不固定;封闭式基金有固定的存续期,一般在证券交易场所上市交易,投资者通过二级市场买卖基金单位。(2)根据组织形态的不同,可分为公司型基金和契约型基金。基金通过发行基金股份成立投资基金公司的形式设立,通常称为公司型基金;由基金管理人、基金托管人和投资人三方通过基金契约设立,通常称为契约型基金。我国的证券投资基金均为契约型基金。(3)根据投资风险与收益的不同,可分为成长型、收入型和平衡型基金。(4)根据投资对象的不同,可分为股票基金、债券基金、货币基金和混合型基金四大类。"}
{"content": "基金是什么", "summary": "基金,英文是fund,广义是指为了某种目的而设立的具有一定数量的资金。主要包括公积金、信托投资基金、保险基金、退休基金,各种基金会的基金。从会计角度透析,基金是一个狭义的概念,意指具有特定目的和用途的资金。我们提到的基金主要是指证券投资基金。"}
#05 我的问题如下:
"""
{{此处替换成你上一步生成的问题}}
"""
#06 我的内容如下:
"""
{{此处替换成你的内容}}
"""
把上一步的生成的问题,粘贴到#05那块,再把原本的文章,粘贴到#06那块。
然后Uesr随便写一句“拼成问答对”,直接开跑。

一分钟,你的问答对就生成完了,直接扔到txt里,灌给Dify或者Langchain-ChatGLM啥的,都行~
你的知识库如果大的话,一次性肯定没法全扔进去,所以我们才需要开两个窗口,不断复制粘贴。
你也不用自己去费劲巴拉的自己写数据集了,你就是一个无情的复制粘贴机器。
希望用GPT处理数据集的方式,能给大家抛砖引玉。
让人人都提升效率,去做更有意思的事。
作者:数字生命卡兹克
链接:https://www.zhihu.com/question/606436913/answer/3129314758