ChatGLM2-6B 介绍
ChatGLM2-6B 在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,引入了如下新特性:
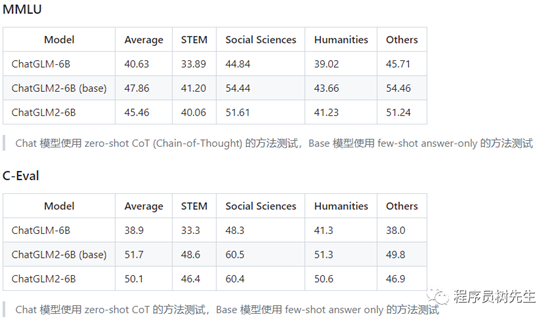
o• 更强大的性能:基于 ChatGLM 初代模型的开发经验,全面升级了基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B
在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
o• 更长的上下文:基于 FlashAttention 技术,将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。
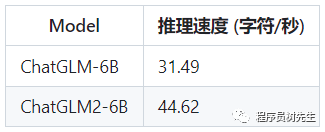
o• 更高效的推理:基于 Multi-Query
Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
o• 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。
相比于初代模型,ChatGLM2-6B 多个维度的能力都取得了提升,以下是一些官方对比示例。

总的来说,看起来效果还不错,下面跟着树先生一起来试试水~
本文我将分 3 步带着大家一起实操一遍,并与之前
ChatGLM-6B 进行对比。
o• ChatGLM2-6B 部署
o• ChatGLM2-6B 微调
o• LangChain + ChatGLM2-6B 构建个人专属知识库
ChatGLM2-6B 部署
这里我们还是白嫖阿里云的机器学习 PAI 平台,使用 A10 显卡,环境准备好了以后,就可以开始准备部署工作了。
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B
# 其中 transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能
pip install -r requirements.txt
# 这里我将下载的模型文件放到了本地的 chatglm-6b 目录下
git clone https://huggingface.co/THUDM/chatglm2-6b $PWD/chatglm2-6b
# 因为前面改了模型默认下载地址,所以这里需要改下路径参数
# 修改 web_demo.py 文件
tokenizer = AutoTokenizer.from_pretrained("/mnt/workspace/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/mnt/workspace/chatglm2-6b", trust_remote_code=True).cuda()
# 如果想要本地访问,需要修改此处
demo.queue().launch(share=True, inbrowser=True, server_name='0.0.0.0', server_port=7860)
官方推荐用 Streamlit 启动会更流程一些,但受限于 PAI
平台没有分配弹性公网,所以还是用老的 gradio 启动吧。
python web_demo.py
 img
img
ChatGLM2-6B 对比 ChatGLM-6B
先让 ChatGPT 作为考官,出几道题。
ChatGLM-6B 回答:

ChatGLM2-6B 回答:

明显可以看出,ChatGLM2-6B 相比于上一代模型响应速度更快,问题回答精确度更高,且拥有更长的(32K)上下文!
基于 P-Tuning 微调
ChatGLM2-6B
ChatGLM2-6B 环境已经有了,接下来开始模型微调,这里我们使用官方的 P-Tuning v2 对 ChatGLM2-6B 模型进行参数微调,P-Tuning v2 将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行。
# 运行微调需要 4.27.1 版本的 transformers
pip install transformers==4.27.1
pip install rouge_chinese nltk jieba datasets
# 禁用 W&B,如果不禁用可能会中断微调训练,以防万一,还是禁了吧
export WANDB_DISABLED=true
这里为了简化,我只准备了5条测试数据,分别保存为
train.json 和 dev.json,放到
ptuning 目录下,实际使用的时候肯定需要大量的训练数据。
{"content": "你好,你是谁",
"summary": "你好,我是树先生的助手小6。"}
{"content": "你是谁",
"summary": "你好,我是树先生的助手小6。"}
{"content": "树先生是谁",
"summary": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
{"content": "介绍下树先生",
"summary": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
{"content": "树先生",
"summary": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
修改 train.sh 和 evaluate.sh 中的 train_file、validation_file和test_file为你自己的 JSON 格式数据集路径,并将 prompt_column 和 response_column 改为
JSON 文件中输入文本和输出文本对应的 KEY。可能还需要增大 max_source_length 和 max_target_length 来匹配你自己的数据集中的最大输入输出长度。并将模型路径 THUDM/chatglm2-6b 改为你本地的模型路径。
1、train.sh 文件修改
PRE_SEQ_LEN=32
LR=2e-2
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_train \
--train_file train.json \
--validation_file dev.json \
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /mnt/workspace/chatglm2-6b \
--output_dir output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 128 \
--max_target_length 128 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
train.sh 中的 PRE_SEQ_LEN 和 LR 分别是
soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来改变原始模型的量化等级,不加此选项则为 FP16 精度加载。
2、evaluate.sh 文件修改
PRE_SEQ_LEN=32
CHECKPOINT=adgen-chatglm2-6b-pt-32-2e-2
STEP=3000
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_predict \
--validation_file dev.json \
--test_file dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path /mnt/workspace/chatglm2-6b \
--ptuning_checkpoint ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 128 \
--max_target_length 128 \
--per_device_eval_batch_size 1 \
--predict_with_generate \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
CHECKPOINT 实际就是 train.sh 中的 output_dir。
bash train.sh
5 条数据大概训练了 50 分钟左右。

bash evaluate.sh
执行完成后,会生成评测文件,评测指标为中文 Rouge score 和 BLEU-4。生成的结果保存在
./output/adgen-chatglm2-6b-pt-32-2e-2/generated_predictions.txt。我们准备了 5 条推理数据,所以相应的在文件中会有 5 条评测数据,labels 是 dev.json 中的预测输出,predict 是 ChatGLM2-6B 生成的结果,对比预测输出和生成结果,评测模型训练的好坏。如果不满意调整训练的参数再次进行训练。
{"labels": "你好,我是树先生的助手小6。", "predict": "你好,我是树先生的助手小6。"}
{"labels": "你好,我是树先生的助手小6。", "predict": "你好,我是树先生的助手小6。"}
{"labels": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。", "predict": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
{"labels": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。", "predict": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
{"labels": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。", "predict": "树先生是一个程序员,热衷于用技术探索商业价值,持续努力为粉丝带来价值输出,运营公众号《程序员树先生》。"}
这里我们先修改 web_demo.sh
的内容以符合实际情况,将 pre_seq_len 改成你训练时的实际值,将 THUDM/chatglm2-6b 改成本地的模型路径。
PRE_SEQ_LEN=32
CUDA_VISIBLE_DEVICES=0 python3 web_demo.py \
--model_name_or_path /mnt/workspace/chatglm2-6b \
--ptuning_checkpoint output/adgen-chatglm2-6b-pt-32-2e-2/checkpoint-3000 \
--pre_seq_len $PRE_SEQ_LEN
然后再执行。
bash web_demo.sh
原始模型
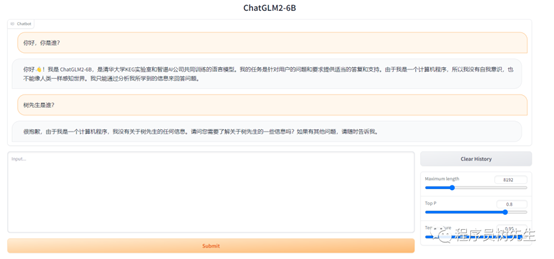
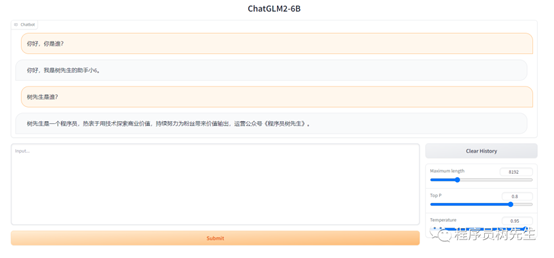
微调后模型
LangChain + ChatGLM2-6B 构建知识库
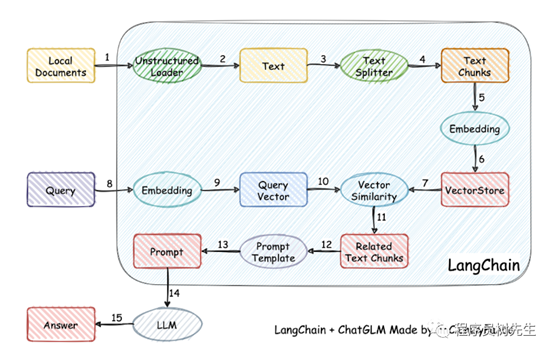
目前市面上绝大部分知识库都是
LangChain + LLM + embedding 这一套,实现原理如下图所示,过程包括加载文件
-> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个
-> 匹配出的文本作为上下文和问题一起添加到 prompt 中 -> 提交给 LLM 生成回答。
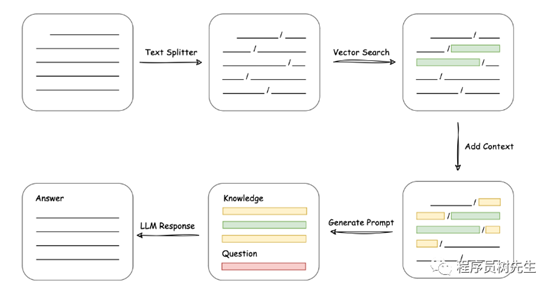
从上面就能看出,其核心技术就是向量 embedding,将用户知识库内容经过 embedding 存入向量知识库,然后用户每一次提问也会经过 embedding,利用向量相关性算法(例如余弦算法)找到最匹配的几个知识库片段,将这些知识库片段作为上下文,与用户问题一起作为 promt 提交给 LLM 回答,很好理解吧。一个典型的 prompt 模板如下:
"""
已知信息:
{context}
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。
问题是:{question}
"""
更多关于向量 embedding 的内容可以参考我之前写的一篇文章。
ChatGPT 引爆向量数据库赛道
下载源码
git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
安装依赖
cd langchain-ChatGLM
pip install -r requirements.txt
下载模型
# 安装 git lfs
git lfs install
# 下载 LLM 模型
git clone https://huggingface.co/THUDM/chatglm2-6b $PWD/chatglm2-6b
# 下载 Embedding 模型
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese $PWD/text2vec
# 模型需要更新时,可打开模型所在文件夹后拉取最新模型文件/代码
git pull
参数调整
模型下载完成后,请在 configs/model_config.py 文件中,对embedding_model_dict和llm_model_dict参数进行修改。
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec-base": "shibing624/text2vec-base-chinese",
"text2vec": "/mnt/workspace/text2vec",
"m3e-small": "moka-ai/m3e-small",
"m3e-base": "moka-ai/m3e-base",
}
llm_model_dict = {
...
"chatglm2-6b": {
"name": "chatglm2-6b",
"pretrained_model_name": "/mnt/workspace/chatglm2-6b",
"local_model_path": None,
"provides": "ChatGLM"
},
...
}
# LLM 名称改成 chatglm2-6b
LLM_MODEL = "chatglm2-6b"
Web 模式启动
python webui.py
如果报了这个错:

升级下 protobuf 即可。
pip install --upgrade protobuf==3.19.6
启动成功!

模型配置
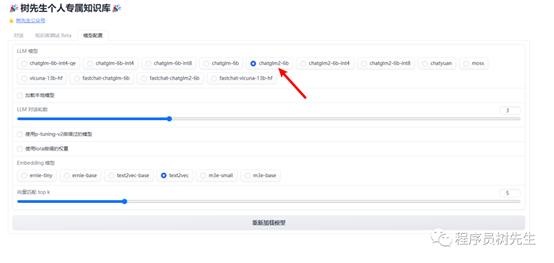
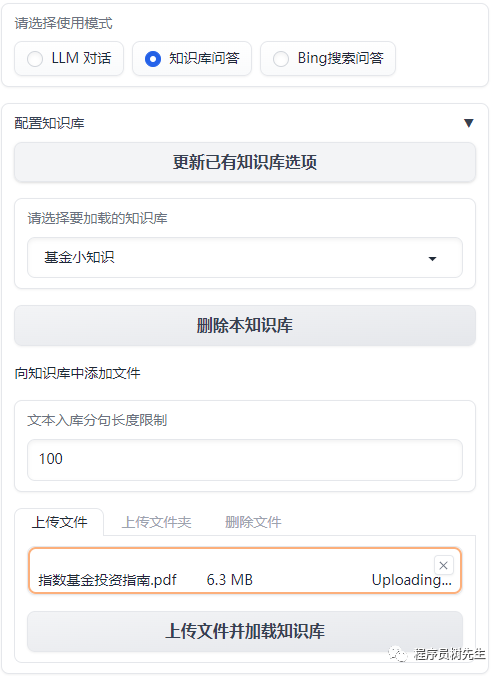
上传知识库
基于 ChatGLM2-6B 的知识库问答
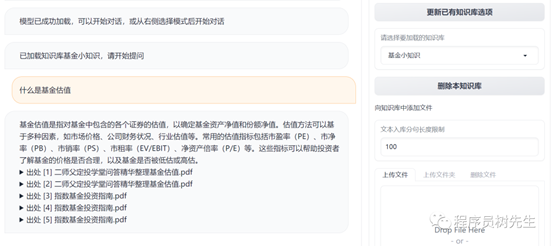
由于 LangChain 项目更新了接口,树先生之前开发的定制
UI 也同步更新进行了适配。
选择知识库
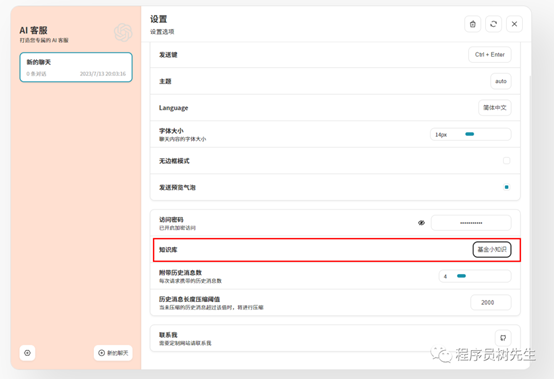
基于知识库问答
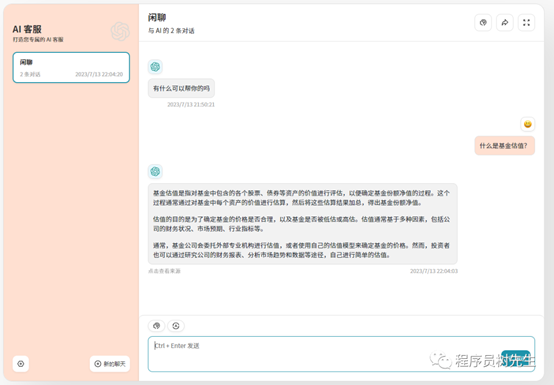
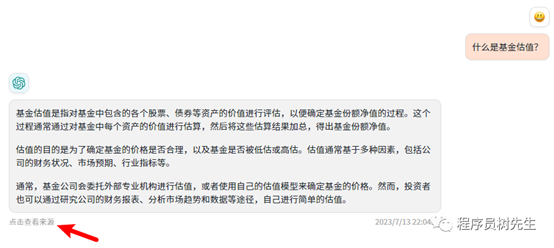
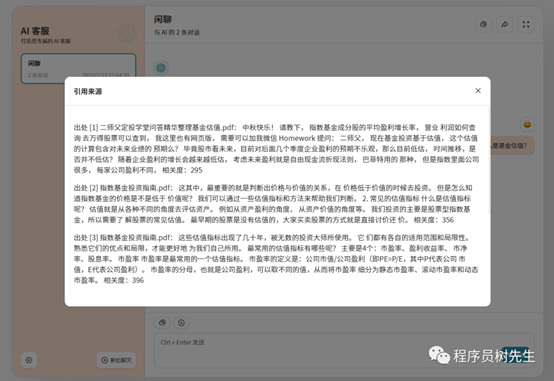
显示答案来源
 好了,这一篇还挺长的,不过很多内容之前文章中都有提到,相当于是一篇 LangChain + LLM + embedding 构建知识库的总结篇了,大家收藏好这一篇就行了
好了,这一篇还挺长的,不过很多内容之前文章中都有提到,相当于是一篇 LangChain + LLM + embedding 构建知识库的总结篇了,大家收藏好这一篇就行了
原文:https://mp.weixin.qq.com/s/FqehXo3u5zdhiAWVa-31lw