生成式AI领域拓展!MetaAI开源AudioCraft:一个支持AudioGen、MusicGen等模型的音频生成开发框架
在过去的几年里,我们看到了AI在图像、视频和文本生成方面的巨大进步。然而,音频生成领域的进展却相对滞后。MetaAI这次再为开源贡献重磅产品:AudioCraft,一个支持多个音频生成模型的音频生成开发框架。

·
AudioCraft简介
·
·
AudioCraft支持的模型
·
·
AudioCraft使用
·
·
AudioCraft开源地址
·
AudioCraft简介
产生高保真音频任何类型的音频都需要对不同尺度的复杂信号和模式进行建模。音乐可能是最具挑战性的音频类型,因为它由局部和长程模式组成,从一系列音符到具有多种乐器的全局音乐结构。利用AI生成连贯的音乐通常通过使用类似MIDI或钢琴卷的符号表示来实现。然而,这些方法无法完全捕捉到音乐中的表现细微差异和风格元素。
为此MetaAI开源了AudioCraft,一个可以用来生成音频的框架。它支持一系列的模型,能够产生高质量的音频,并具有长期的一致性,用户可以通过自然界面轻松地与其进行交互。
AudioCraft适用于音乐和声音生成以及压缩,所有这些都在同一个平台上进行。由于易于构建和重复使用,希望构建更好的声音生成器、压缩算法或音乐生成器的人可以在同一个代码库中完成所有操作,并在其他人已有基础上进一步发展。
AudioCraft支持的模型
AudioCraft由三个模型组成:MusicGen、AudioGen和EnCodec。MusicGen使用Meta拥有和特别许可的音乐进行训练,从文本输入生成音乐,而AudioGen则使用公开的音效进行训练,从文本输入生成音频。此外,还有改进版的EnCodec解码器,它可以生成更高质量的音乐,减少了人工制作的痕迹。
简单来说,MusicGen就是文本生成音乐的模型:https://www.datalearner.com/ai-models/pretrained-models/MusicGen
AudioGen就是文本生成任意音频的模型:https://www.datalearner.com/ai-models/pretrained-models/AudioGen
另外的EnCodec是指利用神经网络的实时、高保真音频编解码器。
下图是官方演示的AudioGen和MusicGen的实际案例:
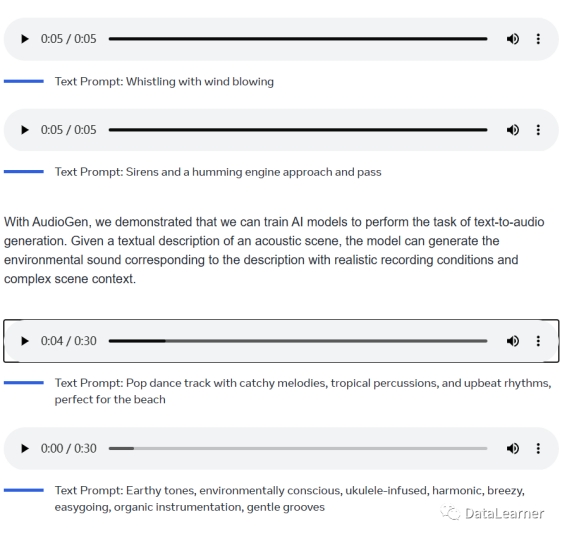
可以看到,对于AudioGen模型,只需要给一段文字即可生成音乐,第一个例子是让模型生成一段带有风声的口哨,结果很好。
注意,我这里是图片不能实际测试,大家可以去官方看真实效果。
而MusicGen模型则是一个描述即可生成音乐,虽然我不懂的,但是我觉得还挺好听的。
AudioCraft使用
AudioCraft依赖Python3.9和PyTorch2.0,所以需要先确保你的系统环境满足,可以通过如下命令安装升级:
1.
# Best to make sure you have torch installed first, in particular before installing xformers.
2.
3.
# Don't run this if you already have PyTorch installed.
4.
5.
pip install 'torch>=2.0'
6.
7.
# Then proceed to one of the following
8.
9.
pip install -U audiocraft # stable release
10.
11.
pip install -U git+https://git@github.com/facebookresearch/audiocraft#egg=audiocraft # bleeding edge
12.
13.
pip install -e .# or if you cloned the repo locally (mandatory if you want to train).
14.
官方也推荐在系统中安装ffmpeg:
1.
sudo apt-get install ffmpeg
2.
如果你有anaconda,也可以如下命令安装:
1.
conda install 'ffmpeg<5'-c conda-forge
2.
安装完之后使用很简单:
1.
import torchaudio
2.
3.
from audiocraft.models importAudioGen
4.
5.
from audiocraft.data.audio import audio_write
6.
7.
8.
9.
model =AudioGen.get_pretrained('facebook/audiogen-medium')
10.
11.
model.set_generation_params(duration=5)# generate 8 seconds.
12.
13.
wav = model.generate_unconditional(4)# generates 4 unconditional audio samples
14.
15.
descriptions =['dog barking','sirene of an emergency vehicule','footsteps in a corridor']
16.
17.
wav = model.generate(descriptions)# generates 3 samples.
18.
19.
20.
21.
for idx, one_wav in enumerate(wav):
22.
23.
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
24.
25.
audio_write(f'{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness", loudness_compressor=True)
26.
AudioCraft开源地址
开源地址:https://github.com/facebookresearch/audiocraft
注意,该框架开源,但是三个模型开源不可商用哦~~
AudioGen模型地址:https://www.datalearner.com/ai-models/pretrained-models/AudioGen
MusicGen模型地址:https://www.datalearner.com/ai-models/pretrained-models/MusicGen
出自:https://mp.weixin.qq.com/s/OLLCiMqKHQJxGGR1sPA3qw