Stable
Diffusion背后公司Stability AI又上新了。
这次带来的是图生3D方面的新进展:
基于Stable Video Diffusion的Stable Video 3D(SV3D),只用一张图片就能生成高质量3D网格。

Stable Video Diffusion(SVD)是Stability AI此前推出的高分辨率视频生成模型。也就是说,此番登场的SV3D首次将视频扩散模型应用到了3D生成领域。
官方表示,基于此,SV3D大大提高了3D生成的质量和视图一致性。

模型权重依然开源,不过仅可用于非商业用途,想要商用的话还得买个Stability AI会员~
话不多说,还是来扒一扒论文细节。
将视频扩散模型用于3D生成
引入潜在视频扩散模型,SV3D的核心目的是利用视频模型的时间一致性来提高3D生成的一致性。
并且视频数据本身也比3D数据更容易获得。
Stability AI这次提供两个版本的SV3D:
§
SV3D_u:基于单张图像生成轨道视频。
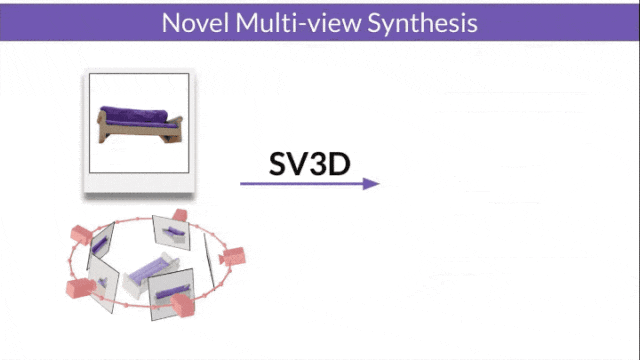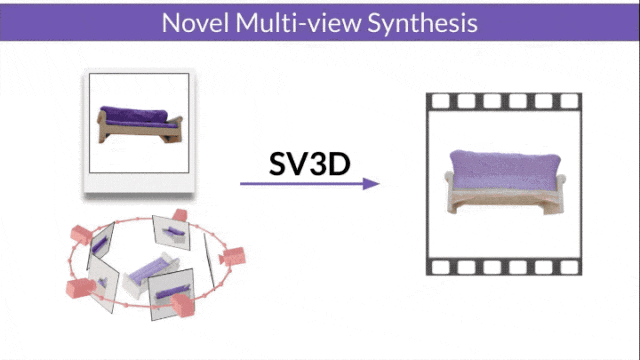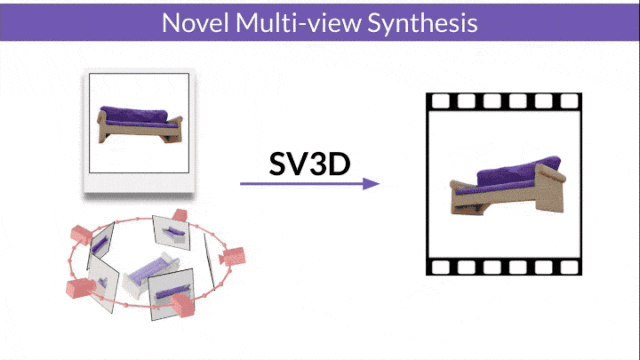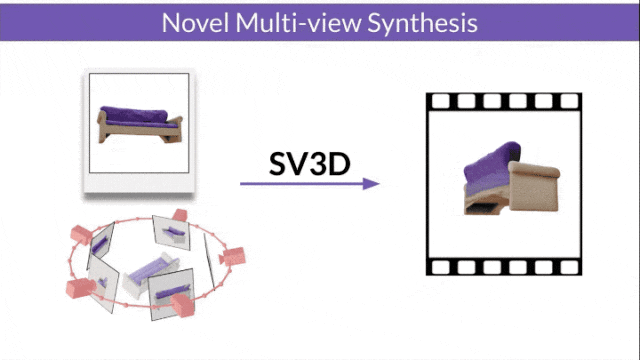
§
SV3D_p:扩展了SV3D_u的功能,可以根据指定的相机路径创建3D模型视频。
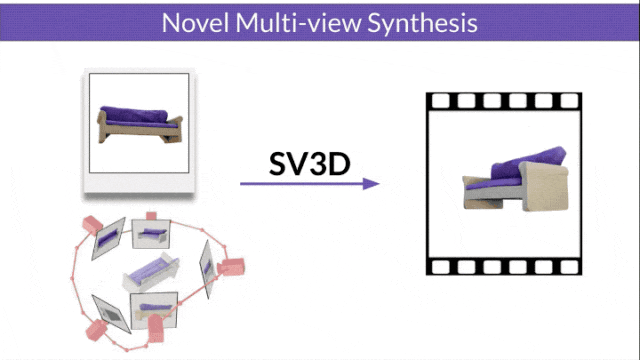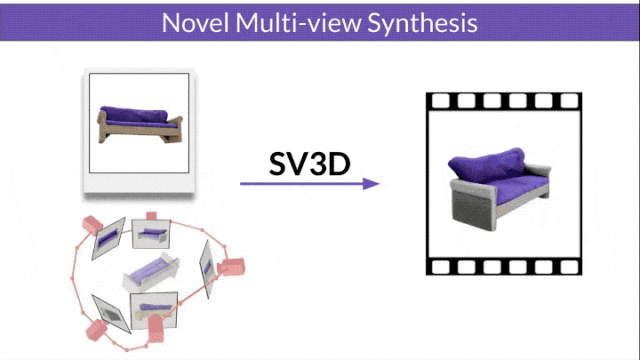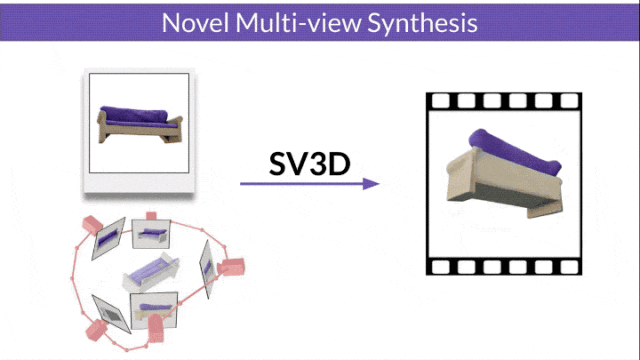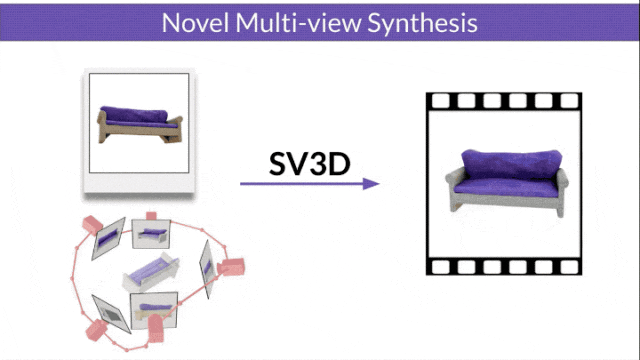
研究人员还改进了3D优化技术:采用由粗到细的训练策略,优化NeRF和DMTet网格来生成3D对象。
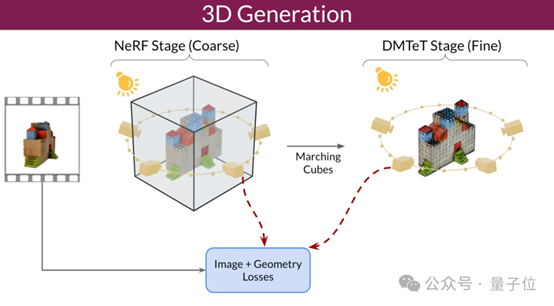
他们还设计了一种名为掩码得分蒸馏采样(SDS)的特殊损失函数,通过优化在训练数据中不直接可见的区域,来提高生成3D模型的质量和一致性。
同时,SV3D引入了一个基于球面高斯的照明模型,用于分离光照效果和纹理,在保持纹理清晰度的同时有效减少了内置照明问题。
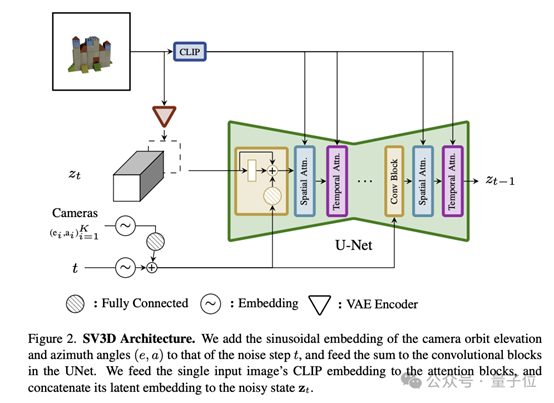
具体到架构方面,SV3D包含以下关键组成部分:
§ UNet:SV3D是在SVD的基础上构建的,包含一个多层UNet,其中每一层都有一系列残差块(包括3D卷积层)和两个分别处理空间和时间信息的Transformer模块。
§ 条件输入:输入图像通过VAE编码器嵌入到潜在空间中,会和噪声潜在状态合并,一起输入到UNet中;输入图像的CLIP嵌入矩阵则被用作每个Transformer模块交叉注意力层的键值对。
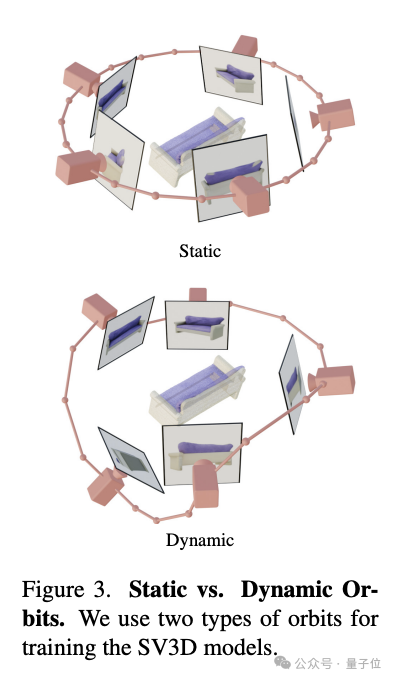
§ 相机轨迹编码:SV3D设计了静态和动态两种类型的轨道来研究相机姿态条件的影响。静态轨道中,相机以规律间隔的方位角围绕对象;动态轨道则允许不规则间隔的方位角和不同的仰角。
相机的运动轨迹信息和扩散噪声的时间信息会一起输入到残差模块中,转换为正弦位置嵌入,然后这些嵌入信息会被整合并进行线性变换,加入到噪声时间步长嵌入中。
这样的设计旨在通过精细控制相机轨迹和噪声输入,提升模型处理图像的能力。
此外,SV3D在生成过程中采用CFG(无分类器引导)来控制生成的清晰度,特别是在生成轨道的最后几帧时,采用三角形CFG缩放来避免过度锐化。
研究人员在Objaverse数据集上训练SV3D,图像分辨率为575×576,视场角为33.8度。论文透露,所有三种模型(SV3D_u,SV3D_c,SV3D_p)在4个节点上训练了6天左右,每个节点配备8个80GB的A100 GPU。
实验结果
在新视角合成(NVS)和3D重建方面,SV3D超过了现有其他方法,达到SOTA。
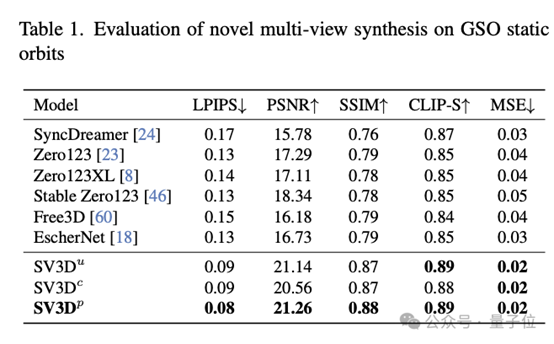
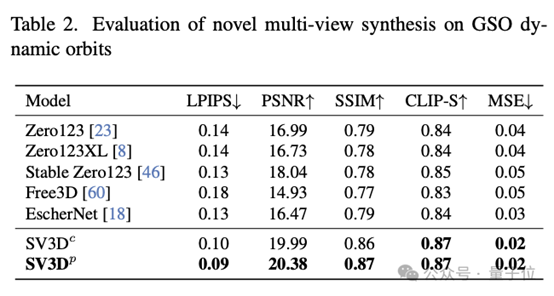
从定性比较的结果来看,SV3D生成的多视角试图,细节更丰富,更接近与原始输入图像。也就是说,SV3D在理解和重构物体的3D结构方面,能够更准确地捕捉到细节,并保持视角变换时的一致性。

这样的成果,引发了不少网友的感慨:
可以想象,在未来6-12个月内,3D生成技术将会被用到游戏和视频项目中。
评论区也总少不了一些大胆的想法……
并且项目开源嘛,已经有第一波小伙伴玩上了,在4090上就能跑起来。

如果你也有第一手实测体会,欢迎在评论区分享~

参考链接:
[1]https://twitter.com/StabilityAI/status/1769817136799855098
[2]https://stability.ai/news/introducing-stable-video-3d
[3]https://sv3d.github.io/index.html
来源:https://mp.weixin.qq.com/s/rlZN4xwRsPRhkriJCeo0hw