¸ة»ُش¤¾¯£؛صâ؟ةؤـتاؤمؤـ¹»صزµ½µؤ×îبفز׶®µؤ£¬×îحêصûµؤ£¬تتسأسع¸÷ضضNLPبخخٌµؤ؟ھش´LLMµؤfinetune½ج³ج~
ChatGLM2-6bتااه»ھ؟ھش´µؤذ،³ك´çLLM£¬ض»ذèزھز»؟éئصح¨µؤدش؟¨(32G½دخبح×)¼´؟ةحئہي؛حخ¢µ÷£¬تاؤ؟ا°ةçاّ·ا³£»îش¾µؤز»¸ِ؟ھش´LLM،£
±¾·¶ہت¹سأ·ا³£¼ٍµ¥µؤ£¬حâآôئہآغت¾ف¼¯ہ´تµت©خ¢µ÷£¬بأChatGLM2-6bہ´¶شز»¶خحâآôئہآغاّ·ضتا؛أئہ»¹تا²îئہ،£
؟ةزش·¢دض£¬¾¹خ¢µ÷؛َµؤؤ£ذح£¬دà±بض±½س 3-shot-prompt ؟ةزشب،µأأ÷دش¸ü؛أµؤذ§¹û،£
ضµµأ×¢زâµؤتا£¬¾،¹ـخزأازشخؤ±¾·ضہàبخخٌخھہ£¬تµ¼تةد£¬بخ؛خNLPبخخٌ£¬ہب磬أüأûتµجهت¶±ً£¬·ز룬ءؤجى¶ش»°µبµب£¬¶¼؟ةزشح¨¹¼سةد؛دتتµؤةددآخؤ£¬×ھ»»³ةز»¸ِ¶ش»°ختج⣬²¢صë¶شخزأاµؤت¹سأ³،¾°£¬ةè¼ئ³ِ؛دتتµؤت¾ف¼¯ہ´خ¢µ÷؟ھش´LLM.
¹«ضع؛إثم·¨أہت³خف؛َج¨»ط¸´¹ط¼ü´ت£؛torchkeras£¬»ٌب،±¾خؤnotebookش´´ْآ룬زش¼°waimaiت¾ف¼¯دآشطء´½س~
©–£¬ش¤رµء·ؤ£ذح
خزأاذèزھ´س https://huggingface.co/THUDM/chatglm2-6b دآشطchatglm2µؤؤ£ذح،£
¹ْؤع؟ةؤـثظ¶ب»ل±ب½دآ£¬×ـ¹²سذ14¶à¸ِG£¬حّثظ²»ج«؛أµؤ»°£¬´َ¸إ؟ةؤـذèزھز»ء½¸ِذ،ت±،£
بç¹ûحّآç²»خب¶¨£¬ز²؟ةزشتض¶¯´سصâ¸ِز³أوز»¸ِز»¸ِدآشطب«²؟خؤ¼ب»؛َ·إضأµ½ ز»¸ِخؤ¼¼ذضذہبç 'chatglm2-6b' زش±م¶ءب،،£
from transformers import AutoModel,AutoTokenizer
model_name = "chatglm2-6b" #»ٍصكش¶³ج ،°THUDM/chatglm2-6b،±
tokenizer = AutoTokenizer.from_pretrained(
model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name,trust_remote_code=True).half().cuda()
Loading checkpoint shards: 0%| | 0/7 [00:00<?, ?it/s]
prompt = """خؤ±¾·ضہàبخخٌ£؛½«ز»¶خسأ»§¸ّحâآô·خٌµؤئہآغ½ّذذ·ضہ࣬·ض³ة؛أئہ»ٍصك²îئہ،£
دآأوتاز»ذ©·¶ہ:
خ¶µہصو²»´ي -> ؛أئہ
ج«ہ±ءث£¬³ش²»دآ¶¼ -> ²îئہ
اë¶شدآتِئہآغ½ّذذ·ضہà،£·µ»ط'؛أئہ'»ٍصك'²îئہ'£¬خقذèئنثüثµأ÷؛ح½âتح،£
xxxxxx ->
"""
def get_prompt(text):
return prompt.replace('xxxxxx',text)
response, his = model.chat(tokenizer, get_prompt('خ¶µہ²»´ي£¬دآ´خ»¹ہ´'), history=[])
print(response)
؛أئہ
#شِ¼س4¸ِ·¶ہ
his.append(("ج«¹َءث -> ","²îئہ"))
his.append(("·ا³£؟ى£¬خ¶µہ؛أ -> ","؛أئہ"))
his.append(("صâأ´دجصوµؤتا×يءث -> ","²îئہ"))
his.append(("¼غ¸ٌ¸ذبث سإ»ف¶à¶à -> ","؛أئہ"))
خزأاہ´²âتشز»دآ
response, history = model.chat(tokenizer, "ز»رشؤر¾،°، -> ", history=his)
print(response)
response, history = model.chat(tokenizer, "»¹´ص؛دز»°م°م -> ", history=his)
print(response)
response, history = model.chat(tokenizer, "خز¼ز¹·¹·°®³شµؤ -> ", history=his)
print(response)
²îئہ
²îئہ
؛أئہ
#·â×°³ةز»¸ِ؛¯ت°ة~
def predict(text):
response, history = model.chat(tokenizer, f"{text} ->", history=his,
temperature=0.01)
return response
predict('ثہ¹ي£¬ص¦إھµأصâأ´سذ×جخ¶ؤط') #شعخزأا¾«ذؤةè¼ئµؤز»¸ِئہآغدآ£¬ChatGLM2-6bضصسعش¤²â´يخَءث~
'²îئہ'
خزأاؤأحâآôت¾ف¼¯²âتشز»دآخ´¾خ¢µ÷£¬´؟´âµؤ 6-shot prompt µؤ×¼ب·آت،£
import pandas as pd
import numpy as np
import datasets
df = pd.read_csv("data/waimai_10k.csv")
df['tag'] = df['label'].map({0:'²îئہ',1:'؛أئہ'})
df = df.rename({'review':'text'},axis = 1)
dfgood = df.query('tag=="؛أئہ"')
dfbad = df.query('tag=="²îئہ"').head(len(dfgood)) #²ةرù²؟·ض²îئہ£¬بأ؛أئہ²îئہئ½؛â
df = pd.concat([dfgood,dfbad])
print(df['tag'].value_counts())
؛أئہ 4000
²îئہ 4000
ds_dic = datasets.Dataset.from_pandas(df).train_test_split(
test_size = 2000,shuffle=True, seed = 43)
dftrain = ds_dic['train'].to_pandas()
dftest = ds_dic['test'].to_pandas()
dftrain.to_parquet('data/dftrain.parquet')
dftest.to_parquet('data/dftest.parquet')
preds = ['' for x in dftest['tag']]
from tqdm import tqdm
for i in tqdm(range(len(dftest))):
text = dftest['text'].loc[i]
preds[i] = predict(text)
dftest['pred'] = preds
dftest.pivot_table(index='tag',columns = 'pred',values='text',aggfunc='count')
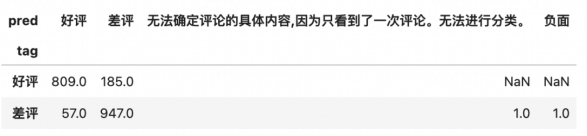
acc = len(dftest.query('tag==pred'))/len(dftest)
print('acc=',acc)
acc= 0.878
؟ةزش؟´µ½£¬خ¢µ÷ض®ا°£¬خزأاµؤؤ£ذح×¼ب·آتخھ87.8%£¬دآأوخزأاح¨¹6000جُ×َسزت¾فµؤخ¢µ÷£¬؟´؟´ؤـ·ٌ°رacc´ٍةدب¥~ ���
ز»£¬×¼±¸ت¾ف
خزأاذèزھ°رت¾فصûہي³ة¶ش»°µؤذخت½£¬¼´ context ؛ح target µؤإن¶ش£¬ب»؛َئ´µ½ز»ئً×÷خھز»جُرù±¾،£
ChatGLMؤ£ذح±¾ضتةد×ِµؤتاز»¸ِخؤ×ض½سءْµؤسخد·£¬¼´¸ّ¶¨ز»¶خ»°µؤةد°ë²؟·ض£¬ثü»لب¥ذّذ´دآ°ë²؟·ض،£
خزأاصâہïض¸¶¨ةد°ë²؟·ضخھخزأاةè¼ئµؤخؤ±¾·ضہàبخخٌµؤprompt£¬دآ°ë²؟·ضخھخؤ±¾·ضہà½ل¹û،£
ثùزشخزأاخ¢µ÷µؤؤ؟±ê¾حتابأثüش¤²âµؤدآ°ë²؟·ض¸ْخزأاµؤة趨µؤخؤ±¾·ضہàز»ضآ،£
1£¬ت¾ف¼سشط
import pandas as pd
import numpy as np
import datasets
dftrain = pd.read_parquet('data/dftrain.parquet')
dftest = pd.read_parquet('data/dftest.parquet')
dftrain['tag'].value_counts()
؛أئہ 3006
²îئہ 2994
Name: tag, dtype: int64
#½«ةددآخؤصûہي³ةسëحئہيت±؛ٍز»ضآ£¬²خصصmodel.chatضذµؤش´آë~
#model.build_inputs??
def build_inputs(query, history):
prompt = ""
for i, (old_query, response) in enumerate(history):
prompt += "[Round {}]\n\nخت£؛{}\n\n´ً£؛{}\n\n".format(i + 1, old_query, response)
prompt += "[Round {}]\n\nخت£؛{} -> \n\n´ً£؛".format(len(history) + 1, query)
return prompt
print(build_inputs('خ¶µہ²»ج«ذذ',history=his))
[Round 1]
خت£؛خؤ±¾·ضہàبخخٌ£؛½«ز»¶خسأ»§¸ّحâآô·خٌµؤئہآغ½ّذذ·ضہ࣬·ض³ة؛أئہ»ٍصك²îئہ،£
دآأوتاز»ذ©·¶ہ:
خ¶µہصو²»´ي -> ؛أئہ
ج«ہ±ءث£¬³ش²»دآ¶¼ -> ²îئہ
اë¶شدآتِئہآغ½ّذذ·ضہà،£·µ»ط'؛أئہ'»ٍصك'²îئہ'£¬خقذèئنثüثµأ÷؛ح½âتح،£
خ¶µہ²»´ي£¬دآ´خ»¹ہ´ ->
´ً£؛؛أئہ
[Round 2]
خت£؛ج«¹َءث ->
´ً£؛²îئہ
[Round 3]
خت£؛·ا³£؟ى£¬خ¶µہ؛أ ->
´ً£؛؛أئہ
[Round 4]
خت£؛صâأ´دجصوµؤتا×يءث ->
´ً£؛²îئہ
[Round 5]
خت£؛¼غ¸ٌ¸ذبث سإ»ف¶à¶à ->
´ً£؛؛أئہ
[Round 6]
خت£؛خ¶µہ²»ج«ذذ ->
´ً£؛
dftrain['context'] = [build_inputs(x,history=his) for x in dftrain['text']]
dftrain['target'] = [x for x in dftrain['tag']]
dftrain = dftrain[['context','target']]
dftest['context'] = [build_inputs(x,history=his) for x in dftest['text']]
dftest['target'] = [x for x in dftest['tag']]
dftest = dftest[['context','target']]
dftest
ds_train = datasets.Dataset.from_pandas(dftrain)
ds_val = datasets.Dataset.from_pandas(dftest)
2£¬token±àآë
خھءث½«خؤ±¾ت¾فخ¹بëؤ£ذح£¬ذèزھ½«´ت×ھ»»خھtoken،£
ز²¾حتا°رcontext×ھ»¯³ةcontext_ids£¬°رtarget×ھ»¯³ةtarget_ids.
ح¬ت±£¬خزأا»¹ذèزھ½«context_ids؛حtarget_idsئ´½سµ½ز»ئً×÷خھؤ£ذحµؤinput_ids،£
صâتاخھت²أ´ؤط£؟
زٍخھChatGLM2»ù×ùؤ£ذحتاز»¸ِTransformerDecoder½ل¹¹£¬تاز»¸ِ±»ش¤ر،ء·¹µؤ´؟´âµؤسïرشؤ£ذح(LLM£¬Large Lauguage Model)،£
ز»¸ِ´؟´âµؤسïرشؤ£ذح£¬±¾ضتةدض»ؤـ×ِز»¼تآا飬ؤا¾حتا¼ئثمبخزâز»¶خ»°دٌ'بث»°'µؤ¸إآت،£
خزأا½«context؛حtargetئ´½سµ½ز»ئً×÷خھinput_ids£¬ ChatGLM2 ¾ح؟ةزشإذ¶دصâ¶خ¶ش»°دٌ'بثہà¶ش»°'µؤ¸إآت،£
شعرµء·µؤت±؛ٍخزأات¹سأجف¶بدآ½µµؤ·½·¨ہ´بأChatGLM2µؤإذ¶د¸ü¼س×¼ب·،£
رµء·حê³ةض®؛َ£¬شعش¤²âµؤت±؛ٍ£¬خزأا¾ح؟ةزشہûسأج°ذؤثرث÷»ٍصكتّثرث÷µؤ·½·¨°´صص×îدٌ"بثہà¶ش»°"µؤ·½ت½½ّذذ¸ü؛دہيµؤخؤ±¾ةْ³ة،£
from tqdm import tqdm
import transformers
model_name = "chatglm2-6b"
max_seq_length = 512
skip_over_length = True
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_name, trust_remote_code=True)
config = transformers.AutoConfig.from_pretrained(
model_name, trust_remote_code=True, device_map='auto')
def preprocess(example):
context = example["context"]
target = example["target"]
context_ids = tokenizer.encode(
context,
max_length=max_seq_length,
truncation=True)
target_ids = tokenizer.encode(
target,
max_length=max_seq_length,
truncation=True,
add_special_tokens=False)
input_ids = context_ids + target_ids + [config.eos_token_id]
return {"input_ids": input_ids, "context_len": len(context_ids),'target_len':len(target_ids)}
ds_train_token = ds_train.map(preprocess).select_columns(['input_ids', 'context_len','target_len'])
if skip_over_length:
ds_train_token = ds_train_token.filter(
lambda example: example["context_len"]<max_seq_length and example["target_len"]<max_seq_length)
ds_val_token = ds_val.map(preprocess).select_columns(['input_ids', 'context_len','target_len'])
if skip_over_length:
ds_val_token = ds_val_token.filter(
lambda example: example["context_len"]<max_seq_length and example["target_len"]<max_seq_length)
3, ¹ـµہ¹¹½¨
def data_collator(features: list):
len_ids = [len(feature["input_ids"]) for feature in features]
longest = max(len_ids) #ض®؛َ°´صصbatchضذ×µؤinput_ids½ّذذpadding
input_ids = []
labels_list = []
for length, feature in sorted(zip(len_ids, features), key=lambda x: -x[0]):
ids = feature["input_ids"]
context_len = feature["context_len"]
labels = (
[-100] * (context_len - 1) + ids[(context_len - 1) :] + [-100] * (longest - length)
) #-100±êض¾خ»؛َأو»لشع¼ئثمlossت±»ل±»؛ِآش²»¹±د×ثًت§£¬خزأا¼¯ضذسإ»¯target²؟·ضةْ³ةµؤloss
ids = ids + [tokenizer.pad_token_id] * (longest - length)
input_ids.append(torch.LongTensor(ids))
labels_list.append(torch.LongTensor(labels))
input_ids = torch.stack(input_ids)
labels = torch.stack(labels_list)
return {
"input_ids": input_ids,
"labels": labels,
}
import torch
dl_train = torch.utils.data.DataLoader(ds_train_token,num_workers=2,batch_size=4,
pin_memory=True,shuffle=True,
collate_fn = data_collator)
dl_val = torch.utils.data.DataLoader(ds_val_token,num_workers=2,batch_size=4,
pin_memory=True,shuffle=True,
collate_fn = data_collator)
for batch in dl_train:
break
dl_train.size = 300 #أ؟300¸ِstepتس×÷ز»¸ِepoch£¬×ِز»´خرéض¤
¶£¬¶¨زهؤ£ذح
import warnings
warnings.filterwarnings("ignore")
from transformers import AutoTokenizer, AutoModel, TrainingArguments, AutoConfig
import torch
import torch.nn as nn
from peft import get_peft_model, LoraConfig, TaskType
model = AutoModel.from_pretrained("chatglm2-6b",
load_in_8bit=False,
trust_remote_code=True,
device_map='auto')
model.supports_gradient_checkpointing = True #½عش¼cuda
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
#model.lm_head = CastOutputToFloat(model.lm_head)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, inference_mode=False,
r=8,
lora_alpha=32, lora_dropout=0.1,
)
model = get_peft_model(model, peft_config)
model.is_parallelizable = True
model.model_parallel = True
model.print_trainable_parameters()

؟ةزش؟´µ½£¬ح¨¹ت¹سأLoRAخ¢µ÷·½·¨£¬´رµء·²ختض»سذب«²؟²ختµؤ3%×َسز،£
ب£¬رµء·ؤ£ذح
خزأات¹سأخزأاµؤأخضذاéآ¯torchkerasہ´تµدض×îسإرإµؤرµء·ر»·~
×¢زâصâہخھءث¸ü¼س¸كذ§µط±£´و؛ح¼سشط²خت£¬خزأا¸²¸اءثKerasModelضذµؤload_ckpt؛حsave_ckpt·½·¨£¬
½ِ½ِ±£´و؛ح¼سشطloraب¨ضط£¬صâرù؟ةزش±ـأâ¼سشط؛ح±£´وب«²؟ؤ£ذحب¨ضطشى³ةµؤ´و´¢ختجâ،£
from torchkeras import KerasModel
from accelerate import Accelerator
class StepRunner:
def __init__(self, net, loss_fn, accelerator=None, stage = "train", metrics_dict = None,
optimizer = None, lr_scheduler = None
):
self.net,self.loss_fn,self.metrics_dict,self.stage = net,loss_fn,metrics_dict,stage
self.optimizer,self.lr_scheduler = optimizer,lr_scheduler
self.accelerator = accelerator if accelerator is not None else Accelerator()
if self.stage=='train':
self.net.train()
else:
self.net.eval()
def __call__(self, batch):
#loss
with self.accelerator.autocast():
loss = self.net(input_ids=batch["input_ids"],labels=batch["labels"]).loss
#backward()
if self.optimizer is not None and self.stage=="train":
self.accelerator.backward(loss)
if self.accelerator.sync_gradients:
self.accelerator.clip_grad_norm_(self.net.parameters(), 1.0)
self.optimizer.step()
if self.lr_scheduler is not None:
self.lr_scheduler.step()
self.optimizer.zero_grad()
all_loss = self.accelerator.gather(loss).sum()
#losses (or plain metrics that can be averaged)
step_losses = {self.stage+"_loss":all_loss.item()}
#metrics (stateful metrics)
step_metrics = {}
if self.stage=="train":
if self.optimizer is not None:
step_metrics['lr'] = self.optimizer.state_dict()['param_groups'][0]['lr']
else:
step_metrics['lr'] = 0.0
return step_losses,step_metrics
KerasModel.StepRunner = StepRunner
#½ِ½ِ±£´وlora؟ةرµء·²خت
def save_ckpt(self, ckpt_path='checkpoint.pt', accelerator = None):
unwrap_net = accelerator.unwrap_model(self.net)
unwrap_net.save_pretrained(ckpt_path)
def load_ckpt(self, ckpt_path='checkpoint.pt'):
self.net = self.net.from_pretrained(self.net,ckpt_path)
self.from_scratch = False
KerasModel.save_ckpt = save_ckpt
KerasModel.load_ckpt = load_ckpt
keras_model = KerasModel(model,loss_fn = None,
optimizer=torch.optim.AdamW(model.parameters(),lr=2e-6))
ckpt_path = 'waimai_chatglm4'
keras_model.fit(train_data = dl_train,
val_data = dl_val,
epochs=100,patience=5,
monitor='val_loss',mode='min',
ckpt_path = ckpt_path,
mixed_precision='fp16'
)
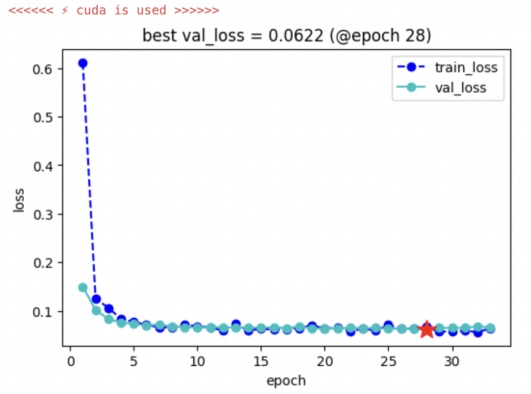
اْدكدآ½µ·ا³£سإأہ~������
ثؤ£¬رéض¤ؤ£ذح
from peft import PeftModel
model = AutoModel.from_pretrained("chatglm2-6b",
load_in_8bit=False,
trust_remote_code=True,
device_map='auto')
model = PeftModel.from_pretrained(model,ckpt_path)
model = model.merge_and_unload() #؛د²¢loraب¨ضط
def predict(text):
response, history = model.chat(tokenizer, f"{text} -> ", history=his,
temperature=0.01)
return response
predict('ثہ¹ي£¬ص¦إھµأصâأ´سذ×جخ¶ؤط')
'²îئہ'
dftest = pd.read_parquet('data/dftest.parquet')
preds = ['' for x in dftest['text']]
from tqdm import tqdm
for i in tqdm(range(len(dftest))):
text = dftest['text'].loc[i]
preds[i] = predict(text)
100%|¨€¨€¨€¨€¨€¨€¨€¨€¨€¨€| 2000/2000 [03:39<00:00, 9.11it/s]
dftest['pred'] = preds
dftest.pivot_table(index='tag',columns = 'pred',values='text',aggfunc='count')
acc = len(dftest.query('tag==pred'))/len(dftest)
print('acc=',acc)
acc= 0.903
���»¹ذذ£¬سأ6000جُت¾ف£¬رµء·ءثز»¸ِذ،ت±×َسز£¬×¼ب·آتµ½ءث90.3%£¬±بخ´¾خ¢µ÷µؤprompt·½°¸µؤ87.8%دà±بصاءثء½¸ِ¶àµم~
خه£¬ت¹سأؤ£ذح
خزأا؟ةزشµ÷صûخآ¶بtemperature²خت£¬؟´؟´سذأ»سذ»ْ»ل°رصâ¸ِئہآغ
'ثہ¹ي£¬ص¦إھµأصâأ´سذ×جخ¶ؤط' ش¤²âصب·
def predict(text,temperature=0.8):
response, history = model.chat(tokenizer, f"{text} -> ", history=his,
temperature=temperature)
return response
for i in range(10):
print(predict('ثہ¹ي£¬ص¦إھµأصâأ´سذ×جخ¶ؤط'))
²îئہ
؛أئہ
؛أئہ
؛أئہ
²îئہ
²îئہ
؛أئہ
²îئہ
²îئہ
؛أئہ
؟ةزش؟´µ½£¬صâ¸ِئہآغؤ£ذحئنتµتا²»ج«³شµأ×¼ثüتا؛أئہ»¹تا²îئہµؤ£¬±د¾¹£¬ثہ¹يصâ¸ِ´تµؤؤع؛ج«·ل¸»ءث£¬¸ْ×ضأوµؤزâث¼²¢²»ز»رù������
خزأا²âتشز»دآؤ£ذحµؤئنثû³،¾°¶ش»°ؤـء¦تا·ٌتـµ½س°دى£؟
response, history = model.chat(tokenizer, "إـ²½±ببüبç¹ûؤم³¬¹ءثµع¶أû£¬ؤم»ل³ةخھµع¼¸أû£؟", history=[])
print(response)
بç¹ûشعإـ²½±ببüضذ³¬¹ءثµع¶أû,ؤاأ´دضشع¾حتاµع¶أû،£بç¹ûدëزھضھµہدضشعإإأûµع¼¸,ذèزھضھµہ×ش¼؛؛حئنثûبثµؤ³ة¼¨،£بç¹ûضھµہءثثùسذبثµؤ³ة¼¨,¾ح؟ةزش¼ئثم³ِ×ش¼؛شعثùسذر،تضضذµؤإإأû،£
ءù£¬±£´وؤ£ذح
؟ةزش½«ؤ£ذح؛حtokenizer¶¼±£´وµ½ز»¸ِذآµؤآ·¾¶£¬±مسعض±½س¼سشط،£
model.save_pretrained("chatglm2-6b-waimai", max_shard_size='1GB')
tokenizer.save_pretrained("chatglm2-6b-waimai")
('chatglm2-6b-waimai/tokenizer_config.json',
'chatglm2-6b-waimai/special_tokens_map.json',
'chatglm2-6b-waimai/tokenizer.model',
'chatglm2-6b-waimai/added_tokens.json')
»¹ذèزھ½«دà¹طµؤpyخؤ¼ز²¸´ضئ¹ب¥،£
!ls chatglm2-6b
!cp chatglm2-6b/*.py chatglm2-6b-waimai/
!ls chatglm2-6b-waimai
from transformers import AutoModel,AutoTokenizer
model_name = "chatglm2-6b-waimai"
tokenizer = AutoTokenizer.from_pretrained(
model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name,
trust_remote_code=True).half().cuda()
prompt = """خؤ±¾·ضہàبخخٌ£؛½«ز»¶خسأ»§¸ّحâآô·خٌµؤئہآغ½ّذذ·ضہ࣬·ض³ة؛أئہ»ٍصك²îئہ،£
دآأوتاز»ذ©·¶ہ:
خ¶µہصو²»´ي -> ؛أئہ
ج«ہ±ءث£¬³ش²»دآ¶¼ -> ²îئہ
اë¶شدآتِئہآغ½ّذذ·ضہà،£·µ»ط'؛أئہ'»ٍصك'²îئہ'£¬خقذèئنثüثµأ÷؛ح½âتح،£
xxxxxx ->
"""
def get_prompt(text):
return prompt.replace('xxxxxx',text)
response, his = model.chat(tokenizer, get_prompt('¹·×س£¬شُأ´×ِµؤصâأ´؛أ³شر½£؟'), history=[])
print(response)
؛أئہ
تص¹¤،£
³ِ×ش£؛https://mp.weixin.qq.com/s/Lf70i8M0KNDs9ZB8H32h4w