ا°·½¸ة»ُش¤¾¯£؛صâ؟ةؤـتاؤمذؤذؤؤîؤîدëصزµؤ×î؛أ¶®×î¾كتµ²ظذشµؤlangchain½ج³ج،£±¾خؤح¨¹رفت¾9¸ِ¾كسذ´ْ±يذشµؤس¦سأ·¶ہ£¬´ّؤمءم»ù´،بëأإlangchain،£
±¾خؤnotebookش´آë£؛
https://github.com/lyhue1991/eat_chatgpt/blob/main/3_langchain_9_usecases.ipynbgithub.com/lyhue1991/eat_chatgpt/blob/main/3_langchain_9_usecases.ipynb
9¸ِ·¶ہ¹¦ؤـءذ±يبçدآ£؛
1£¬خؤ±¾×ـ½ل(Summarization): ¶شخؤ±¾/ءؤجىؤعبفµؤضطµمؤعبف×ـ½ل،£
2£¬خؤµµخت´ً(Question and Answering Over
Documents): ت¹سأخؤµµ×÷خھةددآخؤذإد¢£¬»ùسعخؤµµؤعبف½ّذذخت´ً،£
3£¬ذإد¢³éب،(Extraction): ´سخؤ±¾ؤعبفضذ³éب،½ل¹¹»¯µؤؤعبف،£
4£¬½ل¹ûئہ¹ہ(Evaluation): ·ضخِ²¢ئہ¹ہLLMتن³ِµؤ½ل¹ûµؤ؛أ»µ،£
5£¬ت¾ف؟âخت´ً(Querying Tabular Data): ´ست¾ف؟â/ہàت¾ف؟âؤعبفضذ³éب،ت¾فذإد¢،£
6£¬´ْآëہي½â(Code Understanding): ·ضخِ´ْآ룬²¢´س´ْآëضذ»ٌب،آك¼£¬ح¬ت±ز²ض§³ضQA،£
7£¬API½»»¥(Interacting
with APIs): ح¨¹¶شAPIخؤµµµؤشؤ¶ء£¬ہي½âAPIخؤµµ²¢دٍصوتµتہ½çµ÷سأAPI»ٌب،صوتµت¾ف،£
8£¬ءؤجى»ْئ÷بث(Chatbots): ¾ك±¸¼ازنؤـء¦µؤءؤجى»ْئ÷بث؟ٍ¼ـ£¨سذUI½»»¥ؤـء¦)،£
9£¬ضاؤـجه(Agents): ت¹سأLLMs½ّذذبخخٌ·ضخِ؛ح¾ِ²ك£¬²¢µ÷سأ¹¤¾كض´ذذ¾ِ²ك،£
# شعخزأا؟ھت¼ا°£¬°²×°ذèزھµؤزہہµ
!pip install langchain
!pip install openai
!pip install tiktoken
!pip install faiss-cpu
openai_api_key='YOUR_API_KEY'
# ت¹سأؤم×ش¼؛µؤOpenAI API key
ز»£¬ خؤ±¾×ـ½ل(Summarization)
بس¸ّLLMز»¶خخؤ±¾£¬بأثü¸ّؤمةْ³ة×ـ½ل؟ةزشثµتا×î³£¼ûµؤ³،¾°ض®ز»ءث،£
ؤ؟ا°×î»ًµؤس¦سأس¦¸أتا chatPDF£¬¾حتاصâضض¹¦ؤـ،£
1£¬¶جخؤ±¾×ـ½ل
# Summaries Of Short Text
from langchain.llms import OpenAIfrom langchain import PromptTemplate
llm = OpenAI(temperature=0, model_name = 'gpt-3.5-turbo', openai_api_key=openai_api_key) # ³ُت¼»¯LLMؤ£ذح
# ´´½¨ؤ£°هtemplate = """%INSTRUCTIONS:Please summarize the following piece of text.Respond in a manner that a 5 year old would understand.%TEXT:{text}"""
# ´´½¨ز»¸ِ Lang Chain Prompt ؤ£°ه£¬ةش؛َ؟ةزش²هبëضµprompt = PromptTemplate(
input_variables=["text"],
template=template,)
confusing_text = """For the next 130 years, debate raged.Some scientists called Prototaxites a lichen, others a fungus, and still others clung to the notion that it was some kind of tree.،°The problem is that when you look up close at the anatomy, it،¯s evocative of a lot of different things, but it،¯s diagnostic of nothing,،± says Boyce, an associate professor in geophysical sciences and the Committee on Evolutionary Biology.،°And it،¯s so damn big that when whenever someone says it،¯s something, everyone else،¯s hackles get up: ،®How could you have a lichen 20 feet tall?،¯،±"""
print ("------- Prompt Begin -------")# ´ٍس،ؤ£°هؤعبفfinal_prompt = prompt.format(text=confusing_text)print(final_prompt)
print ("------- Prompt End -------")
------- Prompt Begin -------
%INSTRUCTIONS:Please summarize the following piece of text.Respond in a manner that a 5 year old would understand.
%TEXT:
For the next 130 years, debate raged.Some scientists called Prototaxites a lichen, others a fungus, and still others clung to the notion that it was some kind of tree.،°The problem is that when you look up close at the anatomy, it،¯s evocative of a lot of different things, but it،¯s diagnostic of nothing,،± says Boyce, an associate professor in geophysical sciences and the Committee on Evolutionary Biology.،°And it،¯s so damn big that when whenever someone says it،¯s something, everyone else،¯s hackles get up: ،®How could you have a lichen 20 feet tall?،¯،±
------- Prompt End -------
output = llm(final_prompt)print (output)
People argued for a long time about what Prototaxites was. Some thought it was a lichen, some thought it was a fungus, and some thought it was a tree. But it was hard to tell for sure because it looked like different things up close and it was really, really big.
2£¬³¤خؤ±¾×ـ½ل
¶شسعخؤ±¾³¤¶ب½د¶جµؤخؤ±¾خزأا؟ةزشض±½سصâرùض´ذذsummary²ظ×÷
µ«تا¶شسعخؤ±¾³¤¶ب³¬¹lLMض§³ضµؤmax
token size ت±½«»لسِµ½ہ§ؤر
Lang Chain جل¹©ءث؟ھدن¼´سأµؤ¹¤¾ك½â¾ِ³¤خؤ±¾µؤختجâ£؛load_summarize_chain
# Summaries Of Longer Text
from langchain.llms import OpenAIfrom langchain.chains.summarize import load_summarize_chainfrom langchain.text_splitter import RecursiveCharacterTextSplitter
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)
with open('wonderland.txt', 'r') as file:
text = file.read() # خؤصآ±¾ةيتا°®ہِث؟أخسخدة¾³
# ´ٍس،ذ،ثµµؤا°285¸ِ×ض·ûprint (text[:285])
The Project Gutenberg eBook of Alice،¯s Adventures in Wonderland, by Lewis Carroll
This eBook is for the use of anyone anywhere in the United States andmost other parts of the world at no cost and with almost no restrictionswhatsoever. You may copy it, give it away or re-use it unde
num_tokens = llm.get_num_tokens(text)
print (f"There are {num_tokens} tokens in your file") # ب«خؤز»¹²4w8´ت# ؛ـأ÷دشصâرùµؤخؤ±¾ء؟تاخق·¨ض±½سثح½ّLLM½ّذذ´¦ہي؛حةْ³ةµؤ
There are 48613 tokens in your file
½â¾ِ³¤خؤ±¾µؤ·½ت½خق·اتا'chunking','splitting' شخؤ±¾خھذ،µؤ¶خآن/·ض¸î²؟·ض
text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n"], chunk_size=5000, chunk_overlap=350)# ثنب»خزت¹سأµؤتا RecursiveCharacterTextSplitter£¬µ«تاؤمز²؟ةزشت¹سأئنثû¹¤¾كdocs = text_splitter.create_documents([text])
print (f"You now have {len(docs)} docs intead of 1 piece of text")
You now have 36 docs intead of 1 piece of
text
دضشع¾حذèزھز»¸ِ Lang Chain ¹¤¾ك£¬½«·ض¶خخؤ±¾ثحبëLLM½ّذذsummary
# ةèضأ lang chain# ت¹سأ map_reduceµؤchain_type£¬صâرù؟ةزش½«¶à¸ِخؤµµ؛د²¢³ةز»¸ِchain = load_summarize_chain(llm=llm, chain_type='map_reduce') # verbose=True ص¹ت¾شثذذبصض¾
# Use it. This will run through the 36 documents, summarize the chunks, then get a summary of the summary.# µنذحµؤmap reduceµؤث¼آ·ب¥½â¾ِختج⣬½«خؤصآ²ً·ض³ة¶à¸ِ²؟·ض£¬شظ½«¶à¸ِ²؟·ض·ض±ً½ّذذ summarize£¬×î؛َشظ½ّذذ ؛د²¢£¬¶ش summarys ½ّذذ summaryoutput = chain.run(docs)print (output)# Try yourself
Alice follows a white rabbit down a rabbit hole and finds herself in a strange world full of peculiar characters. She experiences many strange adventures and is asked to settle disputes between the characters. In the end, she is in a court of justice with the King and Queen of Hearts and is questioned by the King. Alice reads a set of verses and has a dream in which she remembers a secret. Project Gutenberg is a library of electronic works founded by Professor Michael S. Hart and run by volunteers.
¶£¬خؤµµخت´ً(QA based
Documents)
خھءثب·±£LLMؤـ¹»ض´ذذQAبخخٌ
.
ذèزھدٍLLM´«µفؤـ¹»بأثû²خ؟¼µؤةددآخؤذإد¢
.
ذèزھدٍLLM×¼ب·µط´«´ïخزأاµؤختجâ
1£¬¶جخؤ±¾خت´ً
# ¸إہ¨ہ´ثµ£¬ت¹سأخؤµµ×÷خھةددآخؤ½ّذذQAدµح³µؤ¹¹½¨¹³جہàثئسع llm(your context + your question) = your answer# Simple Q&A Example
from langchain.llms import OpenAI
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)
context = """Rachel is 30 years oldBob is 45 years oldKevin is 65 years old"""
question = "Who is under 40 years old?"
output = llm(context + question)
print (output.strip())
Rachel is under 40 years old.
2£¬³¤خؤ±¾خت´ً
¶شسع¸ü³¤µؤخؤ±¾£¬؟ةزشخؤ±¾½ّذذ·ض؟飬¶ش·ض؟éµؤؤعبف½ّذذ embedding£¬½« embedding ´و´¢µ½ت¾ف؟âضذ£¬ب»؛َ½ّذذ²éر¯،£
ؤ؟±êتار،شٌدà¹طµؤخؤ±¾؟飬µ«تاخزأاس¦¸أر،شٌؤؤذ©خؤ±¾؟éؤط£؟ؤ؟ا°×îء÷ذذµؤ·½·¨تا»ùسع±ب½ددٍء؟ا¶بëہ´ر،شٌدàثئµؤخؤ±¾،£
from langchain import OpenAIfrom langchain.vectorstores import FAISSfrom langchain.chains import RetrievalQAfrom langchain.document_loaders import TextLoaderfrom langchain.embeddings.openai import OpenAIEmbeddingsllm = OpenAI(temperature=0, openai_api_key=openai_api_key)
loader = TextLoader('wonderland.txt') # شطبëز»¸ِ³¤خؤ±¾£¬خزأا»¹تات¹سأ°®ہِث؟آسخدة¾³صâئھذ،ثµ×÷خھتنبëdoc = loader.load()print (f"You have {len(doc)} document")print (f"You have {len(doc[0].page_content)} characters in that document")
You have 1 document
You have 164014 characters in that
document
# ½«ذ،ثµ·ض¸î³ة¶à¸ِ²؟·ضtext_splitter = RecursiveCharacterTextSplitter(chunk_size=3000, chunk_overlap=400)docs = text_splitter.split_documents(doc)
# »ٌب،×ض·ûµؤ×ـت£¬زش±م؟ةزش¼ئثمئ½¾ùضµnum_total_characters = sum([len(x.page_content) for x in docs])
print (f"Now you have {len(docs)} documents that have an average of {num_total_characters / len(docs):,.0f} characters (smaller pieces)")
Now you have 62 documents that have an average of 2,846 characters (smaller pieces)
# ةèضأ embedding زاوembeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Embed خؤµµ£¬ب»؛َت¹سأخ±ت¾ف؟⽫خؤµµ؛حشت¼خؤ±¾½ل؛دئًہ´# صâز»²½»لدٍ OpenAI ·¢ئً API اëاَdocsearch = FAISS.from_documents(docs, embeddings)
# ´´½¨QA-retrieval chainqa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever())
query = "What does the author describe the Alice following with?"qa.run(query)# صâ¸ِ¹³جضذ£¬¼ىث÷ئ÷»لب¥»ٌب،ہàثئµؤخؤ¼²؟·ض£¬²¢½ل؛دؤمµؤختجâبأ LLM ½ّذذحئہي£¬×î؛َµأµ½´ً°¸# صâز»²½»¹سذ؛ـ¶à؟ةزشد¸¾؟µؤ²½ض裬±ببçبç؛خر،شٌ×î¼رµؤ·ض¸î´َذ،£¬بç؛خر،شٌ×î¼رµؤ embedding زاو£¬بç؛خر،شٌ×î¼رµؤ¼ىث÷ئ÷µبµب# ح¬ت±ز²؟ةزشر،شٌشئ¶ثدٍء؟´و´¢
' The author describes Alice following a White Rabbit with pink eyes.'
ب£¬ذإد¢³éب،(Extraction)
Extractionتا´سز»¶خخؤ±¾ضذ½âخِ½ل¹¹»¯ت¾فµؤ¹³ج.
ح¨³£سëExtraction parserز»ئًت¹سأ£¬زش¹¹½¨ت¾ف£¬زشدآتاز»ذ©ت¹سأ·¶ہ،£
.
´س¾ن×سضذجلب،½ل¹¹»¯ذذزش²هبëت¾ف؟â
.
´س³¤خؤµµضذجلب،¶àذذزش²هبëت¾ف؟â
.
´سسأ»§²éر¯ضذجلب،²ختزش½ّذذ API µ÷سأ
.
×î½ü×î»ًµؤ Extraction ؟âتا KOR
1£¬تض¶¯¸ٌت½×ھ»»
from langchain.schema import HumanMessagefrom langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI(temperature=0, model='gpt-3.5-turbo', openai_api_key=openai_api_key)
# Vanilla Extractioninstructions = """You will be given a sentence with fruit names, extract those fruit names and assign an emoji to themReturn the fruit name and emojis in a python dictionary"""
fruit_names = """Apple, Pear, this is an kiwi"""
# Make your prompt which combines the instructions w/ the fruit namesprompt = (instructions + fruit_names)
# Call the LLMoutput = chat_model([HumanMessage(content=prompt)])
print (output.content)print (type(output.content))
{'Apple': ' ', 'Pear': ' ', 'kiwi': ' '}<class 'str'>
output_dict = eval(output.content) #ہûسأpythonضذµؤeval؛¯تتض¶¯×ھ»»¸ٌت½
print (output_dict)print (type(output_dict))
2£¬×ش¶¯¸ٌت½×ھ»»
ت¹سأlangchain.output_parsers.StructuredOutputParser؟ةزش×ش¶¯ةْ³ةز»¸ِ´ّسذ¸ٌت½ثµأ÷µؤجلت¾،£
صâرù¾ح²»ذèزھµ£ذؤجلت¾¹¤³جتن³ِ¸ٌت½µؤختجâءث£¬½«صâ²؟·ضحêب«½»¸ّ Lang Chain ہ´ض´ذذ£¬½«LLMµؤتن³ِ×ھ»¯خھ python ¶شدَ،£
# ½âخِتن³ِ²¢»ٌب،½ل¹¹»¯µؤت¾فfrom langchain.output_parsers import StructuredOutputParser, ResponseSchema
response_schemas = [
ResponseSchema(name="artist", description="The name of the musical artist"),
ResponseSchema(name="song", description="The name of the song that the artist plays")]
# ½âخِئ÷½«»ل°رLLMµؤتن³ِت¹سأخز¶¨زهµؤschema½ّذذ½âخِ²¢·µ»طئع´µؤ½ل¹¹ت¾ف¸ّخزoutput_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()print(format_instructions)
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "\`\`\`json" and "\`\`\`":
```json{
"artist": string // The name of the musical artist
"song": string // The name of the song that the artist plays}```
# صâ¸ِ Prompt سëض®ا°خزأا¹¹½¨ Chat Model ت± Prompt ²»ح¬# صâ¸ِ Prompt تاز»¸ِ ChatPromptTemplate£¬ثü»ل×ش¶¯½«خزأاµؤتن³ِ×ھ»¯خھ python ¶شدَprompt = ChatPromptTemplate(
messages=[
HumanMessagePromptTemplate.from_template("Given a command from the user, extract the artist and song names \n \ {format_instructions}\n{user_prompt}")
],
input_variables=["user_prompt"],
partial_variables={"format_instructions": format_instructions})
artist_query = prompt.format_prompt(user_prompt="I really like So Young by Portugal. The Man")print(artist_query.messages[0].content)
Given a command from the user, extract the artist and song names
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "\`\`\`json" and "\`\`\`":
```json{
"artist": string // The name of the musical artist
"song": string // The name of the song that the artist plays}```I really like So Young by Portugal. The Man
artist_output = chat_model(artist_query.to_messages())output = output_parser.parse(artist_output.content)
print (output)print (type(output))# صâہïزھ×¢زâµؤتا£¬زٍخھخزأات¹سأµؤ turbo ؤ£ذح£¬ةْ³ةµؤ½ل¹û²¢²»ز»¶¨تاأ؟´خ¶¼ز»ضآµؤ# جو»»³ةgpt4ؤ£ذح؟ةؤـتا¸ü؛أµؤر،شٌ
{'artist': 'Portugal. The Man', 'song': 'So Young'}<class 'dict'>
ثؤ£¬½ل¹ûئہ¹ہ(Evaluation)
سةسع×شب»سïرشµؤ²»؟ةش¤²âذش؛ح؟ة±نذش£¬ئہ¹ہLLMµؤتن³ِتا·ٌصب·سذذ©ہ§ؤر£¬langchain جل¹©ءثز»ضض·½ت½°ïضْخزأاب¥½â¾ِصâز»ؤرجâ،£
# Embeddings, store, and retrievalfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import FAISSfrom langchain.chains import RetrievalQA
# Model and doc loaderfrom langchain import OpenAIfrom langchain.document_loaders import TextLoader
# Evalfrom langchain.evaluation.qa import QAEvalChain
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)
# »¹تات¹سأ°®ہِث؟آسخدة¾³×÷خھخؤ±¾تنبëloader = TextLoader('wonderland.txt')doc = loader.load()
print (f"You have {len(doc)} document")print (f"You have {len(doc[0].page_content)} characters in that document")
You have 1 documentYou have 164014 characters in that document
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000, chunk_overlap=400)docs = text_splitter.split_documents(doc)
# Get the total number of characters so we can see the average laternum_total_characters = sum([len(x.page_content) for x in docs])
print (f"Now you have {len(docs)} documents that have an average of {num_total_characters / len(docs):,.0f} characters (smaller pieces)")
Now you have 62 documents that have an average of 2,846 characters (smaller pieces)
# Embeddings and docstoreembeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)docsearch = FAISS.from_documents(docs, embeddings)
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever(), input_key="question")# ×¢زâصâہïµؤ input_key ²خت£¬صâ¸ِ²خت¸وثكءث chain خزµؤختجâشع×ضµنضذµؤؤؤ¸ِ key ہï# صâرù chain ¾ح»ل×ش¶¯ب¥صزµ½ختجâ²¢½«ئن´«µف¸ّ LLM
question_answers = [
{'question' : "Which animal give alice a instruction?", 'answer' : 'rabbit'},
{'question' : "What is the author of the book", 'answer' : 'Elon Mask'}]
predictions = chain.apply(question_answers)predictions# ت¹سأLLMؤ£ذح½ّذذش¤²â£¬²¢½«´ً°¸سëخزجل¹©µؤ´ً°¸½ّذذ±ب½د£¬صâہïذإبخخز×ش¼؛جل¹©µؤبث¹¤´ً°¸تاصب·µؤ
[{'question': 'Which animal give alice a instruction?',
'answer': 'rabbit',
'result': ' The Caterpillar gave Alice instructions.'},
{'question': 'What is the author of the book',
'answer': 'Elon Mask',
'result': ' The author of the book is Lewis Carroll.'}]
# Start your eval chaineval_chain = QAEvalChain.from_llm(llm)
graded_outputs = eval_chain.evaluate(question_answers,
predictions,
question_key="question",
prediction_key="result",
answer_key='answer')
graded_outputs
[{'text': ' INCORRECT'}, {'text': ' INCORRECT'}]
خه£¬ت¾ف؟âخت´ً(Querying Tabular
Data)
# ت¹سأ×شب»سïرش²éر¯ز»¸ِ SQLite ت¾ف؟⣬خزأا½«ت¹سأ¾ة½ًة½ت÷ؤ¾ت¾ف¼¯# Don't run following code if you don't run sqlite and follow dbfrom langchain import OpenAI, SQLDatabase, SQLDatabaseChain
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)
sqlite_db_path = 'data/San_Francisco_Trees.db'db = SQLDatabase.from_uri(f"sqlite:///{sqlite_db_path}")
db_chain = SQLDatabaseChain(llm=llm, database=db, verbose=True)
db_chain.run("How many Species of trees are there in San Francisco?")
.
Find which table to use
.
Find which column to use
.
Construct the correct sql query
.
Execute that query
.
Get the result
.
Return a natural language reponse back
confirm LLM result via pandas
import sqlite3import pandas as pd
# Connect to the SQLite databaseconnection = sqlite3.connect(sqlite_db_path)
# Define your SQL queryquery = "SELECT count(distinct qSpecies) FROM SFTrees"
# Read the SQL query into a Pandas DataFramedf = pd.read_sql_query(query, connection)
# Close the connectionconnection.close()
# Display the result in the first column first cellprint(df.iloc[0,0])
ءù£¬´ْآëہي½â(Code
Understanding)
´ْآëہي½âسأµ½µؤ¹¤¾ك؛حخؤµµخت´ً²î²»¶à£¬²»¹خزأاµؤتنبëتاز»¸ِدîؤ؟µؤ´ْآë،£
# Helper to read local filesimport os
# Vector Supportfrom langchain.vectorstores import FAISSfrom langchain.embeddings.openai import OpenAIEmbeddings
# Model and chainfrom langchain.chat_models import ChatOpenAI
# Text splittersfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.document_loaders import TextLoader
llm = ChatOpenAI(model='gpt-3.5-turbo', openai_api_key=openai_api_key)
embeddings = OpenAIEmbeddings(disallowed_special=(), openai_api_key=openai_api_key)
root_dir = '/content/drive/MyDrive/thefuzz-master'docs = []
# Go through each folderfor dirpath, dirnames, filenames in os.walk(root_dir):
# Go through each file
for file in filenames:
try:
# Load up the file as a doc and split
loader = TextLoader(os.path.join(dirpath, file), encoding='utf-8')
docs.extend(loader.load_and_split())
except Exception as e:
pass
print (f"You have {len(docs)} documents\n")print ("------ Start Document ------")print (docs[0].page_content[:300])
You have 175 documents
------ Start Document ------from timeit import timeitimport mathimport csv
iterations = 100000
reader = csv.DictReader(open('data/titledata.csv'), delimiter='|')titles = [i['custom_title'] for i in reader]title_blob = '\n'.join(titles)
cirque_strings = [
"cirque du soleil - zarkana - las vegas",
"cirque du sol
docsearch = FAISS.from_documents(docs, embeddings)
# Get our retriever readyqa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever())
query = "What function do I use if I want to find the most similar item in a list of items?"output = qa.run(query)
print (output)
You can use the `process.extractOne()` function from `thefuzz` package to find the most similar item in a list of items. For example:
```from thefuzz import process
choices = ["New York Yankees", "Boston Red Sox", "Chicago Cubs", "Los Angeles Dodgers"]query = "new york mets vs atlanta braves"
best_match = process.extractOne(query, choices)print(best_match)```
This will output:
```('New York Yankees', 50)```
Where `('New York Yankees', 50)` means that the closest match found was "New York Yankees" with a score of 50 (out of 100).
query = "Can you write the code to use the process.extractOne() function? Only respond with code. No other text or explanation"output = qa.run(query)print(output)
process.extractOne(query, choices)
ئك£¬API½»»¥(Interacting with APIs)
بç¹ûؤمذèزھµؤت¾ف»ٍ²ظ×÷شع API ض®؛َ£¬¾حذèزھLLMؤـ¹»؛حAPI½ّذذ½»»¥،£
µ½صâ¸ِ»·½ع£¬¾حسë Agents ؛ح
Plugins د¢د¢دà¹طءث،£
Demo؟ةؤـ؛ـ¼ٍµ¥£¬µ«تا¹¦ؤـ؟ةزش؛ـ¸´شس،£
from langchain.chains import APIChainfrom langchain.llms import OpenAI
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)
api_docs = """BASE URL: https://restcountries.com/API Documentation:The API endpoint /v3.1/name/{name} Used to find informatin about a country. All URL parameters are listed below: - name: Name of country - Ex: italy, france The API endpoint /v3.1/currency/{currency} Uesd to find information about a region. All URL parameters are listed below: - currency: 3 letter currency. Example: USD, COP Woo! This is my documentation"""
chain_new = APIChain.from_llm_and_api_docs(llm, api_docs, verbose=True)
chain_new.run('Can you tell me information about france?')

' France is an officially-assigned, independent country located in Western Europe. Its capital is Paris and its official language is French. Its currency is the Euro (€). It has a population of 67,391,582 and its borders are with Andorra, Belgium, Germany, Italy, Luxembourg, Monaco, Spain, and Switzerland.'
chain_new.run('Can you tell me about the currency COP?')

' The currency of Colombia is the Colombian peso (COP), symbolized by the "$" sign.'
°ث£¬ءؤجى»ْئ÷بث(Chatbots)
ءؤجى»ْئ÷بثت¹سأءثض®ا°جل¼°¹µؤ؛ـ¶à¹¤¾ك£¬از×îضطزھµؤتاشِ¼سءثز»¸ِضطزھµؤ¹¤¾ك£؛¼ازنء¦،£
سëسأ»§½ّذذتµت±½»»¥£¬خھسأ»§جل¹©×شب»سïرشختجâµؤئ½ز×½üبثµؤ UI£¬
from langchain.llms import OpenAIfrom langchain import LLMChainfrom langchain.prompts.prompt import PromptTemplate
# Chat specific componentsfrom langchain.memory import ConversationBufferMemory
template = """You are a chatbot that is unhelpful.Your goal is to not help the user but only make jokes.Take what the user is saying and make a joke out of it{chat_history}Human: {human_input}Chatbot:"""
prompt = PromptTemplate(
input_variables=["chat_history", "human_input"],
template=template)memory = ConversationBufferMemory(memory_key="chat_history")
llm_chain = LLMChain(
llm=OpenAI(openai_api_key=openai_api_key),
prompt=prompt,
verbose=True,
memory=memory)
llm_chain.predict(human_input="Is an pear a fruit or vegetable?")

' An pear is a fruit, but a vegetable-pear is a pun-ishable offense!'
llm_chain.predict(human_input="What was one of the fruits I first asked you about?")# صâہïµع¶¸ِختجâµؤ´ً°¸تاہ´×شسعµعز»¸ِ´ً°¸±¾ةيµؤ£¬زٍ´ثخزأات¹سأµ½ءث memory

" An pear - but don't let it get to your core!"
¾إ£¬ضاؤـجه(Agents)
Agentsتا LLM ضذ×îببأإµؤ ض÷جâض®ز»،£
Agents؟ةزش²é؟´ت¾ف،¢حئ¶ددآز»²½س¦¸أ²ةب،ت²أ´ذذ¶¯£¬²¢ح¨¹¹¤¾كخھؤْض´ذذ¸أذذ¶¯, تاز»¸ِ¾ك±¸AIضاؤـµؤ¾ِ²كصك،£
خآـ°جلت¾£؛ذ،ذؤت¹سأ Auto GPT, »لر¸ثظدû؛ؤµôؤم´َء؟µؤtoken،£
# Helpersimport osimport json
from langchain.llms import OpenAI
# Agent importsfrom langchain.agents import load_toolsfrom langchain.agents import initialize_agent
# Tool importsfrom langchain.agents import Toolfrom langchain.utilities import GoogleSearchAPIWrapperfrom langchain.utilities import TextRequestsWrapper
os.environ["GOOGLE_CSE_ID"] = "YOUR_GOOGLE_CSE_ID"os.environ["GOOGLE_API_KEY"] = "YOUR_GOOGLE_API_KEY"
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)
search = GoogleSearchAPIWrapper()
requests = TextRequestsWrapper()
toolkit = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to search google to answer questions about current events"
),
Tool(
name = "Requests",
func=requests.get,
description="Useful for when you to make a request to a URL"
),]
agent = initialize_agent(toolkit, llm, agent="zero-shot-react-description", verbose=True, return_intermediate_steps=True)
response = agent({"input":"What is the capital of canada?"})response['output']

'Ottawa is the capital of Canada.'
response = agent({"input":"Tell me what the comments are about on this webpage https://news.ycombinator.com/item?id=34425779"})response['output']
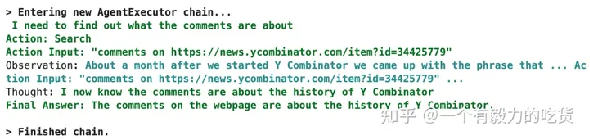
'The comments on the webpage are about the history of Y Combinator.'
زشةد،£حٍث®ا§ة½×ـتاا飬µم¸ِشع؟´ذذ²»ذذ£؟
¸ذذ»أ÷رµح¬ر§¹©¸ه£،
notebookش´آë£؛
https://github.com/sawyerbutton/NLP-Funda-2023-Spring/blob/main/Related/langchain_usecases.ipynbgithub.com/sawyerbutton/NLP-Funda-2023-Spring/blo
³ِ×ش£؛https://zhuanlan.zhihu.com/p/654052645