介绍:
ComfyUI 是一个基于节点流程式的stable diffusion AI 绘图工具WebUI, 你可以把它想象成集成了stable diffusion功能的substance designer, 通过将stable diffusion的流程拆分成节点,实现了更加精准的工作流定制和完善的可复现性。但节点式的工作流也提高了一部分使用门槛。
同时,因为内部生成流程做了优化,生成图片时的速度相较于webui又10%~25%的提升(根据不同显卡提升幅度不同),生成大图片的时候不会爆显存,只是图片太大时,会因为切块运算的导致图片碎裂(个人测试在8G显存下直接生成2360x1440分辨率没有问题,往上有几率切碎)
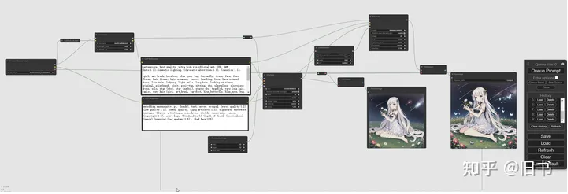
ComfyUI中简单的lora+Highresfix流程
先上官方链接:
https://github.com/comfyanonymous/ComfyUIgithub.com/comfyanonymous/ComfyUI
基础配置:
下载:
首先从官方的github连接上找到最新的release包,直接下载下来,解压即可使用:

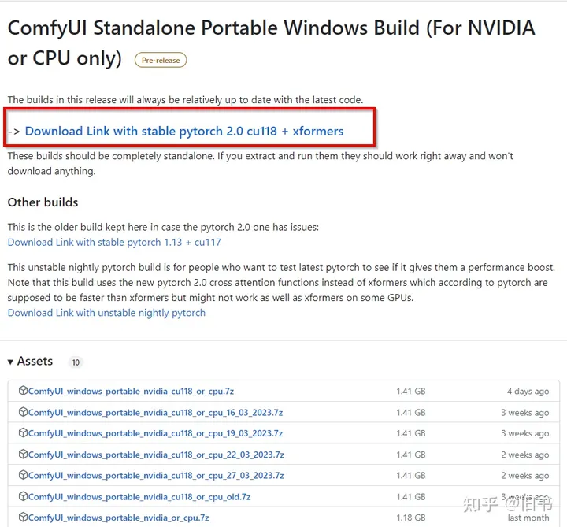
显卡比较新的话,直接下载pytorch2.0的版本,老一点的显卡可能需要下载pytorch1.13的版本
解压完成后直接启动batch文件即可启动ComfyUI:
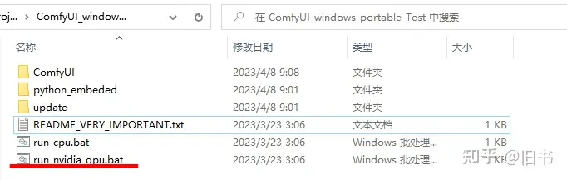
别急着启动,没模型启动了啥也干不了~
但是先别急~,
配置模型
ComfyUI虽然自带了pytorch和stable
diffusion环境,但是不包括模型,所以需要将模型放置到ComfyUI对应目录中:
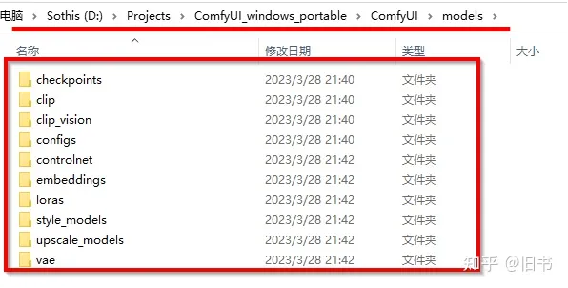
别急着复制,用WebUI的模型岂不美哉~
但还是先别急~,
如果你使用过WebUI,那么你的模型文件通常是放在stable-diffusion-webui目录下的,复制过来就会很浪费空间,所以ComfyUI的作者提供了将WebUI中存放的模型链接进来的功能:
在ComfyUI目录中找到这个叫做
extra_model_paths.yaml.example的文件,并将后缀名example去掉:
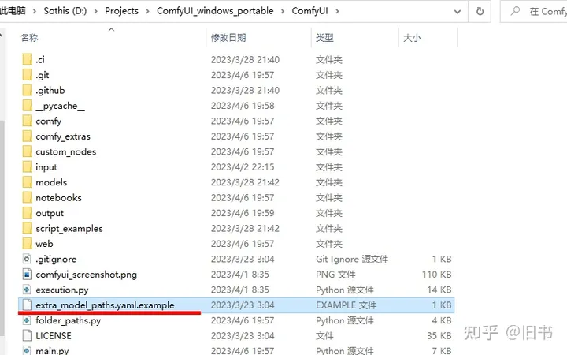
去掉这个文件的后缀名并打开它
然后在这文件里面将A1111的路径设置好:相对路径也可以
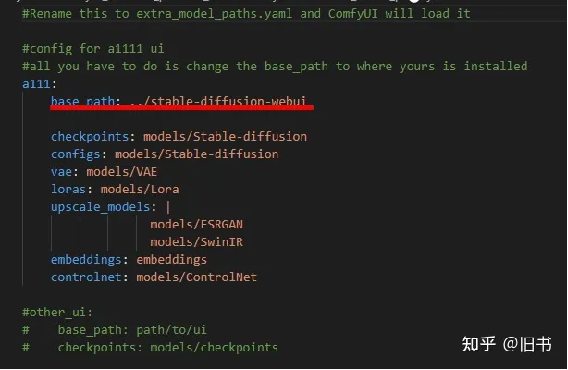
我的电脑上WebUI与ComfyUI是存放在同一路径下的,所以这里直接使用了相对路径
现在启动ComfyUI就可以直接使用了。
后续更新
如果后面需要更新ComfyUI,可以直接使用ComfyUI中的update脚本,就不需要重新下载和配置了:
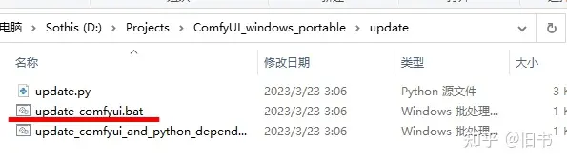
下面那个batch会更新python和依赖项,官方说一般情况先不需要用
基础流程:
基本的流程全都包含在了官方的实例页面中,:
https://comfyanonymous.github.io/ComfyUI_examples/comfyanonymous.github.io/ComfyUI_examples/
英文比较好的同学也可以看看官方的这个教学的视觉小说,讲得挺细致的:
ComfyUI Tutorialcomfyanonymous.github.io/ComfyUI_tutorial_vn/
强烈建议都看一遍,因为ComfyUI的可复现性,即便没有看懂,你可以将示例中的图片下载下来,然后直接拖动到ComfyUI的界面中,就能重构出生成这张图的节点网络,包括使用的参数和种子,只要你也使用一样的模型和Lora,那么就能够几乎生成这同一张图。
下面我们讲一下具体功能:
这里以一个简单的lora+highresFix为例子,大概说明一下基础的节点和使用:
text2img:
首先我们构建一个最简单的text2img网络:
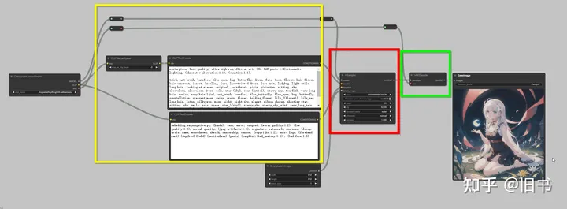
Clip阶段(黄色),Unet阶段(红色),Vae解码阶段(绿色)
节点有两种创建方式:
鼠标右键呼出节点目录,可以直接在目录中选择节点:
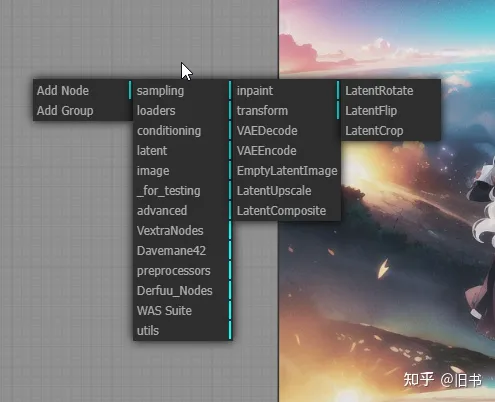
右键节点菜单
鼠标双击呼出节点搜索窗口,知道节点名称的话,直接搜索比较快:
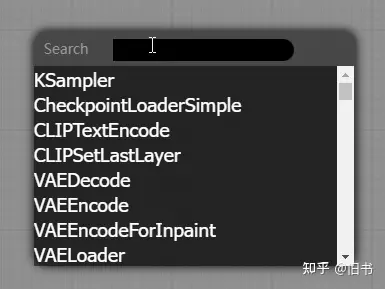
双击搜索菜单
连接好节点网络,通过点击面板右侧的工具栏中的 Queue Prompt,就能开始图片生成了:
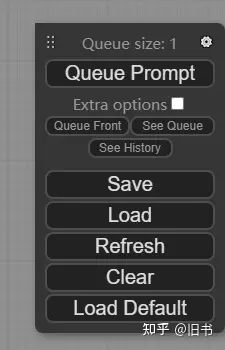
对,就最上面那个,点他就对了~
通过使用鼠标点击拖动节点上的输出输入点,即可创建连线。
一般的的节点网络包括:
·
输入阶段:模型输入,图片输入,等。负责载入模型和图片。
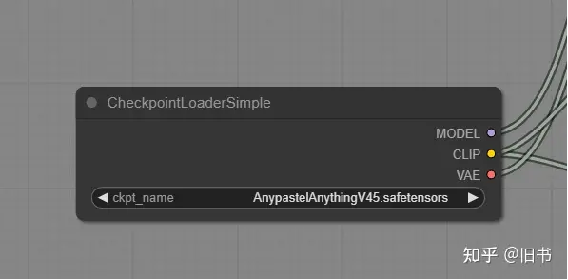
模型载入节点将模型分成了 模型,clip层,VAE,clip层会在关键词编码的时候使用,VAE会在图片编码解码(图片RGB空间与潜空间转换)时使用
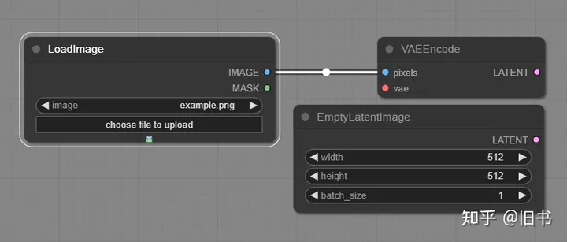
图片节点可以载入图片并转换到潜空间,或者创建新的潜空间空图片,这里可以定义生成图片的大小
·
Clip阶段:clip跳过,clip编码器,lora,controlnet都在这个阶段。
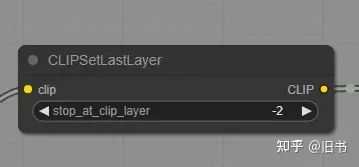
clip跳过,使参数在clip模型上提前失效。
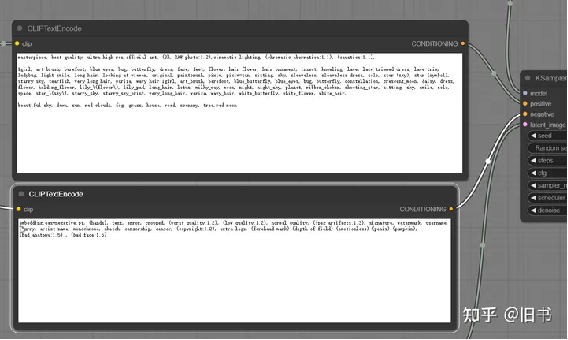
Clip文字编码器节点,正面和负面分成两个节点
·
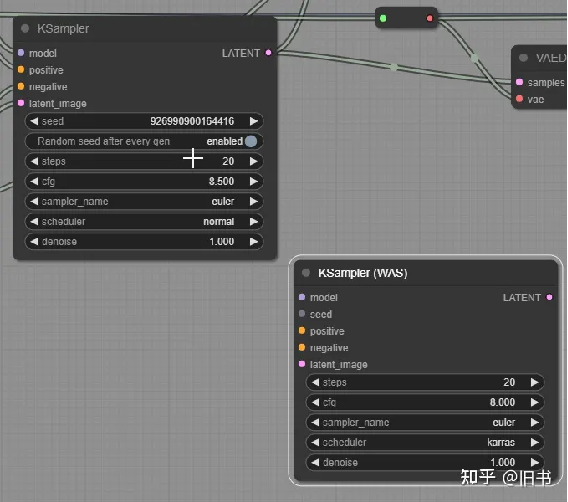
Unet阶段:ksampler节点,负责在潜空间生成图片。
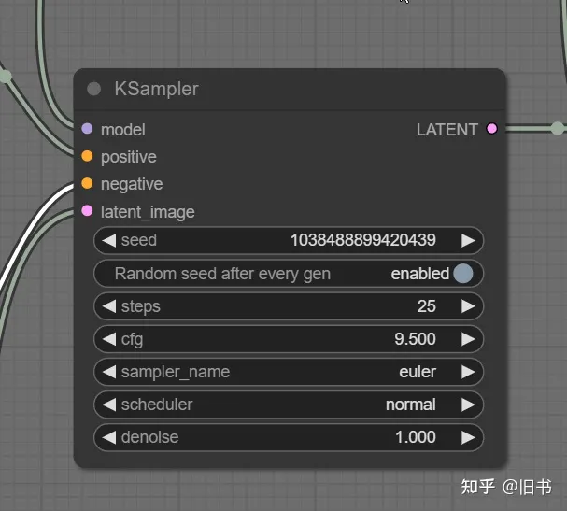
KSampler节点,Unet生成潜空间图品的地方,参数和webui中的生成参数基本上相同。
·
Vae解码阶段:将生成的图片从潜空前转换成RGB色彩空间。
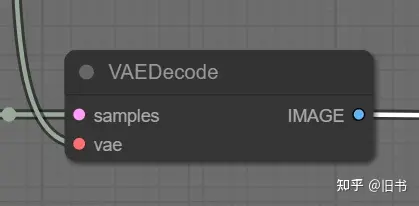
Vae解码节点,这里可以链接不同的VAE来得到不同的解码结果。
·
保存和后处理阶段:预览,保存,后处理
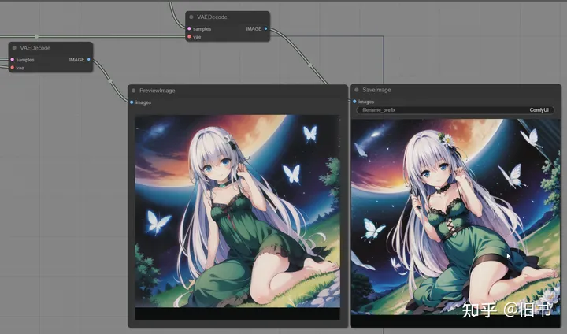
预览节点不会保存图片。
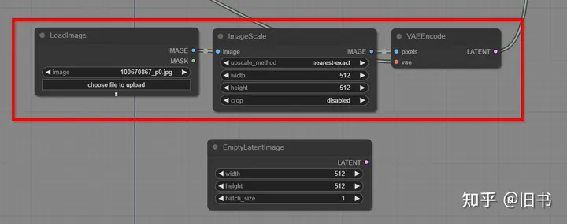
img2img:
基本流程与text2timg一致,只需要将EmptyLatenImage节点替换成LoadImage和VaeEncode,如果图片尺寸不合适,可以添加一个ImageScale节点来缩放图片到合适的尺寸。
lora使用:
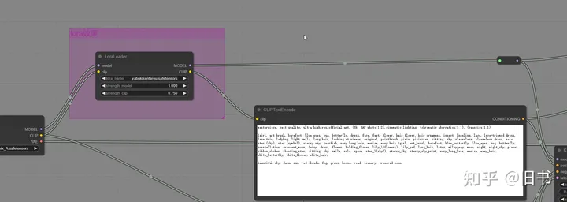
lora 直接插入在clip阶段的Clip编码器之前,通常lora只作用于正面描述词。
HighResFix使用:
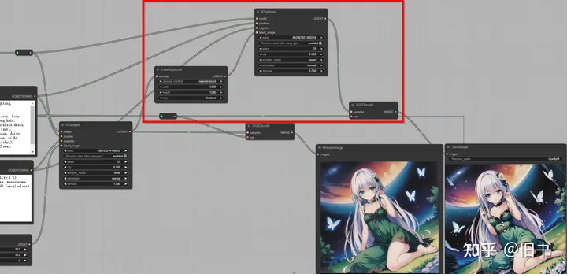
HighResFix 其实是将生成的潜空图片在不解码的情况下放大,加入噪声再进行一次生成的过程。
ERSGan无损放大:
利用ESRGan或者SwinIR模型的无损放大算法,并不会增加细节
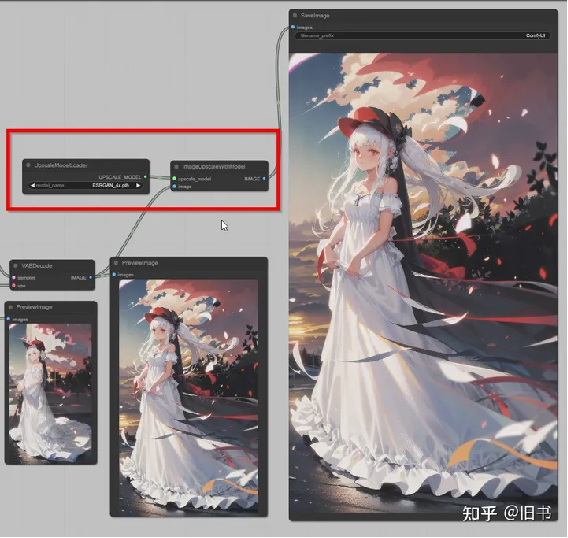
无损放大生成的4K图片
进阶流程:
ContrrolNet使用:
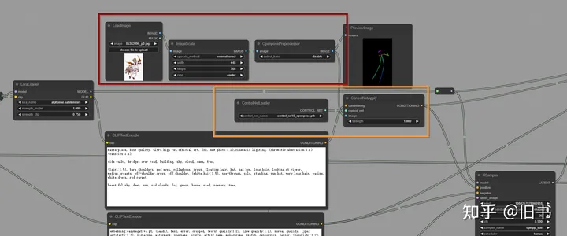
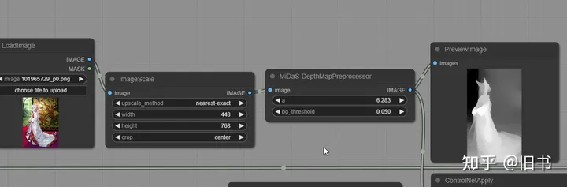
黄色部分为control net模型加载和修改器,红色部分为有插件提供的controlnet预处理器

由上图节点生成的图片
contronet的模型通过controlnetloader载入,通过contronetapply插入到经过编码的condition之中(上图黄色部分),由于comfyui并没有集成controlnet的预处理器,我们需要安装一个插件来帮我们预处理图品,当然我们也可以借助webui来预处理图片
插件地址:
https://github.com/EllangoK/ComfyUI-post-processing-nodesgithub.com/EllangoK/ComfyUI-post-processing-nodes
Area Composition使用:
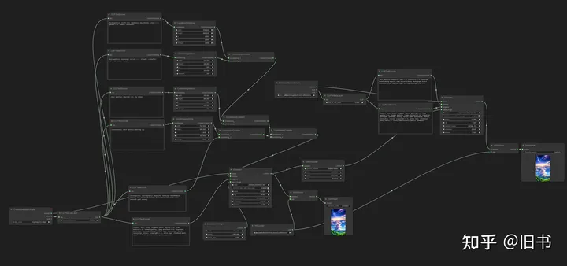
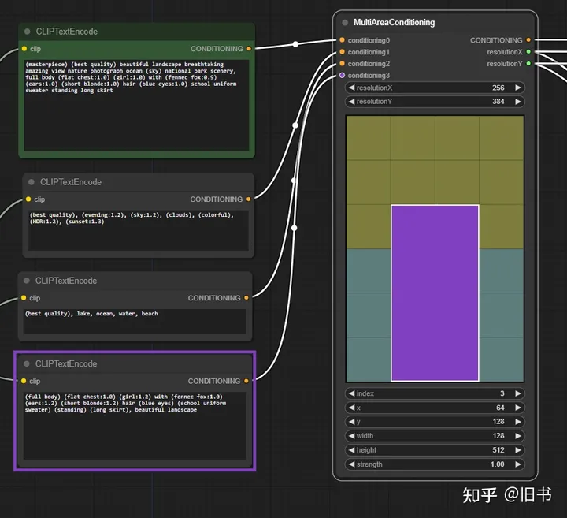
comfyUI提供的AreaCondition流程
Area Composition相当于将画布拆分成了好几块,每一块都有自己的关键词,从而达到对画面每一块更加精确的控制的目的,我用下来发现的确好用,但是通过像素数字来控制区域不是特别直观,而且每次调整都比较繁琐。
于是理所当然的有人搞了个可视化的Area Composition节点:
https://github.com/Davemane42/ComfyUI_Dave_CustomNodegithub.com/Davemane42/ComfyUI_Dave_CustomNode
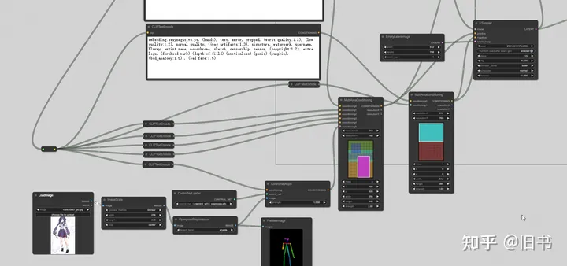
使用这个插件的节点便能够可视化的知道什么数值对应的画面的哪个区域,而这个区域又对应的那些关键字

由上图节点生成的图片,致敬一下tearfish老师
即便如此,这样横平竖直的画面切分只能说方便了构图,但是实际效果并不理想,不同区域的重叠部分后导致内容融合,一些较小的区域的内容有时直接被其他的区域覆盖了过去。
Noisy Latent
Composition使用:
这个流程与上面的AreaComposition类似,都是希望能够单独控制画面区域内的内容,不同的是这次不是在condition阶段进行构图,而是在潜空间(latent space)进行:
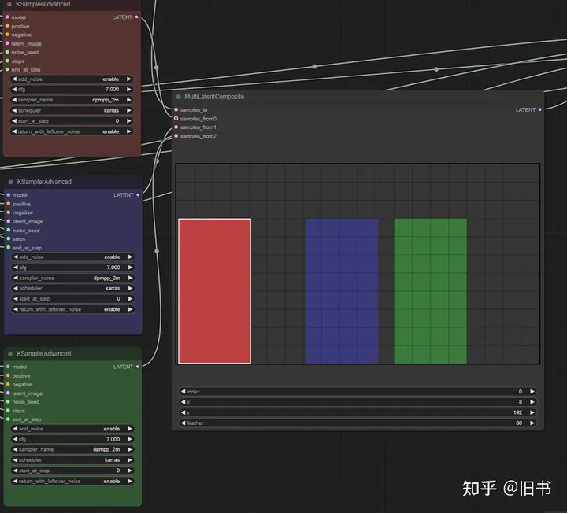
Dave_CustomNode插件中的latentcomposition,与官方的理论一致,只是能够更好的可视化
这个流程的优势在于不同的区域能够使用不同的模型,lora,不再只是限制在关键字上。这就为不同的区域的效果定制化打开了更大的可能性。
但是,我在实际使用中,发现还是有语义污染的问题不好解决:首先,潜空间的构图是很好的,但是不同关键字,生成的结果有时会产生融合不自然的问题(),这就需要一个或者多个HighResFix pass来融合一下图片,但是这个Pass只能接受一组关键字,就导致最后的pass会造成明显的语义污染,就连官方的实例图片里面几个角色的脸都变成一样的了。。。。。
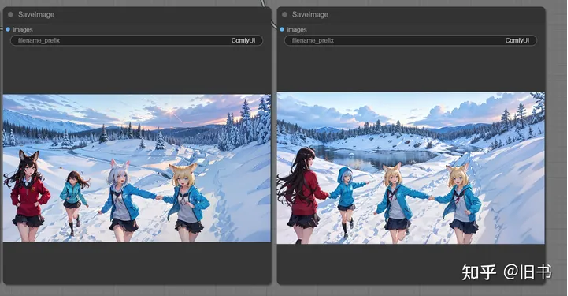
插件官方的示例中,第一个融合pass(左)没什么问题,第二个融合pass(右)就发现有人染发了。
虽然这样的现象导致使用的时候会出现不好控制局部效果的问题,但是这个思路个人认为很好,后续应该也有相应的技术或者流程来解决这个问题。
队列,历史,保存和载入:
在ComfyUI右侧(默认)的命令菜单中:
队列:
点击see queue便能够看见队列,这里会列出当前正在执行的生成和正在排队的生成,你可以随时通过queue prompt往队列里面添加新的任务,也可以取消任何一个任务,或者让新的任务插队:
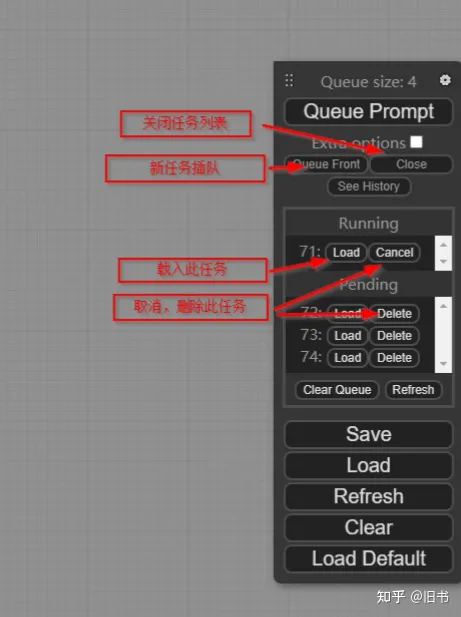
历史记录:
点击see history便能够看见历史记录,这里会记录你每一次点击添加的任务,包括报错没有结果的生成,每一次重启之后这里会清空。
在这里你可以载入你之前的生成任务,包括生成时的节点网络状态,和生成结果:
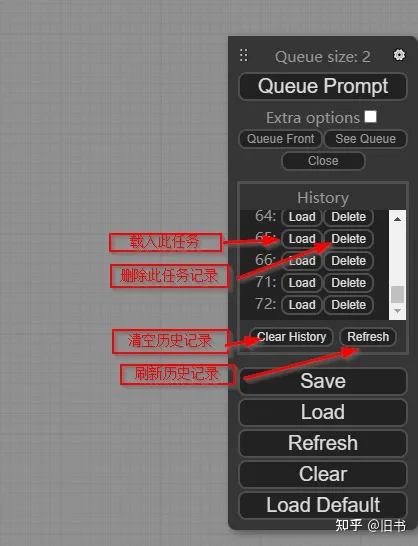
保存和载入:
大大save和load两个按钮,但是我却比较少用~
因为每进行一次生成,这次生成所需的所有信息基本上都会记录到生成的图片结果中,并存放在
comfyui\out\ 目录下,只要不对输出的图片进行编辑或者压缩,那么只要再把这个图片拖动到ComfyUI界面中,就能还原当时的节点网络状态,保证再次生成同一张图(当然,这需要模型,lora,comtrolnet图片等等,这些外部依赖项没有发生改变)
对于webui生成的图片,comfyui也能够读取基本参数和基础流程,不过,不知道什么原因(?),即便是一样的参数,模型,lora,comfyui一直没能重现webui生成的图片
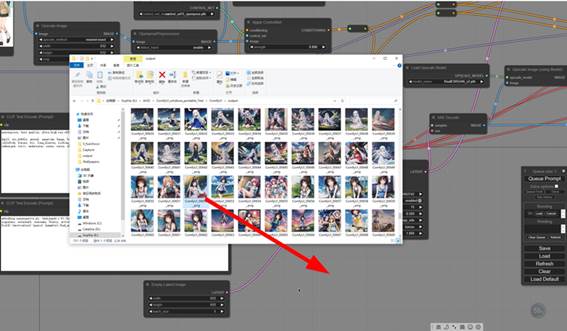
直接拖动过来,就能重现出当时的节点网络和流程
插件:
“在AI绘图这个不成熟而又在疯狂发展的领域里面,敢于大量并持续的投入时间和精力进行开发的人们,都有资格被称作为勇士”
—— 无名
AI的发展日新日异,自然没有哪个工具是完美的,ComfyUI也有不少插件来补充其不足的部分,这里我简单的介绍几个我认为比较有价值的几个:
安装方式:
直接在\ComfyUI\custom_nodes目录下git clone 插件的 git仓库即可,部分插件需要用comfyui自带的python来 安装依赖项,例如controlnet预处理器这个插件:


WAS Node Suite
这个插件提供了大量图片处理上需要用到的节点,甚至包括一些自定义的的原生节点
https://github.com/WASasquatch/was-node-suite-comfyuigithub.com/WASasquatch/was-node-suite-comfyui
Derfuu_ComfyUI_ModdedNodes
这个插件添加了不少数学和图片大小自动化的节点,同时也添加了LatentComposition的支持,个人对这个插件使用主要是集中在数学节点上。
https://github.com/Derfuu/Derfuu_ComfyUI_ModdedNodesgithub.com/Derfuu/Derfuu_ComfyUI_ModdedNodes
Davemane42's Custom
Node for ComfyUI
上文中提到的可视化构图的节点就是来自于这个插件,构图神器,不多解释。
https://github.com/Davemane42/ComfyUI_Dave_CustomNodegithub.com/Davemane42/ComfyUI_Dave_CustomNode
ComfyUI-Custom-Scripts
提供了不少提升使用体验的功能,例如图片自动分割,历史缩略图显示,锁定节点或组,lora文件夹视图,图片自动生成关键字,添加comfyui的平板触控功能,一键自动排版,等等
https://github.com/pythongosssss/ComfyUI-Custom-Scriptsgithub.com/pythongosssss/ComfyUI-Custom-Scripts
ComfyUI Vextra Nodes
添加了一部分图片后处理的节点,和一些优化使用体验的节点,例如,生成时播放音乐,在图片中添加文字,添加Instagram滤镜,使用GPT2 模型帮你自动写prompt(我还没搞懂怎么用这个), 等等。
https://github.com/diontimmer/ComfyUI-Vextra-Nodesgithub.com/diontimmer/ComfyUI-Vextra-Nodes
GitHub
- diontimmer/ComfyUI-Vextra-Nodes: Custom nodes for ComfyUI
https://github.com/diontimmer/ComfyUI-Vextra-Nodesgithub.com/diontimmer/ComfyUI-Vextra-Nodes
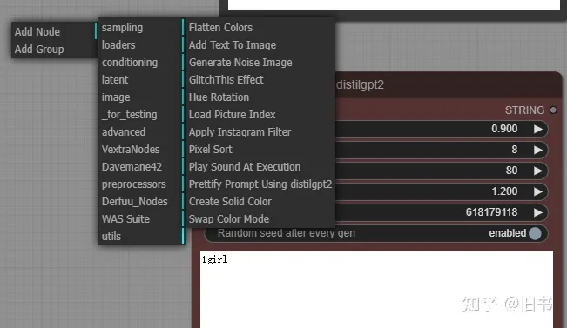
ControlNet
Preprocessors for ComfyUI
添加了 controlnet的预处理器,对,再也不用去PS或者WebUI里面生成controlnet的引导图片了,基本是必备插件
https://github.com/Fannovel16/comfy_controlnet_preprocessorsgithub.com/Fannovel16/comfy_controlnet_preprocessors
ComfyUI-extra-nodes -
quality of life
引入了chatgpt3和DalE-2来辅助图片的生成,我没chatgpt的API,就没能使用这个插件。。。。
https://github.com/omar92/ComfyUI-QualityOfLifeSuit_Omar92github.com/omar92/ComfyUI-QualityOfLifeSuit_Omar92
其他相关:
CushyStudio
基于comfyui的就更加定制化的UI界面,尚在开发中
https://github.com/rvion/CushyStudiogithub.com/rvion/CushyStudio
colab部署
https://github.com/camenduru/comfyui-colabgithub.com/camenduru/comfyui-colab
Docker部署
https://github.com/YanWenKun/ComfyUI-Dockergithub.com/YanWenKun/ComfyUI-Docker
出自:https://zhuanlan.zhihu.com/p/620297462