关于Ai绘画,很多人在体验了Midjourney(以下简称MJ)之后,发现它创意能力很强,但可控性比较弱,不便应用,于是转向Stable
Diffusion(以下简称SD),但又发现SD貌似很复杂。我在后台收得比较多的留言,都是一些很基础的问题咨询,这是这篇文章的写作背景。
Ai绘画的算法工具,如果要做一个不一定准确的类比,可以说MJ是类似Ai美图秀秀般的存在,简单易上手,SD则类似PhotoShop,同样是图片处理,但学习起来要复杂一些,精通相对更难。
这篇文章的目标是作一个简单介绍,帮助新手认识SD,老鸟照样可以略过。
Stable Diffusion的直译是“稳定的扩散”,很多教程一开始就讲“扩散”原理,讲一大堆运行逻辑,令人望而生畏。实际上,我们只需知道母鸡可以产蛋,但并不需要研究母鸡的生殖构造和产蛋原理。同理,普通用户只需知道SD是一个Ai画图算法工具即可。

一、使用环境
SD目前需要在电脑中工作,在使用SD之前,首先要了解它的使用环境。SD和MJ一样可在线使用,不同的是SD是开源的,如果条件允许的话可考虑在本地部署,完全免费,可以非常灵活地配置各种模型等,但对本地硬件要求比较高,比如独立显卡,要求显存一般在8G或以上,普通的办公电脑无法达到要求,需要更高配的台式机或电竞本才可满足。
另外对软件环境也有要求,例如配置Python等。听起来好像很麻烦,实际不然,目前已有各种一键安装包,小白都可轻松安装。
而在线部署的,服务商也会提供具体教程,目前阿里云的SD部署还是比较简单,这里不多讲。如果这些信息都收集不到,恐怕SD也会学不下去。
虽然在线使用需要付费,但投入相对比较少。个人电脑添置一块适合Ai绘画的显卡,基本要几千元起步,而在线租赁的话,普通用户估计一个月几十块百多块的支出就够了。
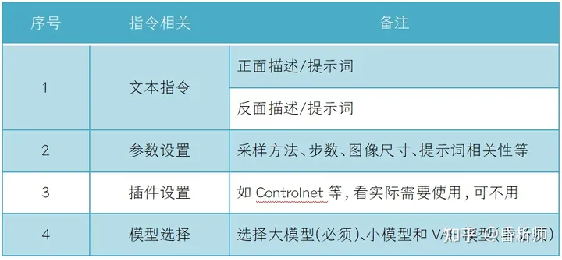
二、使用基础:文本指令
ChatGPT也好,Ai绘画也好,都属于生成式Ai,这类Ai目前有一个特点,需要人工输入指令去引导它工作。我们使用ChatGPT时,需要输入你的问题,它才会回复你。你提出的“问题”,就是使它工作的指令。
Ai绘画和ChatGPT不同的是,不需要提问,但需要你告诉它,你要画什么东西。用过MJ的朋友应该非常理解这个动作,例如,MJ用户需要它画一个女孩,只需要输入对应的英文“A girl”即可。
在SD中,这种方式可行吗?当然可以。但和MJ这种一句话搞定的方式不同,SD的绘画指令和参数明确由多个部分组成,看似繁多但不复杂,也比较容易理解。
这些指令主要属于文本指令,是“文生图”方式。SD还支持同时使用文本+样图,去生成图片或对图片进行修改,这种是“图生图”方式,限于篇幅,暂时不谈。
三、文本指令构成
SD的所有绘画指令,在一个的操作界面(Webui)中完成,界面主体由几个部分组成。
1.具体的“文字”指令
包含2个部分:你想画什么(正面描述)、你不希望画面出现什么(负面/发面描述),下图是SD的Webui文字指令输入界面:
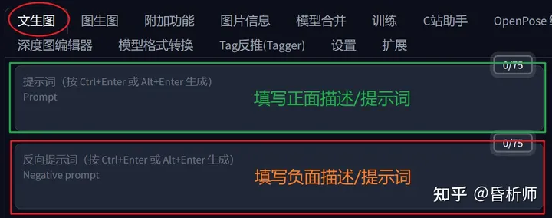
这种指令,和MJ是大体相同的,只不过在MJ中需要一次性输入完毕,而在SD中,要在不同的输入框中分开填写,更加直观。比如说,你希望画“一个漂亮的18岁的女孩”,这是一个正面描述;你希望这个女孩不要出现“多余的手指”,这是一个反面描述。只需要在对应的输入框中填入即可。

文本指令是非常重要的部分,描述得清晰不清晰,出来的画面大相径庭。也需要一些技巧,具体可参阅我之前写的文章。Ai绘画基础技能:念咒——以Stable Diffusion为例
2.参数指令
无需一听“参数”二字就觉得麻烦,就是一个简单的设置。在SD中,基础参数设置主要包括几个地方,如下图:
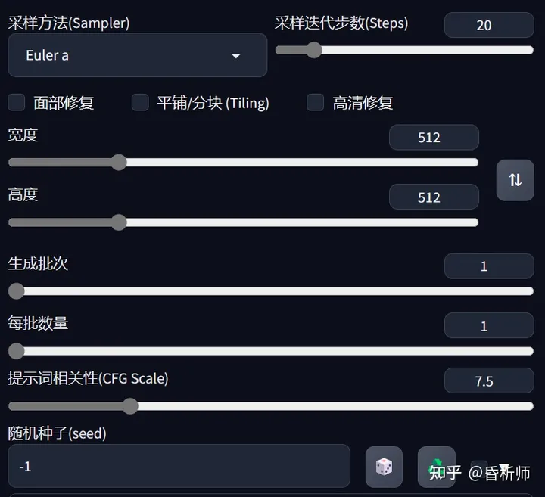
(1)采样方法(Sampler)。这个名词的原本含义解释起来比较拗口,但你可以将它理解为不同的图像渲染方式。不同的采样方法有不同的特长。
有两种用得比较多,第一种是Euler a,生成速度比较快,适合于二次元、小场景和图标等画面生成。第二种是DPM++2S a Karras,适合写实人像,复杂场景等画面生成。其它的采样方法,自己可以探索,实践生成一下可看到它们之间的差异。
(2)采样迭代步数(Steps),这个步数值影响图像的细节,一般来说,建议20起步,越大代表图像越精细,但并不是越大越好,需要在实践中结合不同的模型去观察。区间在20-40比较常见。
(3)修复。这里常用的是“面部修复”和“高清修复”两个选项。
在画“真人”的时候,勾选前者会显著影响人脸细节,可以生成更好的人脸。后者主要是用来高清放大。因为硬件条件有限,很多电脑更适合生成小尺寸图像,勾选这个选项时,可以对生成的小图进行高清放大。
但需要指出的是,放大的尺寸并非无限,普通配置的电脑,长宽放大到1500*1500几乎已是极限,而且,放大的图片和小图风格一致但细节有差别,这个可以在实践中对照。

(4)图片的长宽设置。最容易理解的一个选项。
(5)生成批次及每批数量设置。这2个数值很考验显卡计算能力,以8g显存为例,建议批次设置为3(一次生成3批),每批数量为1,总共3张图片。每批数量的值越大,对显卡的压力越大,一般建议保留默认数值1。
(6)提示词相关性(CFG Scale)、随机种子(seed)
相关性值可以设置为1-30,值越小,生成的图片和你输入的文本指令的吻合度越低,越大则越高。但并不是越大/越小越好。一般情况下,画人物时这个值在7-10之间是比较平衡的,画建筑一般是4-8之间,需要在实践结合不同的模型去观察。以下是一些参考:
当CFG处于2-6时,Ai发挥想象力空间大,不可控性提高。
当CFG处于10-15时,你的作品受到你的提示的良性影响。
当CFG处于16-20时,你得确定你的提示词真的是你想要的,否则效果不会太好。当CFG高于20时,可能会产生一些奇怪的现象。
另一个是种子值,这是一个可以锁定生成图像的初始状态的值,一般设置为-1,意味着随机生成。当你使用了一个固定的seed值(非-1),并使用了其它相同的参数和指令时,会得到一张几乎完全一样的图片。
需要指出的是,即使所有的设置一样,在不同的显卡下,生成图片的细节差别可能会比较大。
四、模型选择
模型选择实际上也属于“指令”的组成部分,这里单列出来说。模型是Ai绘画中一个基础设施,决定生成画面的元素、风格、画风等。有些像PPT一样,你采用不同的模板,呈现的就是不同的画面风格。
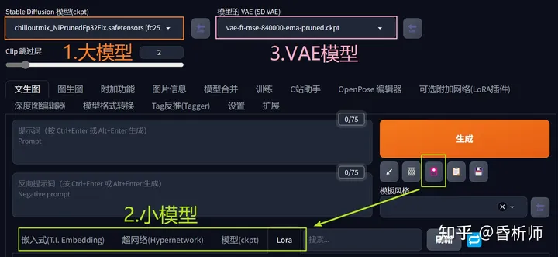
从上图操作界面中可以看到,常用模型主要有3种。
(1)大模型:指SD绘图的基础模型,也叫大模型/底模。SD必须搭配大模型才能使用。大模型决定画面的主要风格,不同的大模型擅长的领域会有侧重,比如,有些擅长画漫画,有些是真人、建筑、国风等。
(2)小模型:常用的主要指Lora模型,属于微调模型,必须结合大模型使用,通过不同的权重影响画面特征。有人说,大模型相当于素颜,小模型相当于化妆,在某种程度上的确可以这么理解。
Lora模型由于训练简单效果显著,得到广泛应用,但这种小模型并不是必须的,很多大模型本身就带有很好的“化妆”效果。所不同的是,小模型和大模型同时使用的时候,可以调整出大模型无法达到的叠加优化效果。
(3)VAE模型。可以理解为滤镜,用于调节和美化。同样的,它也不是必须的,依据个人绘画需要决定是否采用。也有例外,个别大模型由于训练效果等问题,会明确提示要结合VAE使用。VAE图片结果例:

(4)其它模型:Embeddings、Hypernetworks、LyCORIS、DreamBooth(微调大模型)模型,这些对初学者来说,很少有机会用到,以后再讲。
(5)模型从哪里来
要达到比较好的画面效果,必须通过训练得到绘画模型。初学者更多的是使用别人训练好的。在C站上,有大量免费共享模型,需要“科学上网”才可下载。熟练使用之后,也可以自己训练私有模型。模型训练需要较好的硬件支撑,以及一些高质量的训练素材等,另文讨论。
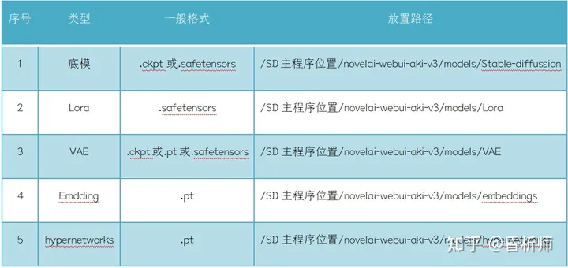
上述模型放在什么地方:
五、绘画插件
在一些时候,单纯依靠文本指令,并不能画出我们想要的画面,这个时候就需要使用SD插件。插件是SD绘画可以进入应用层面的、非常重要的一个部分。
SD目前最常用、最强大的插件,一般认为是Controlnet插件。它可以控制人物表情、姿势、手势等,可以识别景深、线条,并生成文本指令无法实现的要素,诸如此类。这个插件也需要另开一篇专门的文章才可讲清楚。
下图是一个按骨骼图生成人物的图例:

这种的插件,意味着SD绘画拥有较高的“可控性”能力。这是其它Ai绘画工具目前无法比拟的,也意味着其更加接近商业层面的应用。
一些插件控制应用效果,可参看我之前写的部分案例。比如:Ai绘画:建筑外观及室内设计尝试 Ai绘画:动漫/游戏人物形象尝试
了解了上述主要界面元素和指令之后,对SD生成图片基本就算是有了一个基础认识,大家也可以看到,它虽然指令和参数比较多,但理解起来并不困难。
最后小结一下,SD的文生图绘画指令从整体来看,主要包含了以下内容:
出自:https://zhuanlan.zhihu.com/p/635369317