ΖΰΈώΤςΉΦ±Η
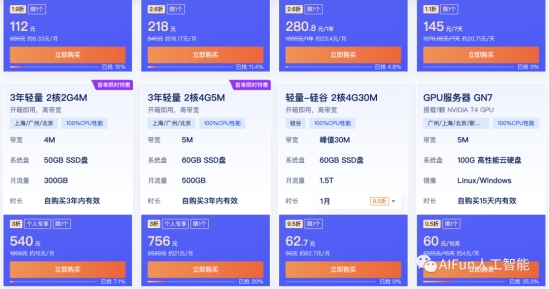
≤Μœκ’έΧΎmacΝΥΘ§’ΐΚΟΧΎ―Ε‘Τ”–ΜνΕ·Θ§GPUΖΰΈώΤςΘ§8ΚΥ32GΡΎ¥φ16Gœ‘¥φΘ§60Ωι«°ΑκΗω‘¬Θ§Η’ΚΟ¬ρά¥ ‘ ‘Θ§ΜνΕ·Ν¥Ϋ”‘ΎΫαΈ≤¥ΠΓΘ
≤ιΩ¥ΖΰΈώΤς≈δ÷Ο
ΙΚ¬ρΆξ≥…Κσ ’ΦΰœδΜα ’ΒΫ’ΨΡΎœϊœΔΘ§ΑϋΚ§ΜζΤς≈δ÷ΟΚΆΟή¬κΘ§Ϋχ»κΖΰΈώΤςΚσ δ»κΟϋΝνΘ§Ω…“‘Ω¥ΒΫœΒΆ≥÷–Α≤ΉΑΒΡ NVIDIA œ‘Ω®ΒΡ Β ±–≈œΔΚΆΉ¥Χ§ΓΘ
nvidia-smi
 image-20230804134407122
image-20230804134407122
Α≤ΉΑpython
…ΐΦΕ“Μœ¬œΒΆ≥Ρ§»œΒΡpythonΑφ±ΨΘ§¥Υ¥Π Ι”ΟpyenvΓΘ
Α≤ΉΑpyenv
curl https://pyenv.run | bash
# Α≤ΉΑœύ”Π“άάΒ
yum install gcc zlib-devel bzip2 bzip2-devel readline readline-devel sqlite sqlite-devel openssl openssl-devel git libffi-devel
# Α≤ΉΑ»μΦΰΩβΘ§Ζώ‘ρΈόΖ®Α≤ΉΑopenssl11
yum install epel-release
# Α≤ΉΑ–¬Αφ±ΨΒΡopenssl
yum install openssl11 openssl11-devel
# …η÷Ο±ύ“κFLAGΘ§“‘±ψ Ι”ΟΉν–¬ΒΡopensslΩβ
export CFLAGS=$(pkg-config --cflags openssl11)
export LDFLAGS=$(pkg-config --libs openssl11)
# Α≤ΉΑpython3.10
pyenv install 3.10.4
# ≤ιΩ¥“―”–ΜΖΨ≥Αφ±Ψ
pyenv versions
# »ΪΨ÷«–ΜΜ 3.10.4 Αφ±Ψ
pyenv global 3.10.4
œ¬‘Ί‘¥¬κ
https://github.com/THUDM/ChatGLM2-6B
Ϋχ»κœνΡΩΡΩ¬ΦΘ§¥¥Ϋ®–ιΡβΜΖΨ≥ΓΘ
python -m venv env
# Ϋχ»κ–ιΡβΜΖΨ≥
source env/bin/activate
# Α≤ΉΑœύΙΊ“άάΒ
pip install -f requirements.txt
# ΆΥ≥ω–ιΡβΜΖΨ≥
deactivate
tree -L 2Ω¥“Μœ¬ΡΩ¬ΦΫαΙΙΘΚptuning ΡΩ¬Φ «ΡΘ–Ά―ΒΝΖΒΡœύΙΊ¥ζ¬κ
©ά©Λ©Λ FAQ.md
©ά©Λ©Λ MODEL_LICENSE
©ά©Λ©Λ README.md
©ά©Λ©Λ README_EN.md
©ά©Λ©Λ api.py
©ά©Λ©Λ cli_demo.py
©ά©Λ©Λ evaluation
©Π ©ά©Λ©Λ README.md
©Π ©Η©Λ©Λ evaluate_ceval.py
©ά©Λ©Λ openai_api.py
©ά©Λ©Λ ptuning
©Π ©ά©Λ©Λ README.md
©Π ©ά©Λ©Λ arguments.py
©Π ©ά©Λ©Λ deepspeed.json
©Π ©ά©Λ©Λ ds_train_finetune.sh
©Π ©ά©Λ©Λ evaluate.sh
©Π ©ά©Λ©Λ evaluate_finetune.sh
©Π ©ά©Λ©Λ main.py
©Π ©ά©Λ©Λ train.sh
©Π ©ά©Λ©Λ train_chat.sh
©Π ©ά©Λ©Λ trainer.py
©Π ©ά©Λ©Λ trainer_seq2seq.py
©Π ©ά©Λ©Λ web_demo.py
©Π ©Η©Λ©Λ web_demo.sh
©ά©Λ©Λ requirements.txt
©ά©Λ©Λ resources
©Π ©ά©Λ©Λ WECHAT.md
©Π ©ά©Λ©Λ cli-demo.png
©Π ©ά©Λ©Λ knowledge.png
©Π ©ά©Λ©Λ long-context.png
©Π ©ά©Λ©Λ math.png
©Π ©ά©Λ©Λ web-demo.gif
©Π ©ά©Λ©Λ web-demo2.gif
©Π ©Η©Λ©Λ wechat.jpg
©ά©Λ©Λ utils.py
©ά©Λ©Λ web_demo.py
©Η©Λ©Λ web_demo2.py
¥ζ¬κ Βœ÷ΝΥΕ‘”Ύ ChatGLM2-6B ΡΘ–ΆΜυ”Ύ P-Tuning v2 ΒΡΈΔΒςΓΘP-Tuning v2 ΫΪ–η“ΣΈΔΒςΒΡ≤Έ ΐΝΩΦθ…ΌΒΫ‘≠ά¥ΒΡ 0.1%Θ§‘ΌΆ®ΙΐΡΘ–ΆΝΩΜ·ΓΔGradient Checkpoint Β»ΖΫΖ®Θ§ΉνΒΆ÷Μ–η“Σ 7GB œ‘¥φΦ¥Ω…‘Υ––ΓΘ
≤Ο¥ «P-tuning-v2
Έ“Ο«»Οclaude.aiΫβ Ά“Μœ¬ΘΚ
P-tuning-v2 «Μυ”ΎPrompt-tuningΖΫΖ®ΒΡNLPΡΘ–ΆΈΔΒςΦΦ θΓΘ
P-tuningΒΡ»Ϊ≥Τ «Prefix-tuning,“βΈΣΓΑ«ΑΉΚΒς”≈Γ±ΓΘΥϋΆ®Ιΐ‘ΎΡΘ–Ά δ»κ«ΑΧμΦ”–ΓΕΈDiscrete prompt(άύΥΤΧνΩ’Ψδ),≤Δ÷Μ”≈Μ·’βΗωpromptά¥ Βœ÷ΡΘ–ΆΈΔΒςΓΘ
P-tuning-v2œύΫœ”Ύv1Αφ±Ψ÷ς“Σ”–“‘œ¬ΗΡΫχ:
o
• ÷ß≥÷Ν§–χPrompt,Φ¥Ω…“‘’κΕ‘≤ΜΆ§inputΕ·Χ§…ζ≥…prompt,Εχ≤Μ «ΙΧΕ®ΒΡDiscrete promptΓΘ
o
o
• ÷ß≥÷‘ΎpromptΚσΫ”text,Εχ≤ΜΫω «Ϋ”[MASK]ΓΘ
o
o
• promptΩ…“‘Ή‘Ε®“ε≥θ ΦΜ·,≤Δ‘ΎΈΔΒς÷–Ϋχ––”≈Μ·ΓΘ
o
o
• ‘ωΦ”ΝΥΉ‘Ε·―ßœΑprompt≥ΛΕ»ΒΡΜζ÷ΤΓΘ
o
o
• ÷ß≥÷Prompt…ζ≥…ΓΘ
o
o
• –ßΙϊ…œ,P-tuning-v2œύ±»v1Χα…ΐΗϋΟςœ‘,–߬ “≤”–Κή¥σΧα…ΐΓΘ
o
ΉήΧεά¥ΥΒ,P-tuning-v2 «Prompt tuningΦΦ θΒΡ…ΐΦΕΑφ±Ψ, ΙΒΟPromptΒΡ±μ ΨΡήΝΠΗϋ«Ω,”Π”Ο“≤ΗϋΝιΜνΙψΖΚΓΘΥϋ±Μ»œΈΣ «Prompt tuningάύΖΫΖ®÷––ßΙϊΉν”≈«““Ή”Ο–‘ΉνΚΟΒΡΑφ±ΨΓΘ
œ¬Οφ“‘Ή‘ΦΚΒΡ ΐΨίΦ·ΈΣάΐΫι…ή¥ζ¬κΒΡ Ι”ΟΖΫΖ®ΓΘ
»μΦΰ“άάΒ
‘Υ––ΈΔΒς≥ΐ ChatGLM2-6B ΒΡ“άάΒ÷°ΆβΘ§ΜΙ–η“ΣΑ≤ΉΑ“‘œ¬“άάΒ
pip install rouge_chinese nltk jieba datasets
ΉΦ±Η ΐΨίΦ·
Ω…“‘≤ΈΩΦΙΌΖΫ Ψάΐ÷ΤΉςΉ‘ΦΚΒΡ ΐΨίΦ·ΘΚ
ΙΌΖΫADGEN ΐΨίΦ· Ψάΐ «ΗυΨί δ»κΘ®contentΘ©…ζ≥…“ΜΕΈΙψΗφ¥ Θ®summaryΘ©ΓΘΩ…“‘¥” Google Drive Μρ’Ώ Tsinghua Cloud œ¬‘Ί¥ΠάμΚΟΒΡ ADGEN ΐΨίΦ·Θ§ΫΪΫβ―ΙΚσΒΡ AdvertiseGen ΡΩ¬ΦΖ≈ΒΫptuningΡΩ¬Φœ¬ΓΘ
Ω…“‘Ω¥ΒΫΫβ―ΙΚσΒΡΈΡΦΰ”–ΝΫΗωΘ§Ζ÷±π «train.jsonΚΆdev.jsonΓΘ
o
• train.jsonΈΡΦΰ «”Ο”Ύ―ΒΝΖΡΘ–ΆΒΡ ΐΨίΦ·,άοΟφΑϋΚ§ΝΥ–μΕύΡΘΡβΒΡ”ΟΜßΈ ¥πΕ‘,Ηώ Ϋ»γΡζΥυ ω,ΟΩΗω―υ±ΨΑϋΚ§“ΜΗω"content"Φϋ±μ ΨΈ ΧβΈΡ±Ψ,"summary"Φϋ±μ ΨΕ‘”ΠΒΡ¥πΑΗΈΡ±ΨΓΘ
o
o
• dev.jsonΈΡΦΰ“≤ «“Μ―υΒΡΗώ Ϋ,ΒΪ «Υϋ «”Ο”Ύ―ι÷ΛΒΡ,Μα‘Ύ―ΒΝΖΙΐ≥Χ÷–”Ο”ΎΤάΙάΡΘ–Ά‘Ύ’β≤ΩΖ÷ ΐΨί…œΒΡ±μœ÷ΓΘ
o
{
"content": "άύ–Ά#…œ“¬*Αφ–Ά#ΩμΥ…*Αφ–Ά#œ‘ ί*ΆΦΑΗ#œΏΧθ*“¬―υ Ϋ#≥Ρ…ά*“¬–δ–Ά#≈ί≈ί–δ*“¬Ων Ϋ#≥ι…ΰ",
"summary": "’βΦΰ≥Ρ…άΒΡΩν ΫΖ«≥ΘΒΡΩμΥ…Θ§άϊ¬δΒΡœΏΧθΩ…“‘ΚήΚΟΒΡ“ΰ≤Ί…μ≤Ρ…œΒΡ–Γ»±ΒψΘ§¥©‘Ύ…μ…œ”–Ή≈ΚήΚΟΒΡœ‘ ί–ßΙϊΓΘΝλΩΎΉΑ ΈΝΥ“ΜΗωΩ…Α°ΒΡ≥ι…ΰΘ§Τ·ΝΝΒΡ…ΰΫα’Ιœ÷≥ωΝΥ °ΉψΒΡΗω–‘Θ§≈δΚœ ±…–ΒΡ≈ί≈ί–δ–ΆΘ§ΨΓœ‘≈°–‘ΧπΟάΩ…Α°ΒΡΤχœΔΓΘ"
}
’βάοΈ“ Ι”ΟΉ‘ΦΚΒΡ ΐΨίΦ·Θ§ ΐΨίΦ·ά¥‘¥ «“ΜΖί≤ΌΉς ÷≤ΌΘ§ Ι”ΟClaude…ζ≥…ΡΩ±ξΗώ ΫΒΡtrain.jsonΚΆdev.jsonΘ§ ΐΨίΨΌάΐ
{
"content": "–όΗΡ“ΒΈώΩΆΜß–≈œΔΒΡ≤Ϋ÷η « ≤Ο¥?",
"summary": "‘ΎΩΆΖΰΙήάμ-ΩΆΜßΙήάμ-“ΒΈώΩΆΜß–≈œΔ“≥Οφ,―Γ‘ώ–η“Σ–όΗΡΒΡΩΆΜß,ΒψΜς–όΗΡΑ¥≈Ξ,‘ΎΒ·≥ωΒΡ–όΗΡ“≥ΟφΧν–¥ΩΆΜß–¬ΒΡΟϊ≥ΤΓΔΝΣœΒ»ΥΓΔΒΊ÷ΖΒ»–≈œΔ,»ΜΚσΒψΜς“≥Οφœ¬ΖΫΒΡ±Θ¥φΑ¥≈Ξ,Φ¥Ω…Άξ≥…ΩΆΜß–≈œΔΒΡ–όΗΡΓΘ"
}
–όΗΡ“Μ–©¥ζ¬κ
–όΗΡtrain.sh
# ’βΝΫ¥ΠΗΡΈΣΉ‘ΦΚ ΐΨίΦ·ΒΡ¬ΖΨΕ
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
# ΐΨίΦ·…ΌΒΡΜΑΘ§―ΒΝΖ≤Ϋ ΐΩ…“‘Βς–ΓΘ§Έ“ΗΡΈΣΝΥ100
--max_steps 3000
–όΗΡmain.py
‘Ύ¥ζ¬κΒΡ351––Θ§¥ζ¬κΉΔ ΆΒτΝΥ trainer.save_model(),’β «±Θ¥φΡΘ–ΆΒΡ”οΨδΓΘΒ±―ΒΝΖΆξ≥…ΚσΨΆΜα…ζ≥…“ΜΗωpytorch_model.binΈΡΦΰΘ§ΚσΟφΜα”ΟΒΫΓΘ
ΫβΩΣ’βάοΒΡΉΔ ΆΘΚ
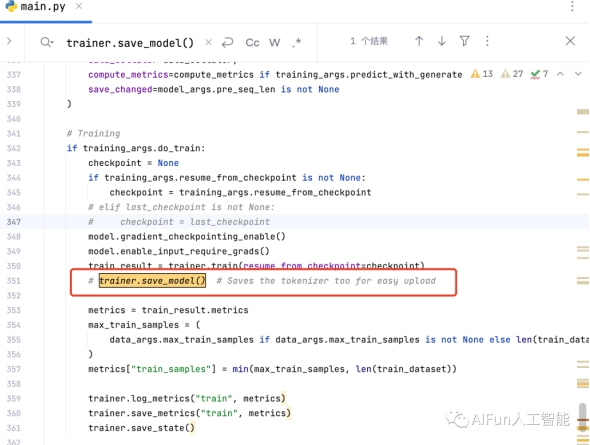 image-20230805174737559
image-20230805174737559
―ΒΝΖP-Tuning v2
‘Υ––“‘œ¬÷ΗΝνΫχ––―ΒΝΖΘΚ
./train.sh
train.sh ÷–ΒΡ PRE_SEQ_LEN ΚΆ LR Ζ÷±π « soft prompt ≥ΛΕ»ΚΆ―ΒΝΖΒΡ―ßœΑ¬ Θ§Ω…“‘Ϋχ––ΒςΫΎ“‘»ΓΒΟΉνΦ―ΒΡ–ßΙϊΓΘP-Tuning-v2 ΖΫΖ®ΜαΕ≥Ϋα»Ϊ≤ΩΒΡΡΘ–Ά≤Έ ΐΘ§Ω…Ά®ΙΐΒς’ϊ quantization_bit ά¥±Μ‘≠ ΦΡΘ–ΆΒΡΝΩΜ·Β»ΦΕΘ§≤ΜΦ”¥Υ―Γœν‘ρΈΣ FP16 ΨΪΕ»Φ”‘ΊΓΘ
‘ΎΡ§»œ≈δ÷Ο quantization_bit=4ΓΔper_device_train_batch_size=1ΓΔgradient_accumulation_steps=16 œ¬Θ§INT4 ΒΡΡΘ–Ά≤Έ ΐ±ΜΕ≥ΫαΘ§“Μ¥Έ―ΒΝΖΒϋ¥ζΜα“‘ 1 ΒΡ≈ζ¥Πάμ¥σ–ΓΫχ–– 16 ¥ΈάέΦ”ΒΡ«ΑΚσœρ¥Ϊ≤ΞΘ§Β»–ßΈΣ 16 ΒΡΉή≈ζ¥Πάμ¥σ–ΓΘ§¥Υ ±ΉνΒΆ÷Μ–η 6.7G œ‘¥φΓΘ»τœκ‘ΎΆ§Β»≈ζ¥Πάμ¥σ–Γœ¬Χα…ΐ―ΒΝΖ–ß¬ Θ§Ω…‘ΎΕΰ’Ώ≥ΥΜΐ≤Μ±δΒΡ«ιΩωœ¬Θ§Φ”¥σ per_device_train_batch_size ΒΡ÷ΒΘ§ΒΪ“≤Μα¥χά¥ΗϋΕύΒΡœ‘¥φœϊΚΡΘ§«κΗυΨί ΒΦ «ιΩωΉΟ«ιΒς’ϊΓΘ
»γΙϊΡψœκ“Σ¥”±ΨΒΊΦ”‘ΊΡΘ–ΆΘ§Ω…“‘ΫΪ train.sh ÷–ΒΡ THUDM/chatglm2-6b ΗΡΈΣΡψ±ΨΒΊΒΡΡΘ–Ά¬ΖΨΕΓΘ
’β «ΩΊ÷ΤΧ® δ≥ω
[INFO|trainer.py:1786] 2023-08-05 19:34:17,764 >> ***** Running training *****
[INFO|trainer.py:1787] 2023-08-05 19:34:17,764 >> Num examples = 38
[INFO|trainer.py:1788] 2023-08-05 19:34:17,764 >> Num Epochs = 50
[INFO|trainer.py:1789] 2023-08-05 19:34:17,764 >> Instantaneous batch size per device = 1
[INFO|trainer.py:1790] 2023-08-05 19:34:17,764 >> Total train batch size (w. parallel, distributed & accumulation) = 16
[INFO|trainer.py:1791] 2023-08-05 19:34:17,764 >> Gradient Accumulation steps = 16
[INFO|trainer.py:1792] 2023-08-05 19:34:17,764 >> Total optimization steps = 100
[INFO|trainer.py:1793] 2023-08-05 19:34:17,765 >> Number of trainable parameters = 1,835,008
0%| | 0/100 [00:00<?, ?it/s]08/05/2023 19:34:17 - WARNING - transformers_modules.THUDM.chatglm2-6b.b1502f4f75c71499a3d566b14463edd62620ce9f.modeling_chatglm - `use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...
{'loss': 3.0614, 'learning_rate': 0.018000000000000002, 'epoch': 4.21}
{'loss': 2.2158, 'learning_rate': 0.016, 'epoch': 8.42}
{'loss': 1.6043, 'learning_rate': 0.013999999999999999, 'epoch': 12.63}
{'loss': 1.1897, 'learning_rate': 0.012, 'epoch': 16.84}
41%|®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ä®Ö | 41/100 [08:52<12:45, 12.97s/it]
÷ς“ΣΑϋΚ§“‘œ¬–≈œΔ:
1.
1. ‘Ύ*** Running training ***œ¬Οφ¥ρ”Γ≥ω―ΒΝΖ ΐΨίΦ·―υ±Ψ ΐΝΩ(Num examples)ΓΔ―ΒΝΖ¬÷ ΐ(Num Epochs)Β»≥§≤Έ ΐΓΘ
2.
3.
2. «Α4––¥ρ”ΓΝΥbatch sizeΦΑ”≈Μ·–≈œΔ,»γΟΩ…η±Ηbatch sizeΓΔΉήbatch sizeΓΔΧίΕ»άέΜΐ≤Ϋ ΐΓΔΉή”≈Μ·≤Ϋ ΐΒ»ΓΘ
4.
5.
3. ¥ρ”ΓΝΥΡΘ–ΆΒΡ≤Έ ΐΝΩ(Number of trainable parameters),’βάο «1.8“Ύ≤Έ ΐΓΘ
6.
7.
4. ¥ρ”ΓΝΥ“ΜΧθΨ·Ηφ–≈œΔ,Χα Ψ≤ΜΦφ»ίΒΡ…η÷Ο,“―Ή‘Ε·ΗϋΗΡΓΘ
8.
9.
5. Ϋ”œ¬ά¥ΟΩΗτΦΗ¬÷¥ρ”Γ“Μ¥ΈΒ±«ΑΒΡ―ΒΝΖlossΓΔ―ßœΑ¬ ΚΆepoch–≈œΔ,Ω…“‘Ω¥ΒΫloss”–œ¬ΫΒΒΡ«ς ΤΓΘΦθ–ΓΒΡLoss±μ ΨΡΘ–Ά―ΒΝΖ «”––ßΒΡ,–‘ΡήΒΟΒΫΝΥΧα…ΐ
10.
11.
6. ΉνΚσ“Μ––¥ρ”ΓΒ±«ΑΒΡ―ΒΝΖΫχΕ»,’βάο“―Ψ≠―ΒΝΖΝΥ41≤Ϋ,ΉήΦΤ100≤Ϋ,ΟΩΗωstepΚΡ ±‘Φ13ΟκΓΘ
12.
13.
7. ÷–ΦδΒΡΫχΕ»Χθ“≤÷±Ιέœ‘ Ψ―ΒΝΖΫχΕ»ΓΘ
14.
―ΒΝΖΆξ≥…
Saving PrefixEncoder
[INFO|configuration_utils.py:458] 2023-08-05 19:55:56,218 >> Configuration saved in output/adgen-chatglm2-6b-pt-128-2e-2/config.json
[INFO|configuration_utils.py:364] 2023-08-05 19:55:56,218 >> Configuration saved in output/adgen-chatglm2-6b-pt-128-2e-2/generation_config.json
[INFO|modeling_utils.py:1853] 2023-08-05 19:55:56,233 >> Model weights saved in output/adgen-chatglm2-6b-pt-128-2e-2/pytorch_model.bin
[INFO|tokenization_utils_base.py:2194] 2023-08-05 19:55:56,233 >> tokenizer config file saved in output/adgen-chatglm2-6b-pt-128-2e-2/tokenizer_config.json
[INFO|tokenization_utils_base.py:2201] 2023-08-05 19:55:56,233 >> Special tokens file saved in output/adgen-chatglm2-6b-pt-128-2e-2/special_tokens_map.json
***** train metrics *****
epoch = 42.11
train_loss = 1.0075
train_runtime = 0:21:38.44
train_samples = 38
train_samples_per_second = 1.232
train_steps_per_second = 0.077
Finetune
»γΙϊ–η“ΣΫχ––»Ϊ≤Έ ΐΒΡ FinetuneΘ§–η“ΣΑ≤ΉΑ DeepspeedΘ§»ΜΚσ‘Υ––“‘œ¬÷ΗΝνΘΚ
bash ds_train_finetune.sh
―ΒΝΖΆξ≥…ΚσΒΡoutputΡΩ¬ΦΈΡΦΰΘΚ
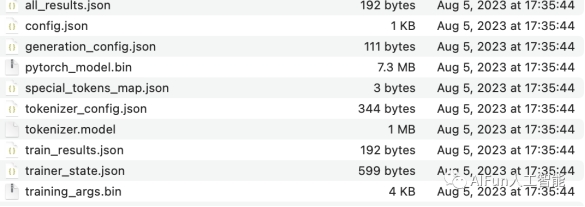 image-20230805174618513
image-20230805174618513
≤β ‘
–όΗΡweb_demo.shΒΡptuning_checkpoint≤Έ ΐ
PRE_SEQ_LEN=128
CUDA_VISIBLE_DEVICES=0 python3 web_demo.py \
--model_name_or_path THUDM/chatglm2-6b \
--ptuning_checkpoint output/adgen-chatglm2-6b-pt-128-2e-2/ \
--pre_seq_len $PRE_SEQ_LEN
ΈΣ ≤Ο¥“Σ–όΗΡΘ§Ω…“‘Ω¥’βάοΘ§–η“ΣΦ”‘ΊΒΡ P-Tuning ΒΡ checkpointΘΚ
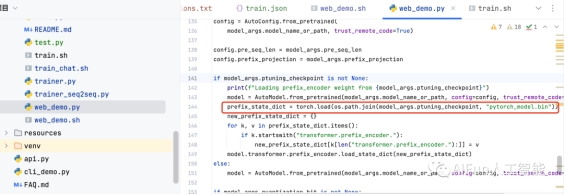 image-20230805200855314
image-20230805200855314
./web_demo.sh
Running on local URL: http://127.0.0.1:7860
Έ“’βάο Ι”ΟΝΥnginxΫχ––¥ζάμΘΚ
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://127.0.0.1:7860;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
}
}
δ»κΖΟΈ ΒΊ÷ΖΘ§Ϋχ––≤β ‘Θ§≥…ΙΠΘΓ
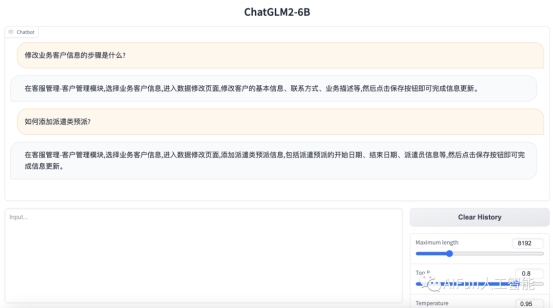 image-20230805200030528
image-20230805200030528
ΆΤάμ
‘Ύ P-tuning v2 ―ΒΝΖ ±ΡΘ–Ά÷Μ±Θ¥φ PrefixEncoder ≤ΩΖ÷ΒΡ≤Έ ΐΘ§Υυ“‘‘ΎΆΤάμ ±–η“ΣΆ§ ±Φ”‘Ί‘≠ ChatGLM2-6B ΡΘ–Ά“‘ΦΑ PrefixEncoder ΒΡ»®÷ΊΘ§“ρ¥Υ–η“Σ÷ΗΕ® evaluate.sh ÷–ΒΡ≤Έ ΐΘΚ
--model_name_or_path THUDM/chatglm2-6b
--ptuning_checkpoint $CHECKPOINT_PATH
‘Υ––evaluate.shΘ§Β»Άξ≥…ΚσΜα δ≥ωΘΚ
***** predict metrics *****
predict_bleu-4 = 32.536
predict_rouge-1 = 58.1861
predict_rouge-2 = 31.1951
predict_rouge-l = 49.2416
predict_runtime = 0:04:09.78
predict_samples = 38
predict_samples_per_second = 0.152
predict_steps_per_second = 0.152
…ζ≥…ΒΡΫαΙϊ±Θ¥φ‘Ύ ./output/adgen-chatglm2-6b-pt-128-2e-2/generated_predictions.txtΓΘΫαΙϊ ΨάΐΘΚ
{"labels": " Ήœ»Ϋχ»κΩΆΖΰΙήάμœΒΆ≥,¥ρΩΣ“ΒΈώΩΆΜß–≈œΔΙήάμ“≥Οφ,‘ΎΝ–±μ÷–’“ΒΫ–η“Σ–όΗΡΒΡΩΆΜß,»ΜΚσΒψΜς”“±ΏΒΡ–όΗΡΑ¥≈Ξ¥ρΩΣ–όΗΡ¥ΑΩΎ,‘Ύ¥ΑΩΎ÷–Ω…“‘–όΗΡΩΆΜßΒΡΟϊ≥ΤΓΔΝΣœΒ»Υ–≈œΔΓΔΒΊ÷ΖΒ»ΡΎ»ί,–όΗΡΆξ≥…ΚσΒψΜς±Θ¥φΑ¥≈Ξ,’β―υΨΆΩ…“‘Ηϋ–¬ΩΆΜßΒΡΉν–¬–≈œΔ,Άξ≥…–όΗΡ≤ΌΉς",
"predict": "‘ΎΩΆΖΰΙήάμ-ΩΆΜßΙήάμ-“ΒΈώΩΆΜß–≈œΔ“≥Οφ,―Γ‘ώ–η“Σ–όΗΡΒΡΩΆΜß,ΒψΜς–όΗΡΑ¥≈Ξ,‘ΎΒ·≥ωΒΡ–όΗΡ“≥ΟφΧν–¥ΩΆΜß–¬ΒΡΟϊ≥ΤΓΔΝΣœΒ»ΥΓΔΒΊ÷ΖΒ»–≈œΔ,»ΜΚσΒψΜς“≥Οφœ¬ΖΫΒΡ±Θ¥φΑ¥≈Ξ,Φ¥Ω…Άξ≥…ΩΆΜß–≈œΔΒΡ–όΗΡΓΘ"}
ΆΤάμΚσ…ζ≥…ΒΡΈΡΦΰ
 image-20230805183856057
image-20230805183856057
Ε‘ΜΑ ΐΨίΦ·
»γ–η“Σ Ι”ΟΕύ¬÷Ε‘ΜΑ ΐΨίΕ‘ΡΘ–ΆΫχ––ΈΔΒςΘ§Ω…“‘ΧαΙ©ΝΡΧλάζ ΖΘ§άΐ»γ“‘œ¬ «“ΜΗω»ΐ¬÷Ε‘ΜΑΒΡ―ΒΝΖ ΐΨίΘΚ
{"prompt": "≥Λ≥«h3Ζγ…»≤ΜΉΣΓΘΦΧΒγΤςΚΟΒΡΓΘ±Θœ’ΥΩΚΟΒΡ¥ΪΗ–Τς–¬ΒΡΖγ…»“≤–¬ΒΡ’β «ΈΣ ≤Ο¥ΓΘΨΆ «ΦΧΒγΤς»±“ΜΗω–≈Κ≈œΏ", "response": "”ΟΒγΡ‘ΡήΕΝ ΐΨίΝς¬πΘΩΥ°Έ¬Εύ…Ό", "history": []}
{"prompt": "95", "response": "…œœ¬Υ°ΙήΈ¬≤ν‘θΟ¥―υΑΓΘΩΩ’Τχ «≤Μ «ΕΦ≈≈Η…ΨΜΝΥΡΊΘΩ", "history": [["≥Λ≥«h3Ζγ…»≤ΜΉΣΓΘΦΧΒγΤςΚΟΒΡΓΘ±Θœ’ΥΩΚΟΒΡ¥ΪΗ–Τς–¬ΒΡΖγ…»“≤–¬ΒΡ’β «ΈΣ ≤Ο¥ΓΘΨΆ «ΦΧΒγΤς»±“ΜΗω–≈Κ≈œΏ", "”ΟΒγΡ‘ΡήΕΝ ΐΨίΝς¬πΘΩΥ°Έ¬Εύ…Ό"]]}
{"prompt": " «ΒΡΓΘ…œœ¬Υ°ΙήΕΦΚΟΒΡ", "response": "Ρ«ΨΆ“ΣΦλ≤ιœΏ¬ΖΝΥΘ§“ΜΑψΖγ…»ΦΧΒγΤς «”…ΒγΡ‘ΩΊ÷ΤΈϋΚœΒΡΘ§»γΙϊΒγ¬Ζ¥φ‘ΎΕœ¬ΖΘ§Μρ’ΏΒγΡ‘ΜΒΝΥΒΡΜΑΜα≥ωœ÷ΦΧΒγΤς≤ΜΈϋΚœΒΡ«ιΩωΘΓ", "history": [["≥Λ≥«h3Ζγ…»≤ΜΉΣΓΘΦΧΒγΤςΚΟΒΡΓΘ±Θœ’ΥΩΚΟΒΡ¥ΪΗ–Τς–¬ΒΡΖγ…»“≤–¬ΒΡ’β «ΈΣ ≤Ο¥ΓΘΨΆ «ΦΧΒγΤς»±“ΜΗω–≈Κ≈œΏ", "”ΟΒγΡ‘ΡήΕΝ ΐΨίΝς¬πΘΩΥ°Έ¬Εύ…Ό"], ["95", "…œœ¬Υ°ΙήΈ¬≤ν‘θΟ¥―υΑΓΘΩΩ’Τχ «≤Μ «ΕΦ≈≈Η…ΨΜΝΥΡΊΘΩ"]]}
―ΒΝΖ ±–η“Σ÷ΗΕ® --history_column ΈΣ ΐΨί÷–ΝΡΧλάζ ΖΒΡ keyΘ®‘Ύ¥ΥάΐΉ”÷– « historyΘ©Θ§ΫΪΉ‘Ε·Α―ΝΡΧλάζ ΖΤ¥Ϋ”ΓΘ“ΣΉΔ“β≥§Ιΐ δ»κ≥ΛΕ» max_source_length ΒΡΡΎ»ίΜα±ΜΫΊΕœΓΘ
Ω…“‘≤ΈΩΦ“‘œ¬÷ΗΝνΘΚ
bash train_chat.sh
ΫαΈ≤
ΜνΕ·Ν¥Ϋ”ΘΚhttps://cloud.tencent.com/act/cps/redirect?redirect=35793&cps_key=d7ac5241b4606313a8f1a14a7df1f666
≥ωΉ‘ΘΚhttps://mp.weixin.qq.com/s/--F6_0fSRybBpupwPEGotQ