前几天在B站刷到AI孙燕姿唱的《黑色毛衣》,让我听傻了,还原度还能这么高的。于是就研究了一下,做了几段居然效果还行,可以在这里听《爱得太迟》。

简单解释一下,这个项目分为两个部分,模型的使用和模型的训练,模型使用的话对电脑的要求不是很高基本上差不多点的N卡都可以,模型的训练其实对显卡要求还挺高的小于6G会有各种各样的问题,当然也能炼,不过太麻烦了不建议。
主要使用的是So-VITS-SVC 4.0这个项目,github地址是:https://github.com/svc-develop-team/so-vits-svc
我这里会使用整合包来推理(使用模型)和训练,目前B站有两个作者做的整合包分别是羽毛布団的和领航员未鸟的我把视频地址都放在下面。希望各位去视频给个三连毕竟用了人家的劳动成果。
两位的视频教程也很好,我这边主要会更详细一些,会补充一些两位没说到但是有坑的地方。这次课程我使用的主要是羽毛布団的整合包,我把所有需要下载的都打包了。
羽毛布団:https://www.bilibili.com/video/BV1H24y187Ko/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=e99f85042059f2864f5cca20d71575f0
领航员未鸟:https://www.bilibili.com/video/BV1Eb411f7gX/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=e99f85042059f2864f5cca20d71575f0
所需软件和模型下载(百度云):https://pan.baidu.com/s/1n_3j9NCAn5LwU8mb3IGCMg 提取码:回复提取码获取。
模型使用
首先是模型使用的部分,如果你没有兴趣训练自己的模型只想使用别人训练好的模型尝鲜的话只看这部分就可以了,这部分主要分为三个本部分原始声音的处理、推理过程以及最后的音轨合并。
原始声音处理
要使用模型进行推理的话你首先需要一段已经演唱好的声音垫进去,然后使用模型把原来的音色换成你模型训练好的音色(类似AI画图的img2img垫图)。所以我们需要先对你垫进去的声音进行处理,去掉原始音乐里面的混响和乐器声音,只留下人物的干声这样效果会好一些。
我们会使用UVR_v5.5.0这个软件来处理声音通过两段处理保留人物的干声。
首先是安装,直接双击UVR_v5.5.0_setup.exe一直下一步就行,安装完成后我们需要给UVR增加一个模型解压UVR5模型文件将里面的两个文件夹粘贴到安装目录下的Ultimate Vocal Remover\models就行。
在处理之前你需要把你声音的格式转换成WAV格式,因为So-VITS-SVC 4.0只认WAV格式的音频文件,现在处理了后面会省事点。可以用这个工具处理:https://www.aconvert.com/cn/audio/mp4-to-wav/
处理完音频文件后我们就要开始利用UVR去掉背景音了,一共需要过两次,每次的设置都是不同的,这样能最大限度的保证不需要的声音能被去除干净。
在Select Input选择你需要处理的音频文件,处理完成后你可以在Output的文件夹下面找到处理完成的文件,后缀有(Vocals)就是人声,后缀为(Instrumental)就是伴奏,伴奏先不要删,我们后面合成的时候还需要。
下图为第一次处理UVR的参数:
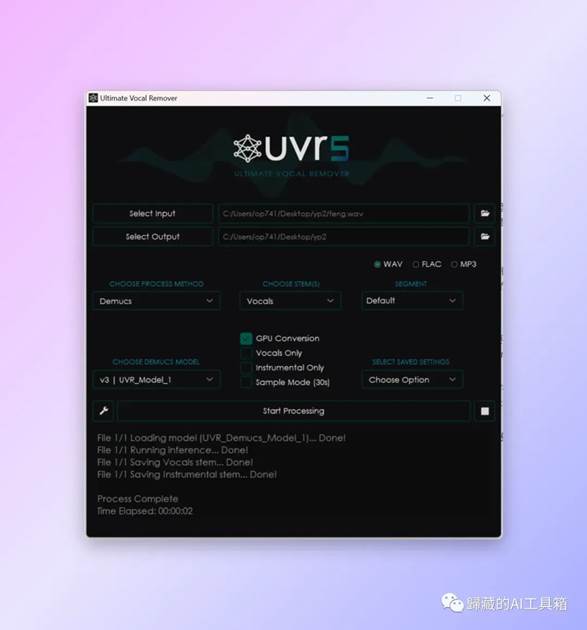
完成第一次处理后我们再调整参数进行第二次处理,下面是第二次处理需要的参数设置:
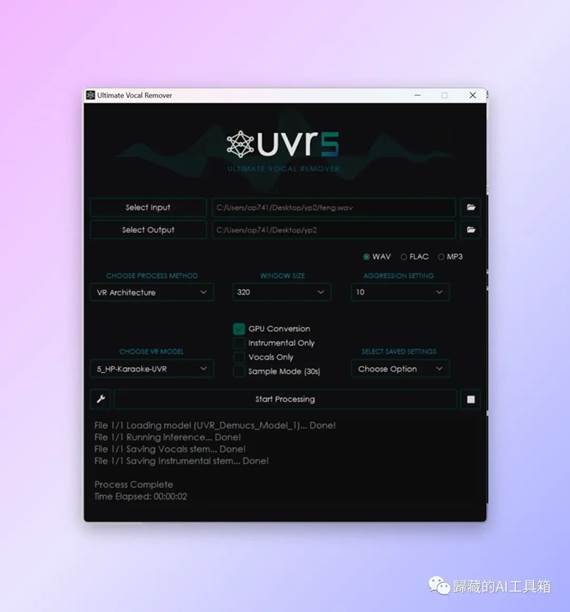
接下来我们就要运行整合包的Web UI来推理声音了,如果你用的其他人的模型的话你需要先把模型文件放进整合包对应的文件夹下面:
首先是GAN模型和Kmeans模型就是模型文件夹下面后缀为pth和pt的两个文件放到整合包的\logs\44k文件夹下。
之后是配置文件,就是你下载下来的模型文件里那个叫config.json的json文件,放到整合包的\configs文件夹下面。
接下来我们就可以运行整合包的Web UI了,打开整合包根目录下的【启动webui.bat】这个文件他会自动运行并打开Web UI的网页,经常玩Stable Diffusion的朋友肯定对这个操作不陌生。
下面就是Web UI的界面我们使用模型的时候主要用的是推理这个功能。
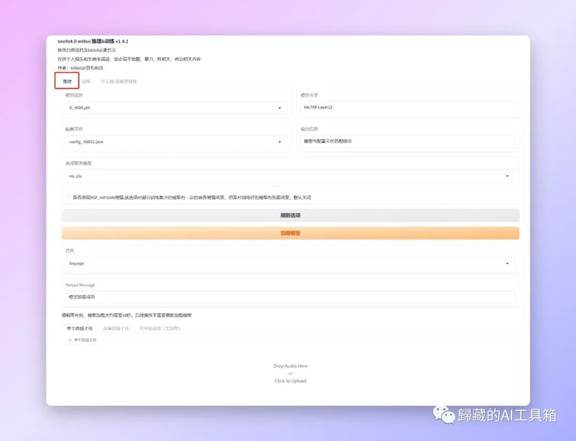
之后就是选择我们的模型,如果你刚才已经把模型放到合适的位置的话你现在应该能在下图的两个位置选择到你的模型和配置文件,如果有报错会在输出信息的位置显示。
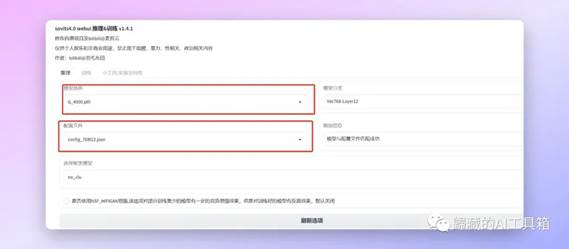
选择完模型之后我们需要点击加载模型,等待一段时间Loading之后模型会加载完成。Output Message这里会输出加载的结果。
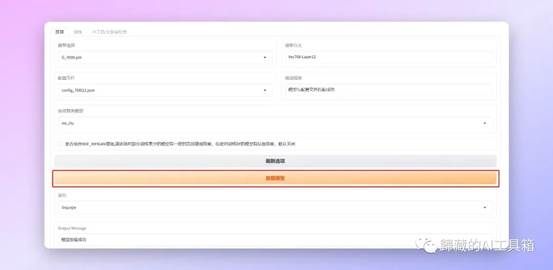
之后就是上传我们处理好的需要垫的音频文件了,把文件拖动到红框位置就行。
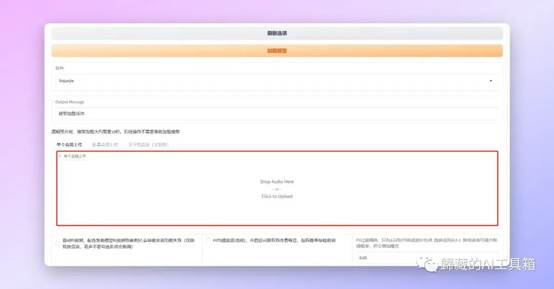
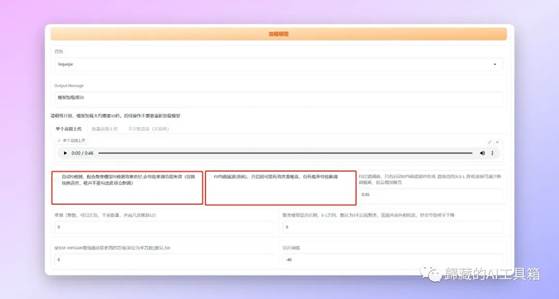
接下来是两个比较重要的选项【聚类f0】会让输出效果更好,但是如果你的文件是歌声的话不要勾选这个选项,不然会疯狂跑调。【F0均值滤波】主要解决哑音问题,如果你输出的内容有比较明显的哑音的话可以勾选尝试一下,这个选项歌声可以使用。
除了这两个选项之外的其他选项不建议动。除非你理解它是什么意思。
设置好之后我们点击【音频转换】按钮之后经过一段时间的运算,就可以生成对应的音乐了。
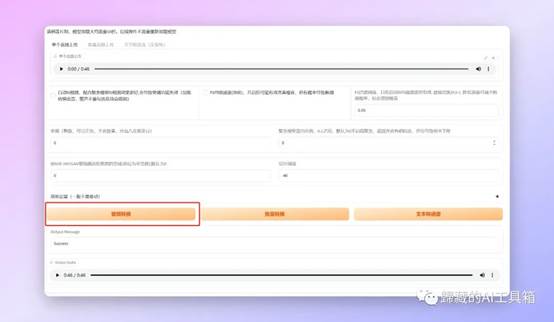
【output audio】的位置就是生成的音频了可以试听,如果觉得OK的话可以,点击右边三个点弹出的下载按钮下载。
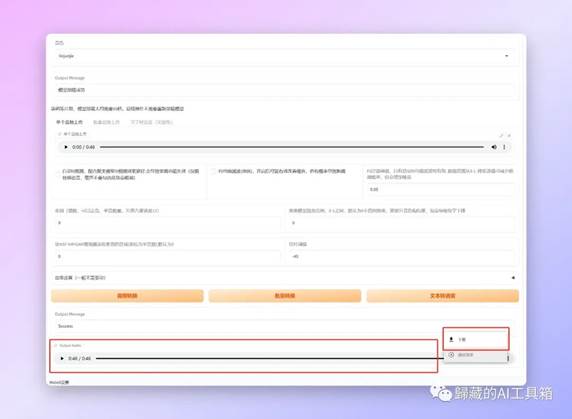
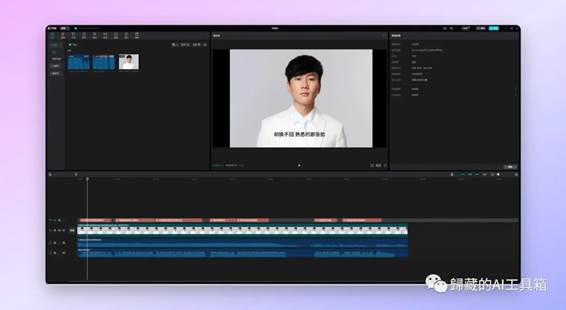
我们现在生成的是一段只有人声的干声,这时候我们刚才剥离出来的伴奏就有用了,把两段音频合成就行,我用的剪映,直接把两段音轨拖进去导出就行,也可以加张图片变成视频。
好了模型的使用部分到这里就结束了,理论上你现在如果有孙燕姿的模型的话已经可以生产AI音乐了。垫的音频文件也有一些要求,首先肯定是人声要清晰,伴奏最好少点去的也干净同时效果也会更好。
AI孙燕姿我用的是B站Ozzy23的模型他的这个模型效果非常好各位可以去他视频下面的简介下载,不要忘了三连。
https://www.bilibili.com/video/BV1kk4y1Y7vp/?spm_id_from=333.999.0.0&vd_source=e99f85042059f2864f5cca20d71575f0
出自:https://mp.weixin.qq.com/s/bXD1u6ysYkTEamt-PYI1RA