在过去的几周里,我一直在试用几个大型语言模型(LLMs)并使用互联网上的各种方法探索它们的潜力,但现在是时候分享我到目前为止所学到的东西了!
我很兴奋地得知元推出了其开源大型语言模型的下一代,LLaMA 2(于2023年7月18日发布),该模型最有趣的部分是,他们将其免费提供给公众用于商业用途。因此,我决定尝试一下它的性能表现。
在这篇文章中,我将分享如何使用Llama-2 -7b-chat模型和LangChain框架以及FAISS库执行类似于聊天机器人的问答任务,这些文档是我从Databricks文档网站在线获取的。
介绍
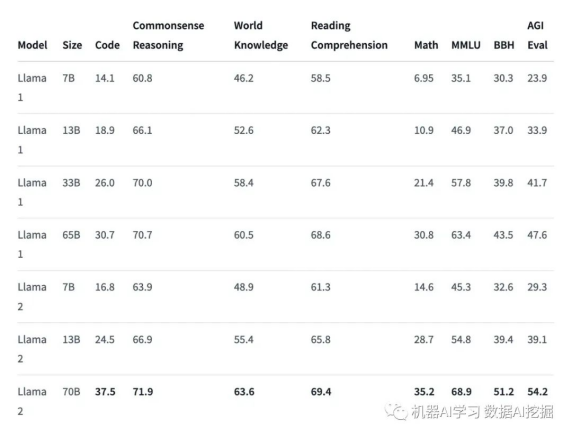
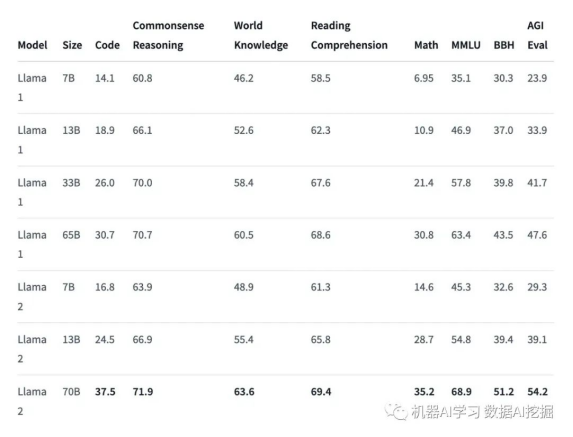
LLaMA 2模型是使用2万亿个tokens和70亿到700亿参数预训练和微调的,使其成为功能强大的开源模型之一。它有三种不同的模型大小(即7B、13B和70B),与Llama 1模型相比有显著改进,包括在40%更多的tokens上进行训练,具有更长的上下文长度(4k tokens ���),并使用分组查询注意力快速推理70B模型���。它在许多外部基准测试中超越了其他开源LLMs,包括推理、编码、熟练度和知识测试。
LangChain是一个强大、开源的框架,旨在帮助您开发由语言模型(特别是大型语言模型)提供支持的应用程序。该库的核心思想是我们可以将不同的组件“链接”在一起,以创建围绕LLMs的更高级用例。LangChain由来自多个模块的多个组件组成。
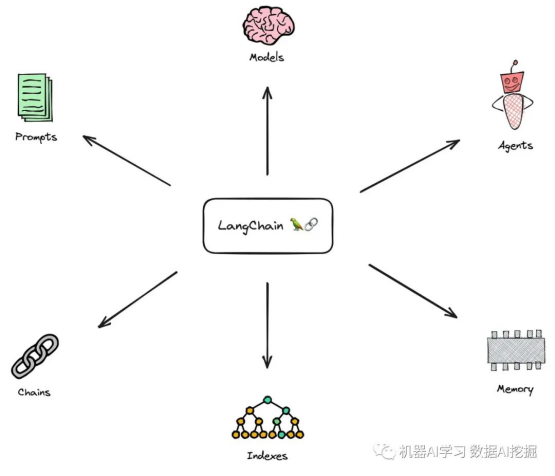
模块:
提示(Prompts):该模块允许您使用模板构建动态提示。根据上下文窗口大小和用作上下文的输入变量,它可以适应不同的LLM类型,例如对话历史记录、搜索结果、先前的答案等。
模型(Models):该模块提供了一个抽象层来连接到大多数可用的第三方LLM API。它有API连接到约40个公共LLMs、聊天和嵌入模型。
内存(Memory):此模块为LLM提供对会话历史的访问权限。
索引(Indexes):索引指的是使LLM能够最佳地与文档交互的方式。此模块包含处理文档的实用函数以及与其他向量数据库集成的集成。
代理(Agents):某些应用程序不仅需要预定的LLM或其他工具的调用链,而且可能需要依赖于用户输入的未知链。在这些类型的链中,有一个具有访问一组工具的代理。根据用户的输入,代理可以决定调用哪个工具(如果有的话)。
链(Chains):对于一些简单的应用程序,单独使用LLM就足够了,但对于许多更复杂的应用程序,需要将LLM链接在一起,或者与其他专家链接在一起。LangChain提供了链的标准接口以及一些通用的链实现,以方便使用。
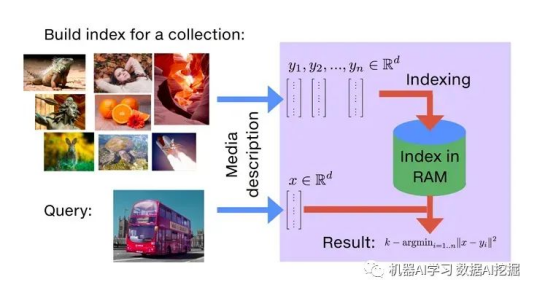
FAISS(Facebook AI Similarity Search)是一个用于高效相似度搜索和密集向量聚类的库。它可以在标准数据库引擎(SQL)无法或效率低下地搜索多媒体文档(如图像)的情况下进行搜索。它包含了能够在可能不适用于RAM的任意大小的向量集合中进行搜索的算法。它还包含评估和支持代码参数调整。
处理流程
在本节中,我将简要描述流程的每个部分。
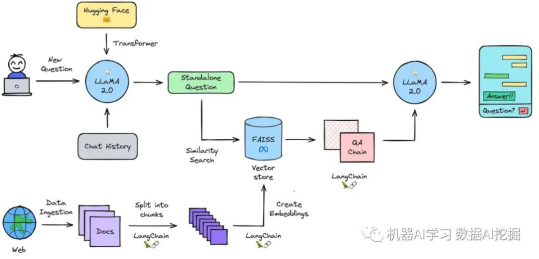
初始化模型管道:使用Hugging Face的transformers库为预训练的Llama-2-7b-chat-hf模型初始化文本生成管道。
摄取数据:将任意来源的文本形式的数据加载到文档加载器中。
拆分为块:将加载的文本拆分成较小的块。创建这些文本块是必要的,因为语言模型只能处理有限的文本量。
创建嵌入:将文本块转换为数值表示,也称为嵌入。这些嵌入用于在大型数据库中快速搜索和检索类似或相关的文档,因为它们代表了文本的语义含义。
将嵌入加载到向量存储中:将嵌入加载到向量存储(在这种情况下是“FAISS”)中。与传统数据库相比,向量存储在基于文本嵌入的相似性搜索方面表现出色。
启用记忆功能:将对话历史记录与新问题结合起来,并将它们变成单独的问题对于启用提出后续问题的能力非常重要。
查询数据:使用嵌入在向量存储中搜索存储的相关信息。
生成答案:将独立的问题的相关信息传递给问答链,在那里使用语言模型生成答案。
代码编写
本节中,我将详细介绍代码的每个步骤。
开始使用您可以在Hugging Face transformers和LangChain中使用开源Llama-2-7b-chat模型。但是,您必须首先通过Meta网站请求访问Llama 2模型,并在接受Hugging Face网站上的Meta共享您的帐户详细信息时接受该请求。通常需要几分钟或几小时才能获得访问权限。
��� 注意,您在Hugging Face网站上提供的电子邮件地址必须与Meta网站上提供的电子邮件地址匹配,否则您的请求将无法通过审核。
如果您正在使用Google Colab来运行代码,请按以下步骤操作:在笔记本中转到“运行时”>“更改运行时类型”>“硬件加速器”>“GPU”>“GPU类型”>“T4”。进行推理需要大约8GB的GPU RAM,在CPU上运行几乎不可能。
安装依赖库

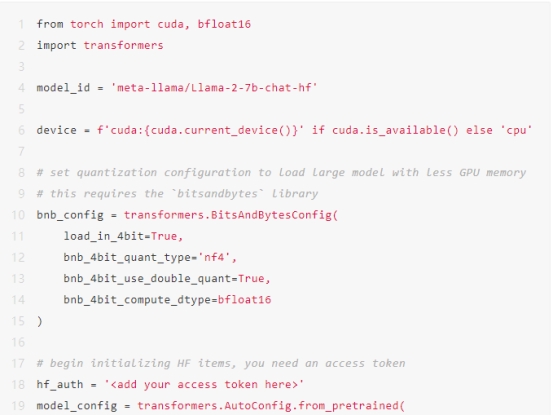
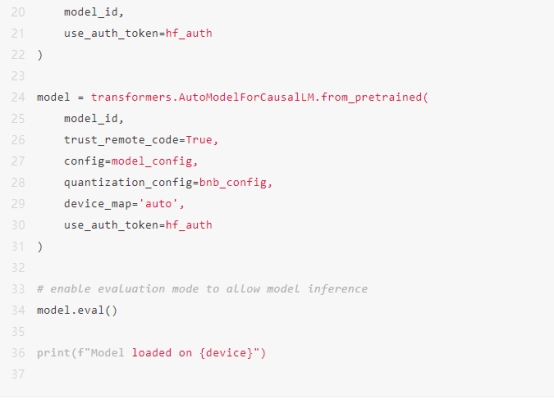
初始化Hugging Face pipeline您必须使用Hugging Face transformers初始化一个文本生成管道。该管道需要以下三个必须初始化的内容:
1. LLM,在这种情况下将是meta-llama/Llama-2-7b-chat-hf。
2. 模型的相应分词器。
3. 停止标准对象。您必须初始化模型并将其移动到支持CUDA的GPU上。使用Colab,这可能需要5-10分钟来下载和初始化模型。
此外,您需要生成一个访问令牌,以便在代码中从Hugging Face下载模型。为此,请转到您的Hugging Face个人资料>设置>访问令牌>新建令牌>生成令牌。只需复制该令牌并在下面的代码中添加它。
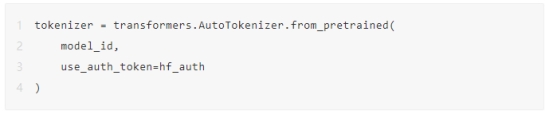
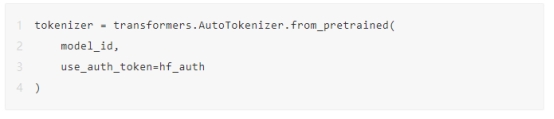
管道需要一个分词器,该分词器将人类可读的明文转换为LLM可读的令牌ID。Llama 2.7B模型使用Llama 2.7B分词器进行训练,可以使用以下代码初始化该分词器:
现在我们需要定义模型的停止条件。停止条件允许我们指定模型何时应该停止生成文本。如果我们不提供停止条件,则模型在回答初始问题后会走一些离题的路线。

您必须将这些停止令牌ID转换为LongTensor对象。
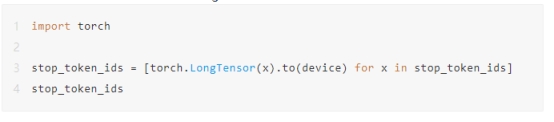
您可以快速检查stop_token_ids中是否出现令牌ID(0),因为没有出现,因此我们可以继续构建停止条件对象,该对象将检查是否满足停止条件 - 即是否生成了任何这些令牌ID组合。

您已经准备好初始化Hugging Face管道了。在这里,我们必须定义一些额外的参数。代码中包括注释以进行进一步解释。
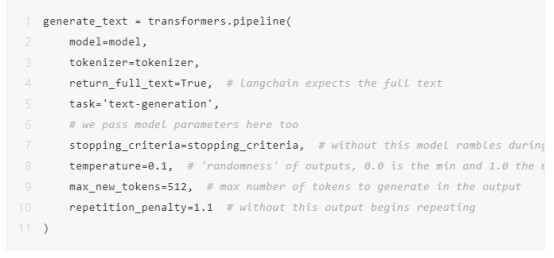
运行这段代码以确认一切正常。

在LangChain中实现Hugging Face管道
现在,您需要将Hugging Face管道实现在LangChain中。您仍然会得到与此处没有进行任何更改相同的输出。但是,这段代码将允许您使用LangChain的高级代理工具、链等与Llama 2一起使用。

使用文档加载器摄取数据
您必须使用WebBaseLoader文档加载器摄取数据,该加载器通过抓取网页收集数据。在这种情况下,您将从Databricks文档网站收集数据。
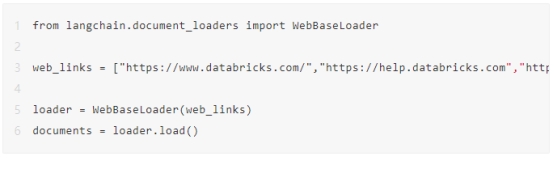
使用文本分割器以块形式拆分文本
您必须确保将文本拆分为小块。您需要初始化RecursiveCharacterTextSplitter并通过传递文档来调用它。
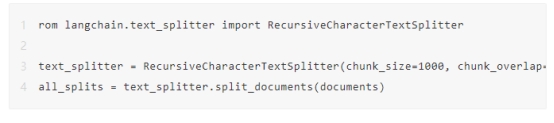
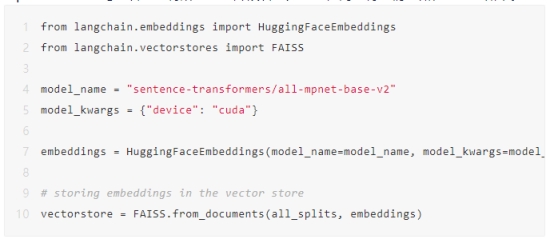
创建嵌入并存储在向量存储中
您需要为每个小文本块创建嵌入,并将它们存储在向量存储(即FAISS)中。您将使用all-mpnet-base-v2句子转换器将所有文本片段转换为向量,同时将它们存储在向量存储中。
初始化链
您需要初始化ConversationalRetrievalChain。该链使您能够拥有具有记忆功能的聊天机器人,同时依靠向量存储从您的文档中查找相关信息。另外,您可以在构建链时指定可选参数return_source_documents=True,以返回用于回答问题的源文档。

现在,是时候使用自己的数据进行问答了!

输出:

现在,您已经可以使用强大的语言模型对自己的数据进行问答了。此外,您还可以使用Streamlit进一步开发它成为一个聊天机器人应用程序。
出自:https://mp.weixin.qq.com/s/Amu68MFeBu_bJbaWBa71qA
在过去的几周里,我一直在试用几个大型语言模型(LLMs)并使用互联网上的各种方法探索它们的潜力,但现在是时候分享我到目前为止所学到的东西了!
我很兴奋地得知元推出了其开源大型语言模型的下一代,LLaMA 2(于2023年7月18日发布),该模型最有趣的部分是,他们将其免费提供给公众用于商业用途。因此,我决定尝试一下它的性能表现。
在这篇文章中,我将分享如何使用Llama-2 -7b-chat模型和LangChain框架以及FAISS库执行类似于聊天机器人的问答任务,这些文档是我从Databricks文档网站在线获取的。
介绍
LLaMA 2模型是使用2万亿个tokens和70亿到700亿参数预训练和微调的,使其成为功能强大的开源模型之一。它有三种不同的模型大小(即7B、13B和70B),与Llama 1模型相比有显著改进,包括在40%更多的tokens上进行训练,具有更长的上下文长度(4k tokens ���),并使用分组查询注意力快速推理70B模型���。它在许多外部基准测试中超越了其他开源LLMs,包括推理、编码、熟练度和知识测试。
LangChain是一个强大、开源的框架,旨在帮助您开发由语言模型(特别是大型语言模型)提供支持的应用程序。该库的核心思想是我们可以将不同的组件“链接”在一起,以创建围绕LLMs的更高级用例。LangChain由来自多个模块的多个组件组成。
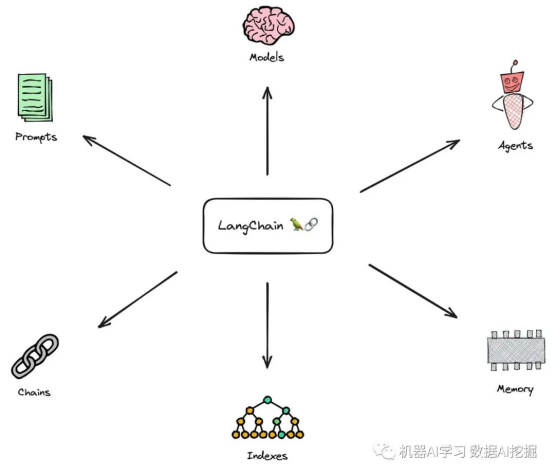
模块:
提示(Prompts):该模块允许您使用模板构建动态提示。根据上下文窗口大小和用作上下文的输入变量,它可以适应不同的LLM类型,例如对话历史记录、搜索结果、先前的答案等。
模型(Models):该模块提供了一个抽象层来连接到大多数可用的第三方LLM API。它有API连接到约40个公共LLMs、聊天和嵌入模型。
内存(Memory):此模块为LLM提供对会话历史的访问权限。
索引(Indexes):索引指的是使LLM能够最佳地与文档交互的方式。此模块包含处理文档的实用函数以及与其他向量数据库集成的集成。
代理(Agents):某些应用程序不仅需要预定的LLM或其他工具的调用链,而且可能需要依赖于用户输入的未知链。在这些类型的链中,有一个具有访问一组工具的代理。根据用户的输入,代理可以决定调用哪个工具(如果有的话)。
链(Chains):对于一些简单的应用程序,单独使用LLM就足够了,但对于许多更复杂的应用程序,需要将LLM链接在一起,或者与其他专家链接在一起。LangChain提供了链的标准接口以及一些通用的链实现,以方便使用。
FAISS(Facebook AI Similarity Search)是一个用于高效相似度搜索和密集向量聚类的库。它可以在标准数据库引擎(SQL)无法或效率低下地搜索多媒体文档(如图像)的情况下进行搜索。它包含了能够在可能不适用于RAM的任意大小的向量集合中进行搜索的算法。它还包含评估和支持代码参数调整。
处理流程
在本节中,我将简要描述流程的每个部分。
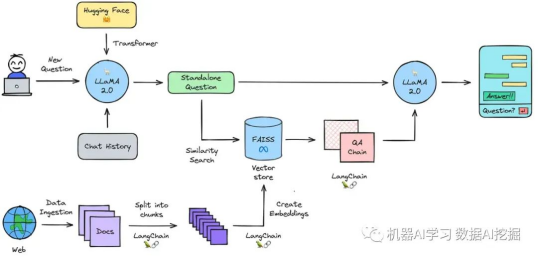
初始化模型管道:使用Hugging Face的transformers库为预训练的Llama-2-7b-chat-hf模型初始化文本生成管道。
摄取数据:将任意来源的文本形式的数据加载到文档加载器中。
拆分为块:将加载的文本拆分成较小的块。创建这些文本块是必要的,因为语言模型只能处理有限的文本量。
创建嵌入:将文本块转换为数值表示,也称为嵌入。这些嵌入用于在大型数据库中快速搜索和检索类似或相关的文档,因为它们代表了文本的语义含义。
将嵌入加载到向量存储中:将嵌入加载到向量存储(在这种情况下是“FAISS”)中。与传统数据库相比,向量存储在基于文本嵌入的相似性搜索方面表现出色。
启用记忆功能:将对话历史记录与新问题结合起来,并将它们变成单独的问题对于启用提出后续问题的能力非常重要。
查询数据:使用嵌入在向量存储中搜索存储的相关信息。
生成答案:将独立的问题的相关信息传递给问答链,在那里使用语言模型生成答案。
代码编写
本节中,我将详细介绍代码的每个步骤。
开始使用您可以在Hugging Face transformers和LangChain中使用开源Llama-2-7b-chat模型。但是,您必须首先通过Meta网站请求访问Llama 2模型,并在接受Hugging Face网站上的Meta共享您的帐户详细信息时接受该请求。通常需要几分钟或几小时才能获得访问权限。
��� 注意,您在Hugging Face网站上提供的电子邮件地址必须与Meta网站上提供的电子邮件地址匹配,否则您的请求将无法通过审核。
如果您正在使用Google Colab来运行代码,请按以下步骤操作:在笔记本中转到“运行时”>“更改运行时类型”>“硬件加速器”>“GPU”>“GPU类型”>“T4”。进行推理需要大约8GB的GPU RAM,在CPU上运行几乎不可能。
安装依赖库

初始化Hugging Face pipeline您必须使用Hugging Face transformers初始化一个文本生成管道。该管道需要以下三个必须初始化的内容:
1. LLM,在这种情况下将是meta-llama/Llama-2-7b-chat-hf。
2. 模型的相应分词器。
3. 停止标准对象。您必须初始化模型并将其移动到支持CUDA的GPU上。使用Colab,这可能需要5-10分钟来下载和初始化模型。
此外,您需要生成一个访问令牌,以便在代码中从Hugging Face下载模型。为此,请转到您的Hugging Face个人资料>设置>访问令牌>新建令牌>生成令牌。只需复制该令牌并在下面的代码中添加它。
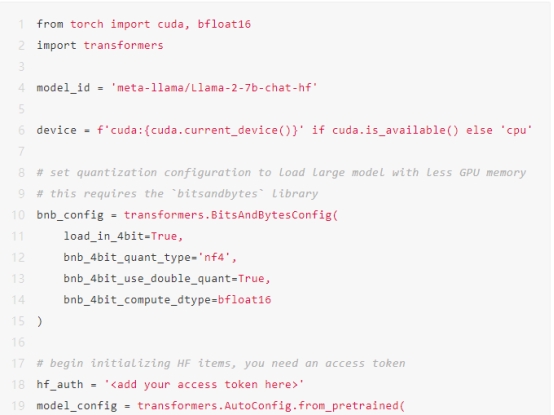
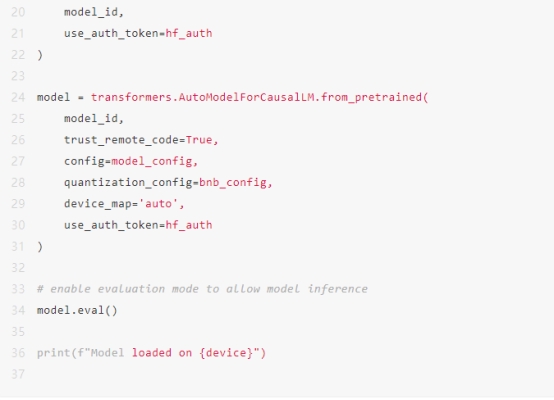
管道需要一个分词器,该分词器将人类可读的明文转换为LLM可读的令牌ID。Llama 2.7B模型使用Llama 2.7B分词器进行训练,可以使用以下代码初始化该分词器:
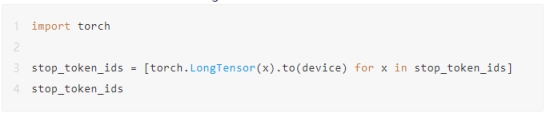
现在我们需要定义模型的停止条件。停止条件允许我们指定模型何时应该停止生成文本。如果我们不提供停止条件,则模型在回答初始问题后会走一些离题的路线。

您必须将这些停止令牌ID转换为LongTensor对象。
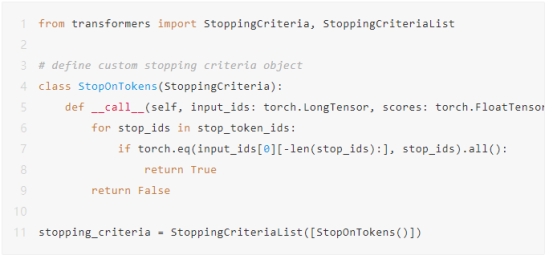
您可以快速检查stop_token_ids中是否出现令牌ID(0),因为没有出现,因此我们可以继续构建停止条件对象,该对象将检查是否满足停止条件 - 即是否生成了任何这些令牌ID组合。
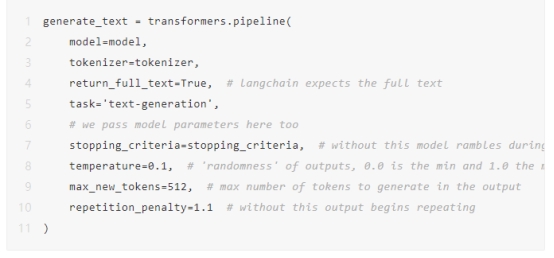
您已经准备好初始化Hugging Face管道了。在这里,我们必须定义一些额外的参数。代码中包括注释以进行进一步解释。
运行这段代码以确认一切正常。

在LangChain中实现Hugging Face管道
现在,您需要将Hugging Face管道实现在LangChain中。您仍然会得到与此处没有进行任何更改相同的输出。但是,这段代码将允许您使用LangChain的高级代理工具、链等与Llama 2一起使用。

使用文档加载器摄取数据
您必须使用WebBaseLoader文档加载器摄取数据,该加载器通过抓取网页收集数据。在这种情况下,您将从Databricks文档网站收集数据。
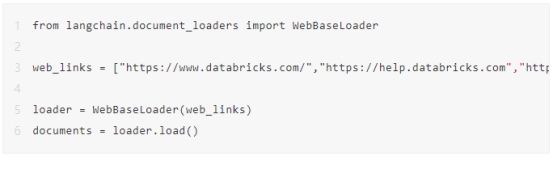
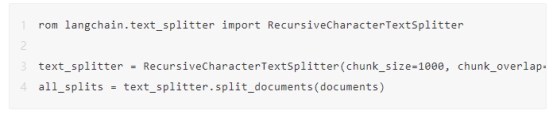
使用文本分割器以块形式拆分文本
您必须确保将文本拆分为小块。您需要初始化RecursiveCharacterTextSplitter并通过传递文档来调用它。
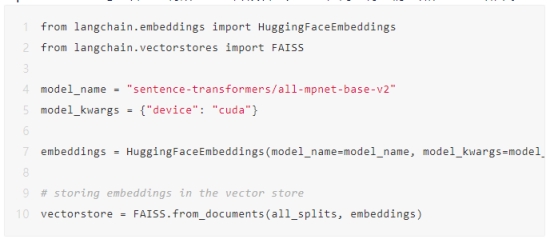
创建嵌入并存储在向量存储中
您需要为每个小文本块创建嵌入,并将它们存储在向量存储(即FAISS)中。您将使用all-mpnet-base-v2句子转换器将所有文本片段转换为向量,同时将它们存储在向量存储中。
初始化链
您需要初始化ConversationalRetrievalChain。该链使您能够拥有具有记忆功能的聊天机器人,同时依靠向量存储从您的文档中查找相关信息。另外,您可以在构建链时指定可选参数return_source_documents=True,以返回用于回答问题的源文档。

现在,是时候使用自己的数据进行问答了!

输出:

现在,您已经可以使用强大的语言模型对自己的数据进行问答了。此外,您还可以使用Streamlit进一步开发它成为一个聊天机器人应用程序。
出自:https://mp.weixin.qq.com/s/Amu68MFeBu_bJbaWBa71qA