清华大学ChatGLM团队发布AI Agent能力评测工具AgentBench:GPT-4是全能战士,超越所有模型
PART 01
未来大模型的发展方向:AI Agent
大语言模型(Large Language Models, LLM)最核心的能力是对语言的处理,具备良好的意图识别和文本生成能力让 LLM 超越了之前的模型,有了巨大的实用价值。但是,现实问题涉及了许多超越LLM外的能力,比如为用户提供实时数据分析和可视化结果、为软件开发提供一条龙服务等。
目前,让LLM解决这些问题的一个最有前景的方向就是建立大模型驱动的自动代理——AI Agent。换句话说,让 LLM 作为核心控制者来学会使用不同工具,进而完成最终任务。
在6月份,OpenAI的Safety团队的负责人Lilian Weng发布了一篇6000字的博客介绍了AI Agent,并认为这将使LLM转为通用问题解决方案的途径之一。
AI Agent本质是一个控制LLM来解决问题的代理系统。业界开源的项目如AutoGPT、MetaGPT、GPT-Engineer和BabyAGI等,都是类似的例子。LLM 的潜力不仅仅是生成写得很好的副本、故事、散文和程序;它可以被框架为一个强大的一般问题解决者。
Lilian Weng认为一个AI Agent系统应当包含如下图所示的几个部分:规划(Planning)、记忆(Memory)、工具使用(Tool Use)。
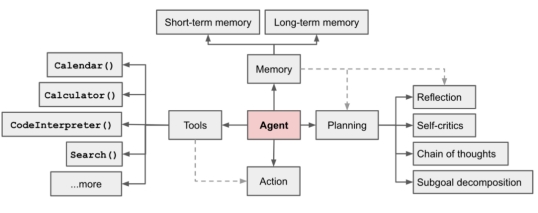
图注:AI Agent组成部分
·
规划(Planning):AI Agent需要提前计划,将复杂任务分解成许多步骤,还需对过去行为进行反思和提炼。
·
·
记忆(Memory):用于获取、存储、保留和检索信息的过程。记忆是类似多轮对话中记住之前的输入和设定的一种能力。大多数模型支持的上下文长度都是非常有限,针对不同场景、不同记忆类型AI Agent要去解决这个上下文问题。
·
·
工具使用(Tool Use):AI Agent学会调用外部API以获取模型权重中缺少的额外信息(在预训练后通常难以更改),包括当前信息、代码执行能力、对专有信息源的访问等。
·
7月份发布的 MetaGPT 是一个全新的AI Agent项目,它基于GPT-4提供了专注于软件开发的自动代理框架,几乎可以理解为配备了产品经历、系统设计师、程序员的一个小团队,可以基于原始的需求直接生成最后的代码项目。
传送门:开源框架 MetaGPT:又一个爆火的AI智能体,可模拟软件开发过程
PART 02
AI Agent能力评测工具AgentBench
但是,并不是所有的LLM都能作为AI Agent能高效完成任务,使用工具。或者说,并不是所有的AI Agent都有很好的表现,其核心还是取决于LLM的水平。
业界大多数AI Agent框架都默认使用GPT-4作为核心的LLM,那么,到底各个LLM作为AI Agent能力表现如何?这在目前没有一个合适的评测方式。
清华大学KEG与数据挖掘小组(发布ChatGLM模型)发布了一个最新大模型AI Agent能力评测数据集,对当前大模型作为AI Agent的能力做了综合测评。

论文:AgentBench: Evaluating LLMs as Agents
作者:Xiao Liu, Hao Yu, Hanchen Zhang, et al.
机构:Tsinghua University,The Ohio State University,UC Berkeley
论文地址:https://arxiv.org/pdf/2308.03688.pdf
项目地址:https://github.com/THUDM/AgentBench
AgentBench是一个系统的基准,用于评估大语言模型(LLM)作为代理执行实际任务的能力。该团队认为关于LLM的代理能力主要包含以下部分:

·
理解人类意图并执行指令
·
·
编码能力
·
·
知识获取和推理
·
·
策略决策
·
·
多轮一致性
·
·
逻辑推理
·
·
自主探索
·
·
可解释的推理
·
只有LLM能完成上述具体任务,才可能承担好AI Agent的工作。为此,AgentBench创建了8个不同的场景,针对上述能力来评估LLM作为Agent的表现,包括:
·
操作系统:评估LLM在Linux系统的bash环境中的操作能力,如文件操作、用户管理等。
·
·
数据库:考察LLM利用SQL操作给定的数据库完成查询、修改等任务。
·
·
知识图谱:需要LLM利用给定的工具查询知识图谱,完成复杂的知识获取任务。
·
·
卡牌游戏:将LLM视为玩家,根据规则和状态进行数字卡牌游戏,评估策略决策能力。
·
·
横向思维难题:提供难题故事,LLM需要进行问答来推理得到真相,检查横向思维能力。
·
·
家庭环境:在模拟的家中场景下,LLM需要自主完成日常任务,如搬移物品等。
·
·
网络购物:按照要求在模拟购物网站上浏览和购买商品,评估自主探索决策能力。
·
·
网页浏览:在真实网页环境中,根据高级指令实现操作序列,完成网页任务。
·

如此,如果LLM可以在上述场景中表现很好,那么作为Agent表现也会很好。
PART 03
25个主流LLM作为AI Agent的能力评估
最终,清华大学评估了25个主流的LLM在上述8个任务上的表现来评估各大模型作为Agent的最终得分。结果如下:
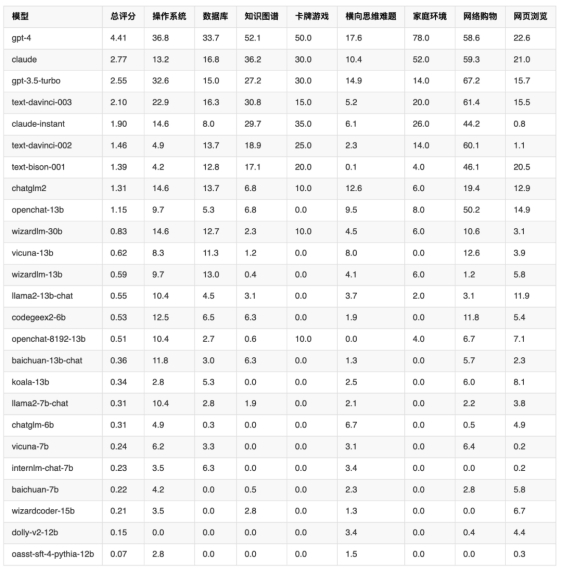
图注:25个主流LLM作为Agent的能力评估结果
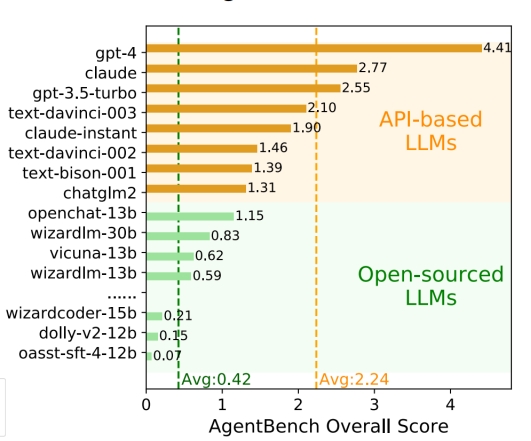
图注:将当前大模型LLM作为AI Agent的综合评测结果
从上面的评测结果,我们可以总结出几个重要的结论:
·
目前开源模型与商业模型之间还存在显著的差距,开源模型在AgentBench上普遍表现较弱。开源模型大多数综合得分不足1分,而GPT-4的得分则超达到4.41分!
·
·
国产模型中,ChatGLM2-6B的综合得分最高,也是开源模型最高得分,但也低于谷歌的模型(text-bison-001)。
·
·
商业模型中,GPT-4 在AgentBench上的综合得分最高,在7个任务上都居第一(除了「网络购物」任务被Claude超越),作为AI Agent的潜力最大,展现出在复杂环境中完成代理任务的强大能力,能够理解指令并进行多轮交互。
·
·
不同环境有不同的挑战,如操作系统和数据库考察编码能力,知识图谱需要复杂推理,网页浏览需要处理庞大inputs。不同模型之间也存在明显的优劣。
·
·
代码训练确实能增强编程相关环境的表现,但可能以牺牲其他能力为代价。例如,通过对两个规模相近的模型chatglm2和codegeex2-6b在AgentBench上的表现,可以看出代码训练的价值。其中,codegeex2-6b经过代码训练,在操作系统和数据库两个编程相关环境上明显优于chatglm2。但在需要逻辑推理的横向思维难题上,codegeex2-6b的表现下降。
·
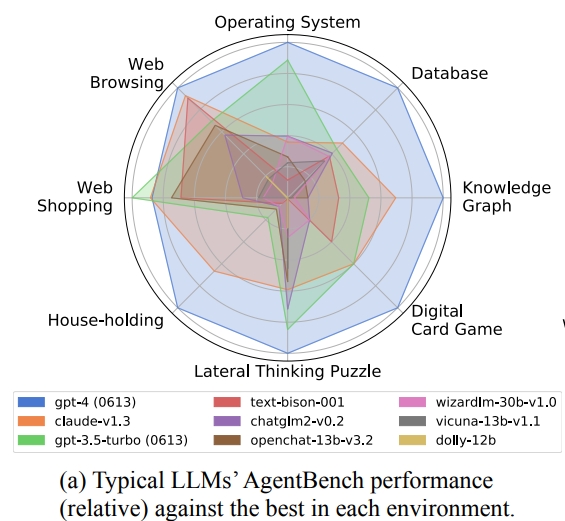
图注:几个模型的对比结果
这个 AgentBench 是评测 LLM 作为AI Agent的能力,通过评测 LLM 在细分任务的得分来确定 LLM 作为AI Agent的水平,主要结论就是商业模型表现远超开源模型,更加适合作为Agent来使用。特别的,GPT-4碾压胜出,成为唯一一个超越4分的模型,其它模型连3分都没有!
参考:
https://www.datalearner.com/blog/1051689842100145
https://www.datalearner.com/blog/1051691587479331
出自:https://mp.weixin.qq.com/s/U3b0OD7cpzBKzX6A93YHcw