Agent展现出了解决复杂任务的卓越能力。
· 目前大多数Agent是被动式的,限制了它们在需要预见性和自主决策的场景中的有效性。
· Agent2.0 主动发起任务,无需明确的人类指令。从被动响应转变为能够主动预测并发起任务的主动代理。这种转变不仅减轻了用户的认知负担,还能够帮助识别人类未明确表达的潜在需求,从而为用户提供更全面和无缝的服务。
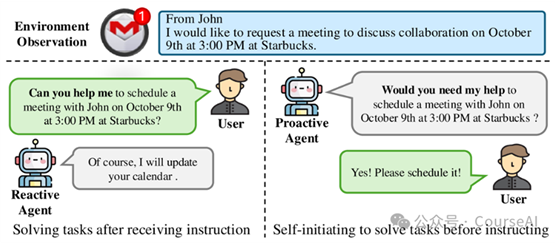
· 左边Agent,被动式接受用户查询,然后生成响应
· 右边Agent,主动式Agent基于环境观察推断任务,并相应地提出可能的协助请求。
ProactiveAgent流程图
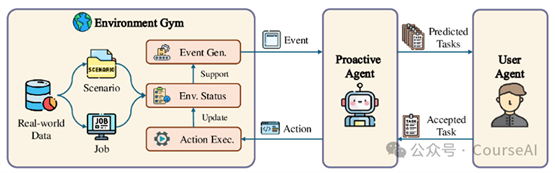
数据收集与处理
1.
环境监控与事件收集:开发基于Activity Watcher的监控软件,捕获用户与计算机系统的交互细节,包括键盘和鼠标操作、访问的网页和使用的开发工具。
2.
事件合并与文本描述:将原始数据合并成逻辑上连贯的段落,并使用语言模型将结构化数据转换为更自然的文本描述。
场景生成
1.
种子工作生成:使用GPT-4o基于人类标注者收集的种子工作创建各种任务,这些任务可能是用户在特定类别下执行的,如编码、写作或日常生活。
2.
实体生成:为任务可能涉及的实体(如浏览器、软件和工具)生成所有可能的实体。
3.
场景细化:通过添加更多细节(如实体状态或日期时间)来完善场景,并根据收集的事件为每个特定上下文生成示例事件。
事件生成
1.
用户活动生成:对于每个场景,用户代理首先描述其在模拟环境中完成工作的活动和行动。
2.
事件详细生成:环境健身房接受用户活动和行动,逐一生成详细事件。
3.
状态维护:环境健身房在生成新事件时更新实体的状态和属性,并根据最新环境状态生成下一个事件。
代理预测与任务执行
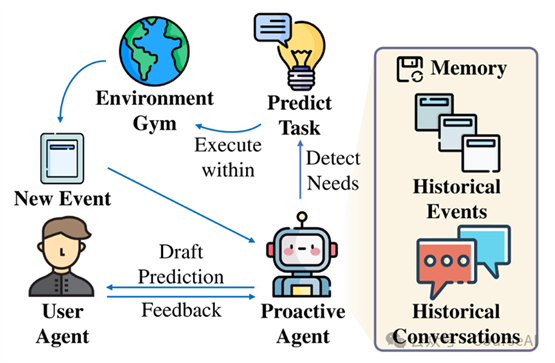
1.
预测任务:主动代理接收新事件后,更新其记忆,并结合新旧事件及与用户的对话历史,提出可能的任务。
2.
执行任务:一旦用户接受预测任务,代理将在环境健身房中执行任务,产生关于代理与环境交互的多个事件。
奖励模型评估
1.
模型训练:使用人类标注的数据训练LLaMA-3.1-8B-Instruct模型,并与几个基线模型进行比较,以展示其优越性。
2.
评估指标:使用奖励模型对预测任务进行二元分类,并与人类标注结果进行比较,计算召回率、精确度、准确度和F1-Score。
https://github.com/thunlp/ProactiveAgent
https://arxiv.org/abs/2410.12361
原文出自:https://mp.weixin.qq.com/s/UJVnE30rPivNsGcDGkQaHw