在医学、法律、电商等垂类领域,大模型在训练时候可能没见过太多这些知识,模型就容易“胡说八道”。虽然我们可以用特定领域再进行微调/二次预训练,仍然不能避免其“胡说八道”,而且训练不好很可能“灾难遗忘”,失去一些通用能力。
外挂数据库是解决模型“胡说八道”的有效手段。现在主流的外挂的数据库是向量数据库,因为实现起来比较简单,更复杂的也可以是图数据库、关系型数据库等。外挂数据库最简单的使用方式是,根据用户的问题,从数据库中召回若干条相关的文档片段,将文档片段和用户问题一块输入到大模型,让大模型根据文档片段回答用户的问题。其实,大模型对输入中不同位置的文本信息利用能力是不同的,对召回的若干条文档片段进行合理的位置安排,能有效提高模型的回答效果。
实验场景
(1)wiki问答场景:大模型输入中包含一个问题和k个与问题相关的wiki文档片段,但是只有其中1个文档片段包含正确答案(数据集大部分都是who/where类型的,有精确答案,比较好评估)。做多次试验,每次分别将包含正确答案的文档片段放在不同的输入位置,并看模型模型回答问题的正确率。
(2)大模型输入为一个字典,包含若干对key和value,key和value都是无意义的id编号。问大模型某个key,看其能否提取到对应的value。和文档问答相比,该任务更简单的任务,也和实际使用场景偏离,本文不关心这部分数据的实验结果,感兴趣的可以看下原文,结论也差不多。下文的内容都是wiki问答场景的。
核心观点
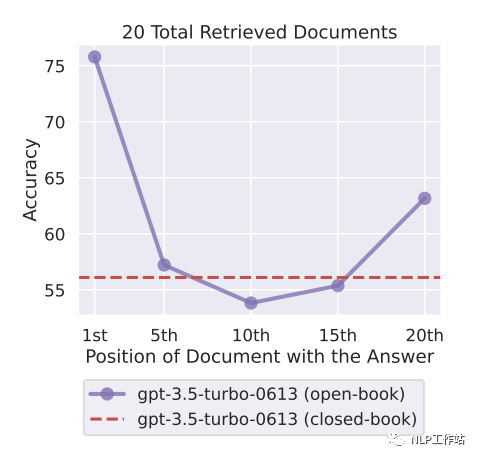
大模型对上下文中中间部分的知识点提取较差。下图展示了,在大模型输入中放入20个文档片段,分别把包含正确答案的文档片段放到输入的不同位置上(1~20),chatgpt能回答正确的概率。可以看到,如果包含正确答案的文本片段在中间位置,回答效果还不如不给他提供任何的文本片段(红色虚线,chatgpt不借任何外部知识,在wiki问答场景下回答正确率也有56.1%)。也就是说,在模型知道一些对应知识的场景下,如果输入过长,并且正确答案在输入的中间部分,甚至会给模型效果带来负面影响。并不是说外挂了知识库一定能促进模型回答效果。
实验现象
上文提到,wiki问答场景下,在输入里不给chatgpt提供任何额外知识,回答正确率都有56.1%,相当于可接受的使用外挂知识库的准确率下限(如果低于这个值,那就还不如不外挂知识库了)。作者也尝试了输入里只放1个包含正确的答案的文档片段,回答正确率为88%,相当于使用外挂知识库准确率的上限。
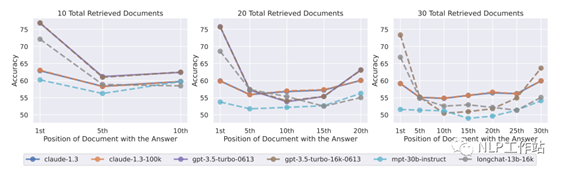
下图分别展示了不同模型在输入中分别放10/20/30个文档片段的实验结果(依然只有1个文档片段包含正确答案)。横坐标表示把包含正确答案的文档片段放到不同位置,纵坐标为准确率。从整体上来看,可以发现包含文档片段越多(上下文越长),模型性能越差。当文档片段数大于20时,如果把正确的文档片段放到中间位置,准确率还不如不加入任何文档片段(低于56.1%)。普通chatgpt和声称支持更长上下文的chatgpt-16k效果差不多。
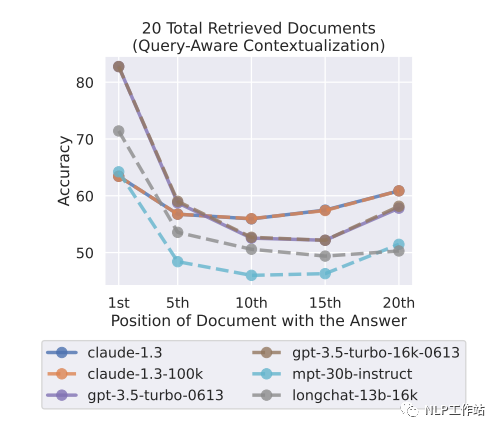
下边两张图展示了输入中包含20个文档片段的情况下,分别把query放到context尾部和context头部的实验效果。将query放到context头部效果更好。这非常符合直觉,实验的用的都是decoder架构的模型,只能看到上文的信息,带着问题去找答案更简单。
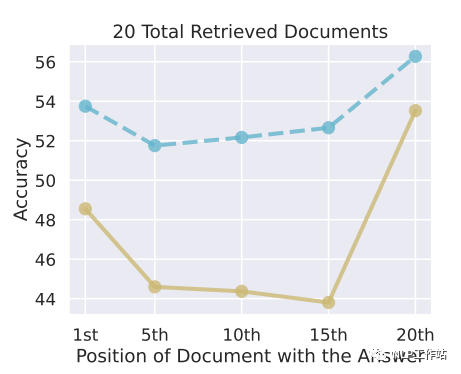
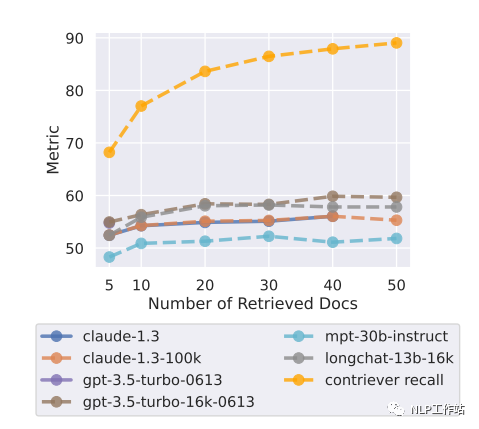
在实际应用场景下(该部分实验加入向量召回阶段,之前的实验没有召回阶段,都是把包含正确答案的文档片段直接塞到不同位置),向量召回可能是不准确的,召回的文档片段数量越多,漏掉正确答案的概率越小。但是如果召回的文档片段过多的话,导致输入到LLM的context过长,并不一定能有很好的效果。文中实验显示,随着召回的文档片段越来越多,召回率越高,召回阶段漏掉的正确文档越少(黄色曲线),但是模型回答的正确率并没有很大的提升,在召回20个文档片段的情况下基本就达到性能上线了。作者实验挑选的模型都是能支持比较长的文本的,大部分人使用的chatglm和llama估计能提取10个文档片段信息就不错了。。。当然,LLM能提取多少个文档片段的内容也和每个文档片段的长度有关。文档片段长度最好别超过100,不然会影响embedding模型向量化效果,进而使得召回精度降低。
总结
当我们召回若干个文档片段当作大模型的输入,应该怎么对这些文档片段进行排列,提高大模型回答效果呢? 如图所示,遵循两个原则:1. query放到头部。2.根据相似度(cos相似度,点积等)召回的文档,相似度越大的文档放到context的两端。(图中doc的序号指按召回相似度从大到小排序后的序号)
如图所示,遵循两个原则:1. query放到头部。2.根据相似度(cos相似度,点积等)召回的文档,相似度越大的文档放到context的两端。(图中doc的序号指按召回相似度从大到小排序后的序号)
出自:https://mp.weixin.qq.com/s/5QQ6VKiiQBRNyfRSS46k2A