本专栏主要介绍stable diffusion中的相关参数,整套模型是基于stable diffusion 1.X 的版本。
这篇文章相当于个人的学习笔记,全文近两万字,建议配合目录观看。
每小节都配有相关理论出处或参考文章,并附上了相应链接。
感谢各位大佬对知识的分享以及模型的开源!
1. 基础模型和外挂VAE模型
1.1 基本术语讲解
基础模型(大模型/底模型):属于预调模型,它决定了AI图片的主要风格。
VAE模型:全称Variational
auto enconder变分自编码器,它类似于图片生成后的滤镜。
“基础模型”和“外挂VAE模型”之间的区别:首先正常情况下,每个模型都是自带了一个VAE的,VAE虽然不是滤镜但可以把它们看做是一种类似于滤镜的效果。而在大模型内的VAE出问题了、坏了、或者是我们不满意的情况下,才需要使用外部手动进行VAE选择的VAE权重。
下载方式:大模型和VAE的下载我们可以从https://huggingface.co/,https://civitai.com/等网站进行下载,而在模型下载的时候需要留意其哈希值。因为有些模型可能名字不一样,但哈希值一样,这就意味着两者几乎没有区别。
1.2 不同基础模型的区别:
如左边是二次元风格,右边这个是写实风格,模型决定了基础的图像样子。
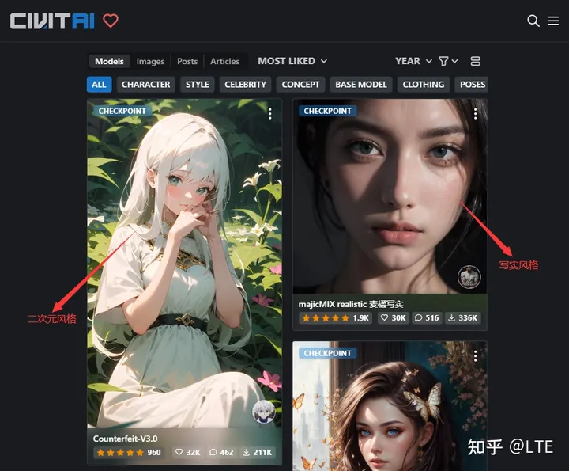
图1-1 不同基础模型的区别(来源https://civitai.com/)
1.3 不同外挂VAE模型的区别:
左边这张图展示了是否外挂VAE的差别,可以看到在加载新的一个VAE模型后,图片变得清晰起来。

图1-2 是否加载VAE模型的区别(来源https://civitai.com/models/23906/kl-f8-anime2)
右边这张图展示了不同VAE模型下的图片差别,可以发现图片的展现效果不一样,“滤镜”效果不一样。

图1-3 不同VAE之间的区别(来源:https://civitai.com/models/97653/z-vae)
所以,选用不同的VAE模型在制图的过程中很有必要,具体选用哪个建议是用XYZ Plot(做出如图1-3的效果)选出你最喜欢的那一个。
2. clip终止层数(clip skip)
深入理解 clip终止层数需从Stable
diffusion的原理入手,具体原理可以参考这两篇文章:
不过简单来说,我们可以将Stable diffusion理解为一个扩散模型(Stable:稳定的;diffusion:扩散),通过你所给的prompt词扩散出你想要的东西。
例如,当我们尝试生成一个人的插图时,会是这样的一个情况(当然,实际情况可能远比这个更复杂):
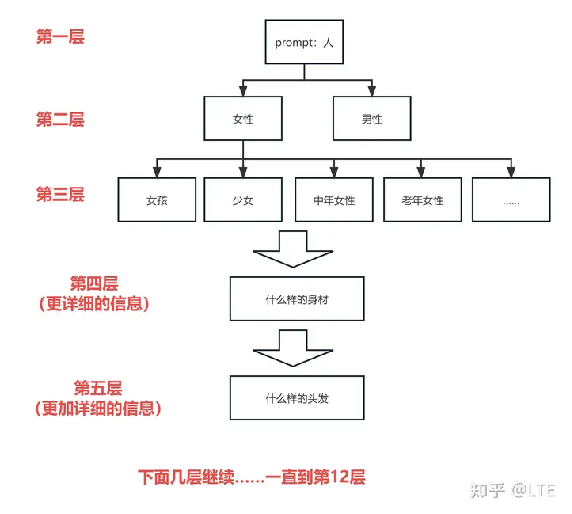
图2-1 Clip的原理图解(自制)
为什么是到12层呢?因为在该版本的模型中,深度为12层。
而你想处理到那一层就是:clip的终止层数(clipskip)
·
ClipSkip为1:处理到最后一层(即所有层)
·
ClipSkip为2:处理到倒数第二层(忽略最后一层)
·
ClipSkip为3:处理到倒数第三层(忽略最后和倒数第二层)
简言之,随着剪辑跳过的增加,要处理的层数逐渐减少。结果,详细信息被按顺序丢弃,没有反映的提示数量增加了。(一个词含有的意思很少,需要扩散来丰富)
再举一个比较具体的例子:
Prompt:masterpiece, best quality, 1girl, white hair, black skirt, purple eyes, full body, black dress

图2-2 不同clip
skip的表现(自制)
可见ClipSkip值较小,生成含有丰富提示词的插图;ClipSkip的值较大,生成忽略提示词的插图。
3. 提示词与预设样式存储
这个网上讲的很多,这里就不再赘述了。总之,提示词需要具有一定的指向性和有效性,同时注意权重的搭配,以及英文输入。
权重改变格式:
():一个括号的权重提升1.1倍。
(()):两个括号的权重提升1.1^2倍。
(prompt词:1.8):该词权重提升1.8倍。
介绍一下右边的快捷键:
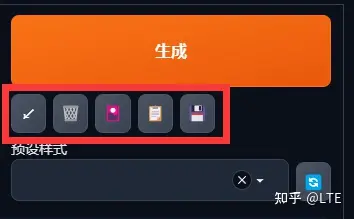
图3-1 快捷键一览
这些键从左到右依次为:从提示词或上次生成的图片中读取生成参数、清空提示词内容、显示和隐藏扩展模型、将所选预选样式插入到当前提示词之后、将当前提示词存储为预设样式。
通过这些可以快速帮我们念咒语,做到无吟唱施法。
4. 迭代步数(采样步数)
首先,我们简单介绍一下stable diffusion的相关原理。这里简单地可以把模型理解为一个迭代过程——从文本输入生成随机噪声开始的重复循环,每一步都会消除一些噪声,并随着迭代步数的增加会产生更高质量的图像。而当完成所需的步骤数时,重复就会停止(可以结合第五节采样方式来看)。
一般来说,大约25个采样步骤(20个也可以)通常足以获得高质量图像,使用更多的步骤可能会产生略有不同的图片,但不一定有更好的质量。此外,当我们使用的步骤越多,生成图像所需的时间就越多。不过在大多数情况下,额外的等待时间是不值得的。
例如一个“太空中的小狗”的展示(迭代步数从1-100,gif图片较大可能需要一定的等待时间):
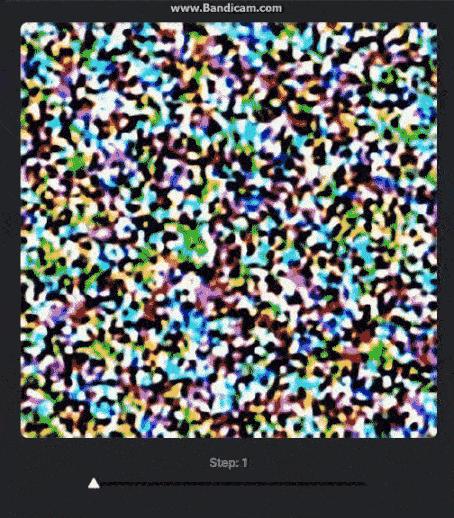
图4-1 不同迭代步数的区别(来源:https://getimg.ai/guides/interactive-guide-to-stable-diffusion-steps-parameter)
迭代步数4-7时,狗从斑点中出现。然后在生成大约20-25个步骤后,它就达到了较高质量。
超过25个步骤后不会造成质量的显着差异:狗的形状反复变化,但没有产生更多细节。
5. 不同采样方法的区别

图5-1 采样方法一览
为了生成图像,stable-diffusion首先在潜在空间中生成完全随机的图像,然后噪声预测器估计图像的噪声,再从图像中减去预测的噪声。这个过程重复十几次,最后便会得到一个干净的图像。
这个去噪过程称为采样,因为稳定扩散在每个步骤中都会生成一个新的样本图像。抽样所采用的方法称为抽样器或抽样方法。
5.1 采样方式介绍:
从目前这些采样方法来看,主要分为几个类型:Euler、LMS、Heun、DPM、DDIM、PLMS、UniPC,下面我们来详细解释一下:
Euler:是最简单的采样器。它在数学上与求解常微分方程的欧拉方法相同。它是完全确定性的,这意味着采样期间不会添加随机噪声。它的一般步骤为:
·
步骤1:噪声预测器根据潜在图像估计噪声图像。
·
步骤2:根据噪声表计算需要减去的噪声量。这就是当前步骤和下一步之间的噪声差异。
·
步骤3:将潜像减去归一化噪声图像(来自步骤1)乘以要减少的噪声量(来自步骤2)。
·
重复步骤1至3,直到噪声计划结束。
LMS:与欧拉方法非常相似,线性多步法(LMS)是求解常微分方程的标准方法。它的目的是通过巧妙地使用先前时间步骤的值来提高准确性。
Heun:是对Euler方法更精确的改进。但它每一步需要预测噪声两次,因此比欧拉慢两倍。
DPM:DPM(扩散概率模型求解器)和DPM++(对DPM的改进)是为2022年发布的扩散模型设计的新采样器,它们代表了一系列具有相似架构的求解器。DPM自适应可能会很慢,因为它不能保证在采样步骤数内完成。
DPM2:DPM和DPM2类似,只不过DPM2的DPM-Solver-2算法,求解器精确到二阶。(更准确但速度更慢,文献:https://arxiv.org/abs/2206.00927)。
DDIM和PLMS:DDIM(去噪扩散隐式模型)和PLMS(伪线性多步方法)是原始稳定扩散v1附带的采样器。DDIM是最早为扩散模型设计的采样器之一。PLMS是DDIM更新、更快的替代方案。它们通常被认为已经过时并且不再广泛使用。
UniPC(Unified Predictor Corrector方法)是2023年新开发的扩散采样器,由两部分组成:统一预测器(UniP)、统一校正器(UniC)它支持任何求解器和噪声预测器。
5.2 采样方式后缀的意思:
a:比如Euler和Eulera,这个加上的a值的是他们是ancestral
samplers(也有人称之为祖先采样器)。Ancestral samplers在每个采样步骤向图像添加噪声,并且作为随机采样器,使得采样结果具有一定的随机性。
下面两张图分别展示了Eulera和Euler生成的图像(以下图像来源于:https://stable-diffusion-art.com/samplers/):

图5-2 Euler a不收敛

图5-3 Euler收敛
Karras:指使用Karras噪声表。一般来讲,噪声预测器会根据潜在图像估计噪声图像,并根据噪声表计算需要减去的噪声量。第一步的噪音最大,然后噪音逐渐减小,并在最后一步降至零。(改变采样步数会改变噪声表,并使得噪音时间表变得更加平滑。采样步数越多,任何两个步之间的噪声降低越小。这有助于减少截断错误。)
下面这张图展示了原版噪声表(stable diffusion就是一个消去噪声,让图片更明晰的过程):
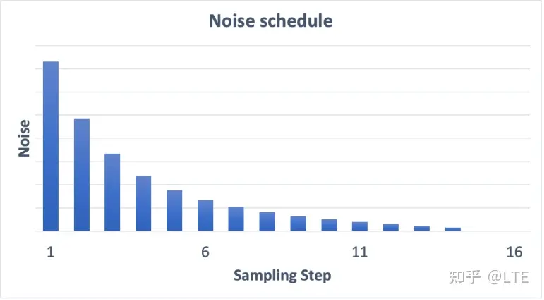
图5-4 常规噪声表(来源:https://stable-diffusion-art.com/samplers/)
至于Karras噪声表,则是一个比原版更好的去噪方式。需要注意的是带有“Karras”标签的采样器并不是由Karras制作的,而是使用了来自Karras论文的程序和灵感(https://arxiv.org/abs/2206.00364)。如果仔细观察,你会发现噪声步长在接近末尾时更小,他们发现这提高了图像质量。以下是默认噪声表和Karras噪声表之间的比较:
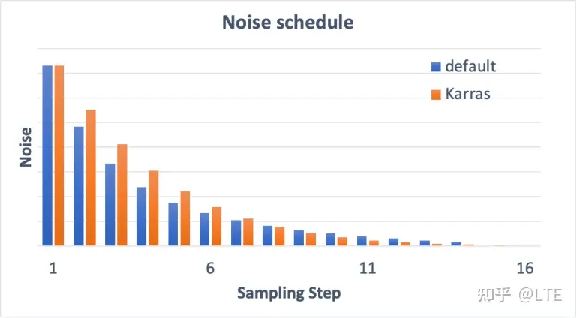
图5-5 默认噪声表和Karras噪声表之间的比较(来源:https://stable-diffusion-art.com/samplers/)
DPMFast:是具有统一噪声表的DPM求解器的变体,因此它的速度是DPM2的两倍。(参见:https://arxiv.org/abs/2206.00927)
DPMAdaptive:是具有自适应噪声调度的一阶DPM求解器。它会忽略你设置的步数并自适应地确定自己的步数。(参见:https://arxiv.org/abs/2206.00927)
其他:它们的后缀名称都与其算法相关,如DPM++2M【DPM-Solver++(2M)】;DPM++SDE【DPM-Solver++(stochastic)】;DPM++2S【a-Ancestral sampling with
DPM-Solver++(2S) second-order steps】。
5.3 采样方式比较:
从速度上来看:
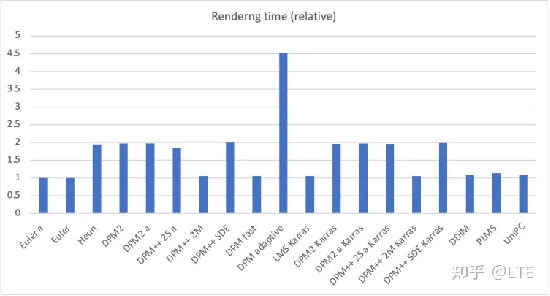
图5-6 每种方法的相对渲染时间(以euler a为基)(来源:https://stable-diffusion-art.com/samplers/)
上面这张图表现了每种方法的相对渲染时间:可见DPM自适应最慢,而其他的渲染时间可以分为两组,第一组花费大约相同的时间(约1倍),另一组花费大约两倍的时间(约2倍)。这反映了求解器的顺序。二阶求解器虽然更准确,但需要对去噪U-Net进行两次评估。所以它们的速度慢两倍。
从质量上看:
这里运用BRISQUE方法测量的感知质量,具体方法见这个文章:https://learnopencv.com/image-quality-assessment-brisque/(数值越低越好)
图片来源于:https://stable-diffusion-art.com/samplers/
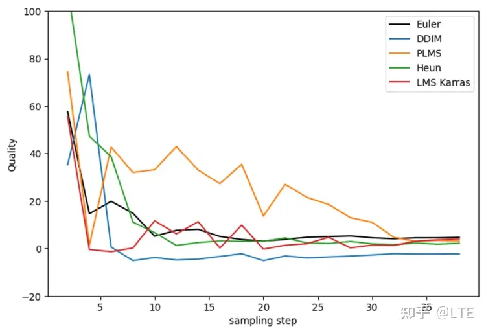
图5-7 DDIM、PLMS、Heun和LMS Karras的图像质量
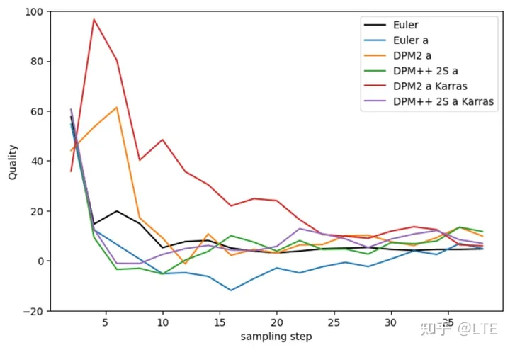
图5-8 Ancestral samplers的图像质量
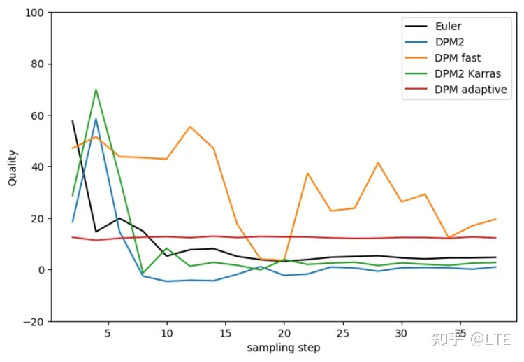
图5-9 DPM采样器的图像质量
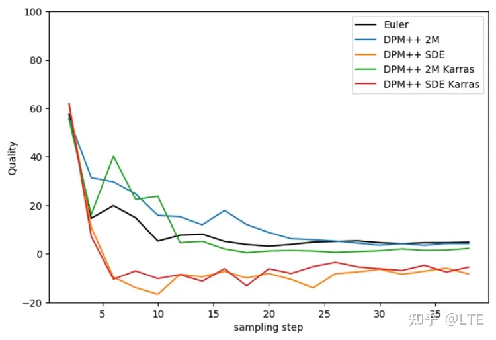
图5-10 DPM++采样器的图像质量
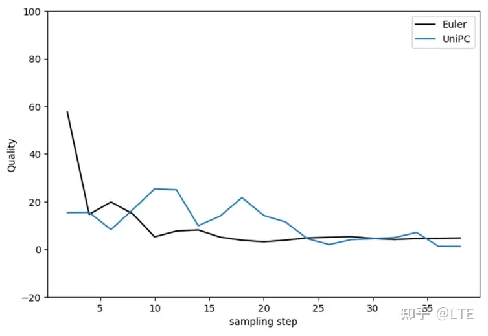
图5-11 UniPC采样器的图像质量

图5-12 一个有关所有采样器的简单对照(来源:https://stable-diffusion-art.com/samplers/)
5.4 总结与建议
就收敛行为而言(选择收敛=选择稳定、可重复的图像):
·
不收敛:Euler_a、DPM2a、DPMFast、DDIM、PLMS、DPMAdaptive、DPM2aKarras
·
收敛:Euler、LMS、Heun、DPM2、DPM++2M、LMSKarras、DPM2Karras、DPM++2MKarras
按所需步骤时间:
Euler_a=Euler=DPM++2M=LMSKarras(图像在高步长时退化)>
LMS=DPM++2MKarras=Heun(较慢)=DPM++2S a(较慢)=DPM++2S a Karras>
DDIM=PLMS=DPM2(较慢)=DPM2 Karras>
DPM快速=DPM2a(较慢)
·
如果你想使用快速且质量不错的东西,那么最好的选择是DPM++2M Karras,UniPC
·
如果你想要高质量的图像并且不关心收敛,那么不错的选择是DPM++SDE Karras
·
如果你喜欢稳定、可重复的图像,请避免使用任何ancestral samplers(加a的东西)。
·
如果你喜欢简单的东西,Euler和Heun是不错的选择。
6. 面部修复
其实SD内置的面部修复目前的用处并不大,我简单跑了两组对比图,大家可以简单看一下效果:

图6-1 动漫风格的面部修复(自制)

图6-2 真人风格的面部修复(自制)
这两组图中,左边是没有开面部修复,右边是开了面部修复的。其中真人的要变得稍微自然一点(也没有过于改进),但是动漫风格的反而变得模糊了,所以面部修复一般是不建议用在非写实的图片生成上。
不过相比于SD内置的面部修复,这里更推荐使用after detailer。
有关于afte rdetailer的参考文档附于此处,写的很详细了,我这里就不再赘述了。大家可以参考这篇文章:https://stable-diffusion-art.com/adetailer/
(有空会出一个中文版的详细介绍)
7. 平铺图tiling
该功能是生成一个可以拼接的图案,该图案是可以随意拼接的(如同铺地一样的瓷砖搬组合平铺的比较自然)。
比如生成一朵花,选用平铺图:

图7-1 生成一张平铺图(自制)
复制一模一样的四个拼合在一起:

图7-2 平铺图的拼接(自制)
可见非常的自然,很适合用于设计装修领域。
8. 高分辨率修复(Hires.fix)

图8-1 高分辨率修复一览
Hires.fix是一个很有用的选项,用于以较低分辨率部分渲染图像,放大图像,然后以较高分辨率添加更多细节。(实质上是将【后期处理】中的Upscale功能放在文生图这里了)
8.1 基本选项的解释
放大倍数:顾名思义,指放大的倍数。(这个放大到多少和底膜有很多关系,不过之前看到一篇GitHub上面的文章,说放大到1280之后图像就很容易出问题。所以在过大的图像上,我更建议用controlnet,后期处理等选项进行绘制)
高分迭代步数:它是提高分辨率时的步数,如果设置为0,将应用与采样步数相同的值。通常保留为“0”或小于采样步数的值即可。
重绘幅度(Denoising strength):指一张图在开始图生图时要加上多少噪点。0代表完全不加噪点,等于完全不重画。1代表整张图被随机噪点完全取代,会产生完全不相关的图。通常在0.5时会造成很显著的颜色光影改变,0.75时连结构跟人物姿态都会有很明显的变动。
8.2 各种放大算法的解释:
Latent算法:这是一种基于潜空间的放大算法,各种Latent算法可在潜在空间中缩放图像。它是在文本到图像生成的采样步骤之后完成的,该过程类似于图像到图像。
·
好处:不会出现其他升级器(如ESRGAN)可能引入的升级伪影(upscaling artifacts)。因为它的原理就是和stable diffusion一致的,相同的解码器生成图像,确保风格一致。
·
缺点:它会在一定程度上改变图像,具体取决于去噪强度(Denoising strength,也可以称重绘幅度)的值。往往去噪强度必须高于0.5。否则,你会得到模糊的图像,如下图所示:

图8-2 Latent算法搭配不同的去噪强度(自制)
不过这个可以通过其他的非latent放大算法规避,这是我用其他放大算法跑的一组图,可见去噪强度影响甚微:

图8-3 非Latent算法搭配不同的去噪强度(自制)
非latent算法:一般分为两种,一是基于传统算法(traditional
upscaler),一种是基于较优的识别算法(AI upscaler)。
·
传统的算法以Lanczos、近邻差值、ScuNET这些为主,它们的原理使用图像的像素值执行数学运算来放大画布并填充新像素。然而,如果图像本身被损坏或扭曲,这些算法就无法准确地填充丢失的信息。
·
AI upscaler以R-ESRGAN、BSRGAN、LDSR这些为主,人工智能升级器是用大量数据训练的模型。它能够填补缺失的信息,就像人类不需要非常详细地研究一个人的面孔来记住它一样。我们主要关注几个关键特征,然后进行补充一样。
可以看看它们的区别:

图8-4 传统放大算法和AI放大算法的区别(来源:https://stable-diffusion-art.com/ai-upscaler/)
可见,由于AI放大器中嵌入了知识,它可以放大图像并同时恢复细节,变得比传统放大算法的更加清晰。
8.3 不同的算法该如何选择?
可以参考一位外国友人的总结:
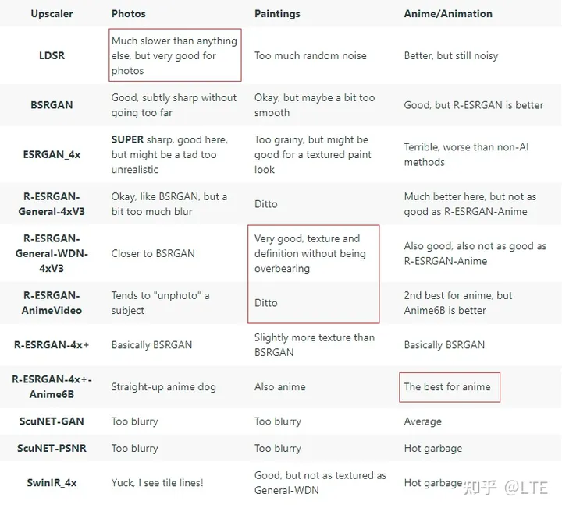
图8-5 原版
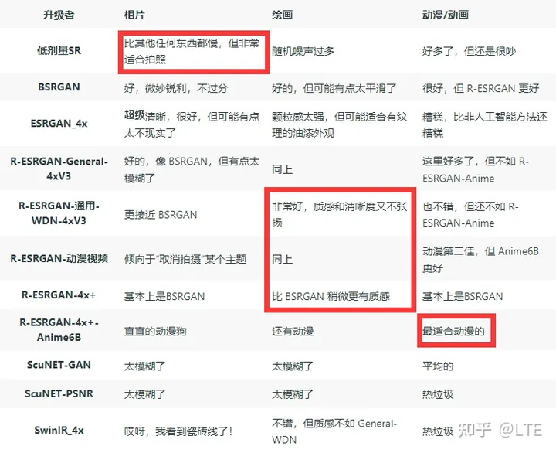
图8-6 中文版
8.4 总结与建议
·
相片类的:LDSR(但速度很慢),或者ESRGAN_4x(如果你想要超级清晰的细节和/或速度),或者BSRGAN巧妙地。
·
绘画类的:ESRGAN_4x提供高油漆纹理和细节,General-WDN提供更好的整体外观
·
动漫类的:Anime6B,也适合将某些东西变成动画。
下面是我跑的各种放大算法的一个对比图(由于图片太大下面就先放个不同算法的对比图),总之个人觉得除了latent算法0.5以下的重绘幅度不清晰外,其他差距很少。

图8-7 不同放大算法的对比(自制)
特别注意:如果在运行LDSR的过程中,命令行提示了这类的错误:URLError: <urlopen
error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed
certificate in certificate chain (_ssl.c:997)>,可以到这个网站下载相应的模型和前置插件https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/1705,并放在里面所说的位置。
9. 图像大小、数量、CFG、种子等参数设置
这一节将对这些进行说明:
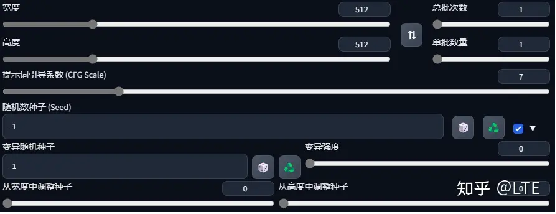
图9-1 情况一览
9.1 宽度和高度
即设置图片的大小。
这个地方需要注意一点,就是同样比例的图片精度不等于放大后为同样比例的图片精度。比如原本尺寸为1024*1024的图片精度不如512*512经过放大算法放大至1024*1024的图片精度,这是因为“改善总是比创造更容易的”,1024*1024会和原来一样生成瑕疵,但重绘是将这些瑕疵渐渐减少。
9.2 总批次数&单批数量
总批次数:总批次数为n,显卡出n次图,每次出一张。
单批数量:单批数量为n,显卡出一次图,一次出n张。
总之,显卡不好改总批次数就对了。
9.3 CFG
Classifier Free Guidance scale(分类器自由指导比例)是一个参数,用于控制模型应尊重你的提示的程度。如果CFG值太低,稳定扩散将忽略你的提示。太高时图像的颜色会饱和。
·
1–大多忽略你的提示。
·
3–更有创意。
·
7–遵循提示和自由之间的良好平衡。
·
15–更加遵守提示,图片的对比度和饱和度增加。
·
30–严格按照提示操作,但图像的颜色会过饱和。
这是在控制其他参数的情况下,不同CFG的结果:

图9-2 不同CFG下的结果(自制)
至于CFG的系数选择,其实不同的采样方法对应着不同最佳的CFG数值,而且随着迭代步数的增加,细节增加后的高位CFG数值也会有所变化。
那该怎么选择呢?这是国外的一位博主做的测试,其中绿色代表“mostly good”,黄色代表“mixed results”,红色代表“mostly bad”(视频链接:https://www.youtube.com/watch?v=kuhO9zAzetk;数据链接:https://docs.google.com/spreadsheets/d/1YkX1pzJvYKrj_w6fhrpyaTyZvR687THp7QkxOVI4qEg/edit?pli=1#gid=1511867707)
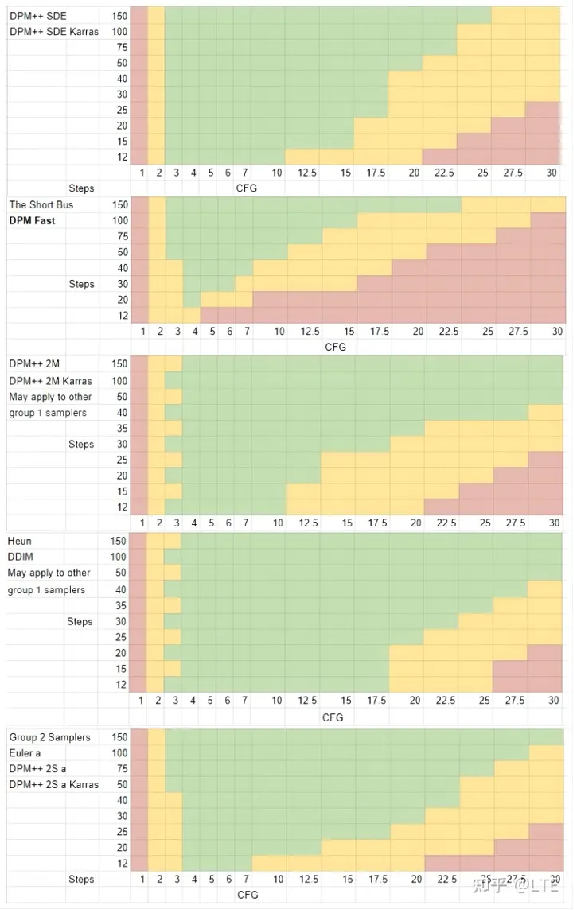
图9-3 测试结果(其中左边代表着不同的采样方式)
可见,CFG在4-10之间都非常适合,但最佳的还是建议将迭代步数还有采样方法结合起来看。
9.4 种子与变异种子
种子:用于在潜在空间中生成初始随机张量的种子值。实际上,它控制图像的内容。生成的每个图像都有自己的种子值。如果设置为-1,stablediffusion将使用随机种子值;如果设置为一个固定的种子值(比如用那个绿色的回收图标定为之前的图片样式),你可以增加或替换关键词达到在图片上增加或替换的效果。当然,过强的关键词也会导致构图的改变(这里更推荐蒙版重绘进行修改)。
下面是一个例子,我将在原图上增加一个关键词“项链”。从左到右依次为原图、改变关键词进行重新生成,蒙版重绘:

图9-4 基于同一种子的不同方式重绘(自制)
可见,蒙版重绘要更好一些。
变异随机种子:简单来说就是在原有的种子图上,新加入一个用其他种子值的图,最后生成两种图片的混合。其中“变异强度”指种子与变异种子之间的你的选择程度(权重),将其设置为0使用种子值。将其设置为1使用变异种子值。
这是一个我生成的简单例子:
原始种子值:362295556;变异种子值2420665621,变异强度0到1之间变化

图9-5 变异随机种子的应用(基于不同变异强度)- 自制
不过种子这里需要注意的是:在同一个种子值下,图片的内容会随着生成的长度和宽度的改变而改变,所以要获得清晰的原图,还是建议在后期处理中采用放大算法。
从宽度和高度中调整种子:就是调整变异种子增加后生成后的图片大小。
图9-6 从宽度和高度中调整种子
个人感觉用处不是很大,下面是一个例子:
(从左到右依次为:原图,调整种子的宽高度,直接调整生成图的宽高度)

图9-7 例子(自制)
10. Tiled diffusion和Tiled VAE
10.1 Tiled diffusion:
基本介绍:
Tiled diffusion平铺扩散,通过融合多个区域进行大型图像绘制。目前有两种算法,一种是Mixture of Diffusers,另一种是Multi Diffusion(它们的详细介绍可在这两个网址中充分找到:https://github.com/albarji/mixture-of-diffusers;https://multidiffusion.github.io/)
它的原理就是将图像分割成块,可以用以下这张图来结合解释。在每个步骤中,潜在空间中的每个小块都将被发送到Stable Diffusion UNet,小块一遍遍地分割和融合,直到完成所有步骤,成为一张完整的图片。
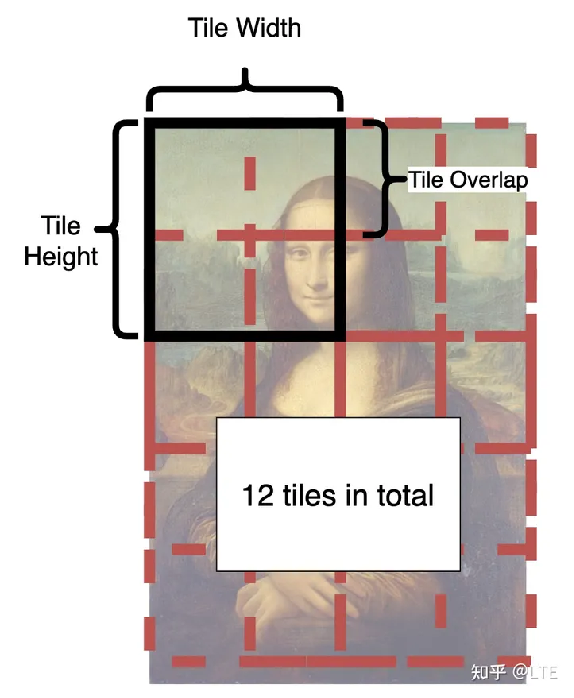
图10-1 Tiled diffusion图构原理(来源:https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111/blob/main/README_CN.md)
选项介绍:
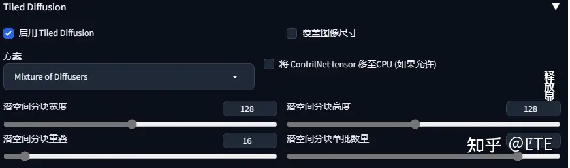
图10-2 选项介绍
.
方案:指的是两种算法以供选择;
.
覆盖图像尺寸:指的是能够做出超出原有SD模型的限制,做出更大的图像(比如类似于清明上河图的那种超宽影像)
.
潜空间分块宽/高度:就是那个图里面的小框宽高度,一般来说选64-160之间的值(最佳的数值选取其实取决于你选的潜空间分块单批数量,以及你所用模型的最佳生成图片大小【模型最好使用未剪枝的】,一般的建议选择是96或128)
.
潜空间分块单批数量:类似于生成图中的“单批数量”参数,这个看显卡性能,一般来说越大越快,这里的可供选择区间是1到8。
.
潜空间分块重叠:重叠数值提高会减少融合中的接缝。显然,较大的重叠值意味着更少接缝,但会显著降低速度,因为需要重新绘制更多的小块。(一般建议使用MultiDiffusion时选择32或48,使用MixtureofDiffusers选择16或32)
到这里,通过以上的这些步骤足以让你画出比原来更大的图像,但是在更大的图像中我们该如何生成我们想要的图画呢?
——使用分区提示词控制!
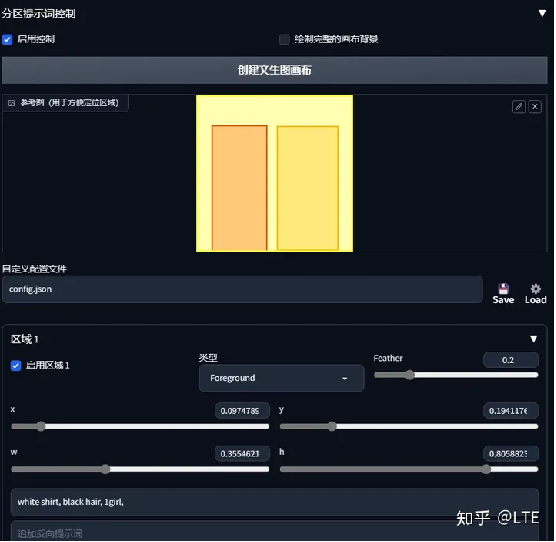
图10-3 分区提示词控制一览
分区提示词控制:启用分区提示词控制,你可以绘制参考图,启用不同的区域,在该区域中绘制你想要的图像,以及你想要的其他关键词、种子值。用法也很简单,基本和之前的一样,只不过将提示词分成了两个部分:一个是单独区域内用使用的单独提示词,一个是最上方控制全局的主提示词(如: Best quality, Hirex等)
另外需要注意一个点,那就是背景图(类型中的Background)需要铺满。
10.2 Tiled VAE:
这个是有关电脑性能的选项,勾选这个将会极大降低VAE编解大图所需的显存开销,几乎无成本的降低显存使用。以highres.fix为例,如果你之前只能进行1.5倍的放大,则现在可以使用2.0倍的放大。
不过一般来说你不需要更改默认参数,只有在以下情况下才需要更改参数:
·
一是当生成之前或之后看到CUDA内存不足错误时,请降低tile大小;
·
二是当你使用的tile太小且图片变得灰暗和不清晰时,请启用编码器颜色修复。
11. Additional
network
Additional network超网络是一种微调技术,它是一个附加到稳定扩散模型的小型神经网络,通过插入两个网络来转换key向量和query向量来劫持交叉注意力模块,用于修改其风格。
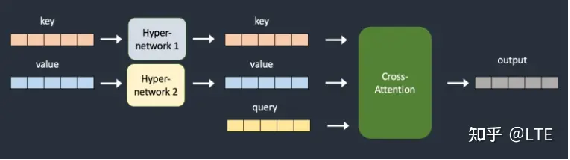
图11-1 原理概览(来源:https://stable-diffusion-art.com/hypernetwork/)
而lora模型就是其中一种非常好的轻量级模型,于2021年首次提出(https://arxiv.org/abs/2106.09685)。
lora模型的下载方式:我们可以在C站(https://civitai.com/)和抱脸(https://huggingface.co/)等网站上下载,放在相应的文档中就可以开始使用了。
11.1 整体权重
其作用可以借由这个公式来说明:
W′=W+αΔW
其中W是主模型, ΔW 是微调的lora模型,a是lora模型的scale,也叫整体权重。
·
将a设置为0时,与只使用主模型的效果完全相同;
·
将a设置为1时,与完全使用lora的效果相同。
因此如果LoRA存在过拟合的情况,我们可以将a设置为较低的值。如果使用LoRA的效果不太明显,拿我们可以将设置为略高于1的值。
但这仅限于在additional network这个里面的调整。在另外通过加载“扩展模型”调用lora的情况中,lora的权重范围是在0到1之间,其中1是最大强度。但是对于许多LoRA的权重为1可能会压倒性地产生较差的结果,因此请尝试使用较低的值,例如0.5、0.8。
这是一个我跑的一个关于整体权重不同的比较,可见从0.6开始lora的风格开始体现出来(1到2中的变化感觉不大,所以在这里0到1之间是主要的调整部分):

图11-2 不同整体权重的表现(自制)
11.2 Textencoder
& unet的权重调整:
要明白权重的调整,首先要理解这两个参数的意义。
U-Net是具有编码器部分和解码器部分,编码器将图像表示压缩为较低分辨率图像表示,解码器则将较低分辨率图像表示为噪声较小的原始较高分辨率图像表示。更具体地说,U-Net输出预测噪声残差,该噪声残差可用于计算预测的去噪图像表示。此外,稳定扩散U-Net能够通过交叉注意力层在文本嵌入上调节其输出。
Textencoder文本编码器负责将输入提示转换为U-Net可以理解的嵌入空间。它通常是一个简单的基于转换器的编码器,将输入标记序列映射到潜在文本嵌入序列。
举个例子来更加具体地说明一下:
这是仅使用Textencoder的LoRA

图11-3 unet:0, Textencoder:1(自制)
这是仅使用Unet的LoRA:

图11-4 图11-3
unet:1, Textencoder:0(自制)
这是一个汇总:

图11-5 不同权重汇总(自制)
从这些图片上可以看出:UNet的权重越高,lora的风格也就越深;而Textencoder的权重越高,角色的特征也就越明显。
这可以从发色的渐变来举例,从银色到黄色。当Textencoder渐渐变高时,像发色这样的提示会在一开始就生成;当Textencoder较低时,虽然UNet的不断加权会让整体变得更具有lora风格,但像发色这样的角色特征则变得很慢,更多是更具第一张图的发色进行演变,比如unet为0.6, Textencoder为0.2;unet为0.4, Textencoder为0.4的时候。
至于最好的参数选择?这个受限于模型的质量和主观审美很难有一个合理的判断,我个人的建议是用XYZ plot多跑几张,选出最合适的那一个。
不过需要注意的是,有些lora模型可能并不具有Textencoder & unet权重调整的特质,因此在绘制图像的时候需要明白这个模型能不能做单独的权重调整。
另外有些lora会有特定的prompt词,记得填上去,并注意其书写格式。(直接采用多个lora模型容易产生不同模型间风格、提示词打架的问题,所以lora还有一种比较好的用法是做分层控制,相比于直接融合多个lora模型,它的效果要好一些,这个在网上也有较多的课程)
12. Controlnet
12.1 基本介绍
Controlnet(控制网),它能通过不同的模型进行边缘检测和人体姿势检测,来控制图像生成,以下是两种不同的检测算法,来源于https://stable-diffusion-art.com/controlnet/:
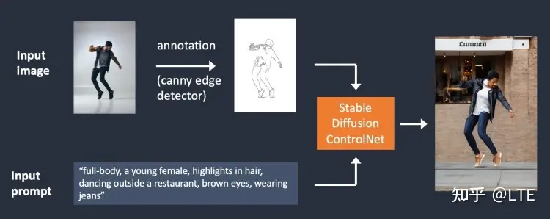
图12-1 边缘检测(基于canny)
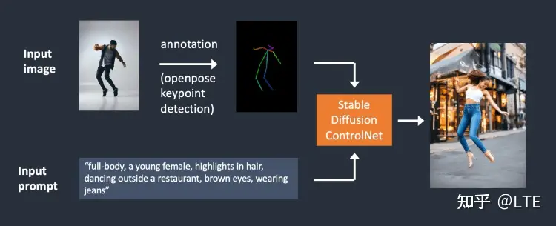
图12-2 人体姿势检测(基于Openpose)
12.2 选项介绍:
写入图标:使用白色图像创建新画布,而不是上传参考图像。它用于直接创建涂鸦。
相机图标:使用设备的相机拍摄照片并将其用作输入图像。你需要授予浏览器访问相机的权限。
交换图标:镜像网络摄像头,用来弄上面那个部分的。
上箭头:将参考图的尺寸发送到文生图的尺寸那里并做替换。

图12-3 部分按钮介绍
低VRAM:适用于VRAM小于8GB的GPU。
像素完美:如果你使用像素完美模式,“预处理器分辨率”滑块将会消失,ControlNet将使用智能算法为你计算最佳分辨率,以便预处理器和SD的每个像素尽可能完美匹配。在大多数情况下,使用此方法比手动更改“预处理器分辨率”更好。
控制类型和预处理器:这些相当于是用来得到结构图(那个预处理图像)的一个方法,每个处理器旁边的中文简称可以得到一个大概的介绍,再配合对应的模型就可以使用了,如下图两个红框类型匹配就好:

图12-4 应有的匹配样式
(具体模型会生成什么的例子可以参考这篇文章:https://zhuanlan.zhihu.com/p/640637930)
控制权重:Controlnet权重控制控制图相对于提示的遵循程度。权重越低,ControlNet对图像遵循控制图的要求就越少。
引导介入时机和引导终止时机:作用于采样步数的机制。0表示第一步,1表示最后一步。引导介入时机设置为0即代表开始时就介入,设置为0.5时即代表ControlNet从50%步数时开始介入计算。引导终止时机则代表着结束的时候,下面是一个例子:

图12-5 原图

图12-6 不同ControlNet步骤的生成图(自制)
可见,更改结束ControlNet步骤的影响较小,主要影响是开始的那个步骤。造成这个的原因是因为:全局组合是在开始步骤中设置的。
控制模式:顾名思义,就是启用controlnet控制、
缩放模式:
·
仅调整大小:独立缩放控制图的宽度和高度以适合图像画布。这将改变控制图的纵横比。
·
裁剪后缩放:使图像画布适合控制图。裁剪控制图,使其与画布大小相同(但会缺失某些部分)。
·
缩放后填空空白:使整个控制图适合图像画布。使用空值扩展控制图,使其与图像画布的大小相同(会增多某些部分)。
下面是对比图(在这里我会大幅更改生成图的宽高比例以做展示):

图12-7 不同缩放模式的对比(自制)
13. 脚本
13.1 提示词矩阵
提示词矩阵(PromptMatrix):类似于xyzplot,不过是基于prompt词的,为了测试不同提示词的效果。这个举个例子大家就明白了:
masterpiece,bestquality,1girl,sunlight|
blackgloves|
whitehair|
maturefemale|
lightsmile
在第一个字符“|”前面的事基本提示词,用在每一张图上,后面的被|符号分组的提示词们会变成交错添加的元素,产生一个成果组合图:

图13-1 应用提示词矩阵的效果(自制)
13.2 从文本框或文件载入提示词
从文本框或文件载入提示词:一种批量生成图片的功能,它的语法规则是这样的:
要求每个参数用--作为分隔,参数间要空一格,提行后作为新的一个图来产生,比如:
--prompt"1girl"
--prompt"1girl"--negative_prompt"lowres,badanatomy,badhands,text,error"--width512--height512--sampler_name"DPM++2MKarras"--steps20--cfg_scale7--seed9
--prompt"1girl"--steps15--sampler_name"DDIM"
--prompt"1girl,masterpiece,bestquality"--width1024
图13-2 从文本框或文件载入提示词的效果(自制)
按照每行不同的要求生成了四张图片,每行一一对应着一个图片。
13.3 X/Y/Z plot
X/Y/Z plot:创建具有不同参数的多个图像网格。X和Y用作行和列,而Z网格用作批量维度。使用X类型、Y类型和Z类型字段选择哪些参数应按行、列和批次共享,并将这些参数以逗号分隔输入到X/Y/Z值字段中。对于整数和浮点数,支持范围。写法如下:
括号内增量范围:
1-5(+2)=1,3,5
10-5(-3)=10,7
1-3(+0.5)=1,1.5,2,2.5,3
方括号中包含计数的范围:
1-10[5]=1,3,5,7,10
0.0-1.0[6]=0.0,0.2,0.4,0.6,0.8,1.0
13.4 ControlNet-M2M
ControlNet-M2M:可以使用它根据ControlNet设置从视频创建一系列图片,然后生成一段视频,也就是重绘视频。
在此之前,需要将这两个选项在设置—ControlNet中勾上:

图13-3 需勾选的内容
然后在脚本中启用ControlNet-M2M,也要按之前所讲的启用合适的ControlNet,并输入txt2img设置。建议固定种子值以减少闪烁。更改种子将更改背景和角色的外观。
最后点击生成:

图13-4 效果图(自制)
可以看出,ControlNet-M2M的视频极为闪烁,而且人物风格不定。(加了lora后有些鬼畜)
其实比较好的一种AI生成动漫的方式可以参考一位国外老哥做的视频,他们用两个月的时间炼制出了一套类似于真人转欧美漫画的模型,以真人动作为基础做出来的一个7分钟的动漫视频。
不得不说,频闪的弊病消失了不少,而且人物非常稳定,内容也挺好玩的,这是传送门:
动漫视频:https://www.youtube.com/watch?v=GVT3WUa-48Y
制作历程:https://www.youtube.com/watch?v=_9LX9HSQkWo
看完之后感觉真的是——太酷啦!
速速学一波老外,不过是走3D模型路线,跑小姐姐跳舞视频!(类似于B站很多转3D的AI动画)
出自:https://zhuanlan.zhihu.com/p/649749094