背景
很多人觉得AI绘画不稳定,对于以后替代插画师、摄影工作者、设计师、表示存疑,作为AI从业者从AI绘画关键技术分析,以前生产者肯定会被淘汰,现在没有到达黄金期。
技术一定会让更多人失业,而我们拥抱变化,增强自身。
AI绘画中Stable Diffusion 占领开源方案9成以上。Stable Diffusion(稳定扩散)是一种先进的深度学习模型,用于生成高质量的图像。它的关键技术包括多个版本演化、VAE(变分自编码器)、UNet架构、CLIP文本编码器、分类器引导技术、以及注意力机制等。
版本演化
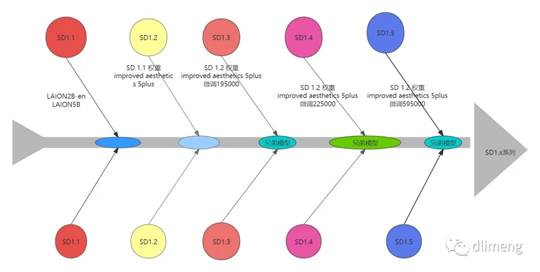
“improved
aesthetics” 主要指这次升级提升了 Stable Diffusion 在图像质量和艺术风格上的表现,使其生成的图像更富艺术感和审美价值。
5plus 指的是 Stable Diffusion 模型的配置版本
·
SD 1.1:首个版本,提出improved aesthetics,优化图像质量,使用4plus模型配置。
·
·
SD 1.2:引入大数据集LAION-2B进行训练,提高了图像质量,使用5plus模型配置。
·
·
SD 1.3:过渡版本
·
·
SD 1.4:在图像生成效果上有较大提升,训练迭代次数增加到195000步。
·
·
SD 1.5:继续改进美学效果,使用5plus模型,训练达到225000步,可以生成更高质量图片。
·
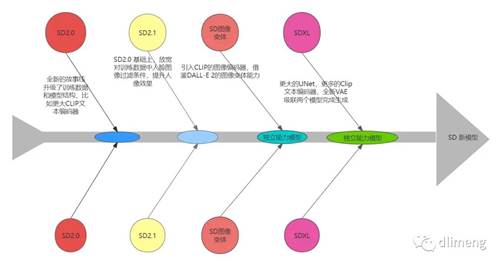
SD新模型
·
SD2.0:这是Stable Diffusion的一个主要版本。它在之前版本的基础上实现了显著的改进,特别是在图像的美学质量和生成模型的细节上。
·
·
SD2.1:这个版本进一步优化了之前版本的特性。强调了更有效的文本编码器,使用了更先进的CLIP版本,生成的图像与文本提示的一致性和相关性有所提升。
·
·
SD变种:这可能是Stable Diffusion的一个变体版本,具有特殊的属性或针对特定应用场景的优化。
·
·
SDXL:这是Stable Diffusion的一个扩展版本。演化更大的模型(比如使用了更大的UNet),或者训练了更广泛的数据集。强调了CLIP文本编码器和VAE的改进,提供了更准确的文本到图像的转换能力。
·
Stable
Diffusion 2.x系列:
SD 2.0:基于CompVis模型,提升细节生成能力。SD 2.1:引入Hypernetwork,支持无限分辨率生成。
SD 的演化过程中,最主要的变化就是模型结构和训练数据的变化。SD1.x 系列,大多数是在 SD1.2 的基础上继续微调得到的,包括我们使用最多的 SD1.4 和 SD1.5 模型;SD2.x
系列则是新开的故事线,使用了全新的模型结构。
结构关系
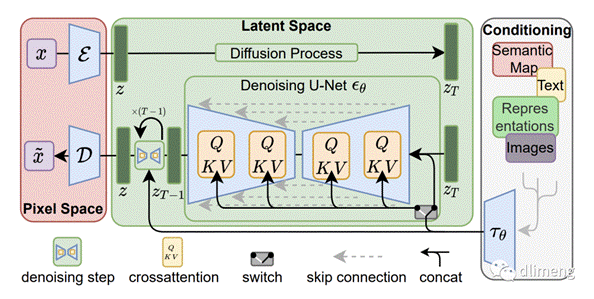
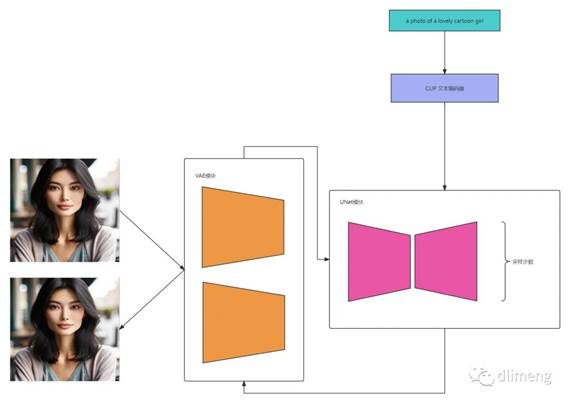
VAE(变分自编码器)
在Stable Diffusion (SD) 技术中,VAE 起到了关键的作用。原始的扩散模型,虽然在生成图像方面表现出色,但存在两个主要限制:
·
一是它不能直接从文本提示(prompt)生成图像,而是从纯噪声开始,其生成过程不可控且随机性较大;
·
·
二是它直接在图像空间进行加噪和去噪,这在处理高分辨率图像时需要消耗大量的计算资源,尤其是显存。
·
VAE 作用:
·
将扩散过程从图像空间转移到潜在空间。VAE的编码器可以将图像压缩为潜在空间的向量表示,在潜在空间进行扩散过程,再通过解码器恢复图像,这样可以大大提高计算效率。
·
·
压缩图像表示。通过VAE的编码器可以获得压缩后的图像向量表示,相比原始图像大大减少了计算和存储成本。
·
·
提高图像生成质量。VAE的编码-解码结构具有一定的去噪效果,可以生成更高质量的图像。
·
VAE详细文章
UNet架构
UNet主要通过其跨尺度的上下文学习和精确的像素预测,提供了高质量和高分辨率的图像生成能力。
UNet详细文章
CLIP文本编码器
CLIP通过跨模态的图像文本表示,为Stable Diffusion提供了精确的条件图像生成和语义一致的图像编辑能力。
CLIP详细文章
文本引导原理探秘
现在主流AI绘画模型,文本引导图像生成的过程采用了无分类器引导(Classifier Free
Guidance)
原始的扩散模型从随机噪声出发,并不能用文本控制内容。于是,OpenAI 在论文中便提出了有分类器引导。
利用预训练的分类模型对生成的中间结果进行识别和评估,得到当前图像的分类信息,然后将该信息反馈回生成模型,引导其生成符合期望类别的图像。
算法1:分类器引导的扩散采样
这个算法描述了如何使用分类器来引导扩散模型的采样过程。
算法2:分类器引导的DDIM采样
DDIM(Denoising Diffusion Implicit Models)是一种扩散模型的变体,它允许更快的采样过程。这个算法使用分类器引导来执行DDIM采样。它的步骤如下:
1. 输入和算法1相同。
2. 同样从标准正态分布中采样一个向量作为开始。
3. 通过迭代过程,从 T 到 1 对进行采样。
4. 在每一步 ( t ),使用来计算噪声,然后用分类器来引导这个噪声的方向。
5. 使用这个引导的噪声来更新并采样
6. 这个过程重复直到 t=0,最后返回
通过这两种算法,分类器引导的扩散模型可以生成更符合类别标签 ( y ) 的图像。
这种方法对于条件图像生成来说是非常有效的,因为它可以引导生成过程朝着满足特定条件的方向发展。在实践中,
这意味着可以生成更符合用户需求的定制化图像。
采样器详细
注意力机制
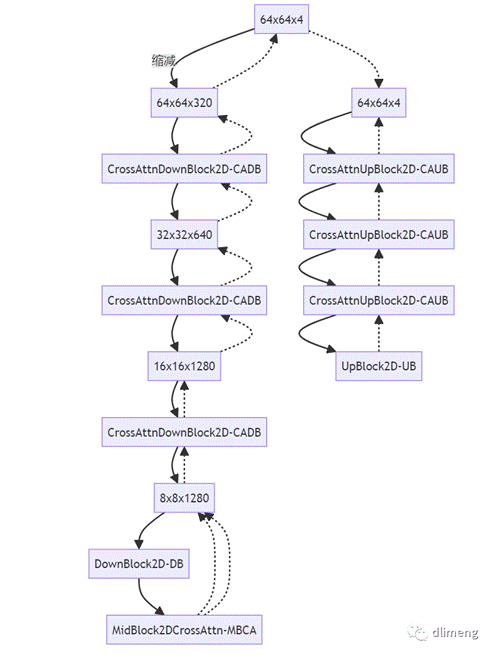
1. SD 模型基于潜在扩散模型,通过变分自编码器实现从图像空间到潜在空间的压缩和扩展。
2. 利用 CLIP 等模型的文本编码器,将文本转化为文本表征,并通过交叉注意力机制将文本信息融入图像生成过程。
3. SD 的扩散模型是一个大规模的 UNet,在编码器部分使用了多个带交叉注意力的 CADB 模块。
4. CADB 模块包含自注意力模块和交叉注意力模块,实现文本表征与图像特征的交互。
5. 文本表征通过交叉注意力计算 K、V 向量,与自注意力模块的 Q 向量结合,实现文本信息的注入。
6. 时间步编码直接作用于 CADB 模块中的 ResnetBlock,与文本表征共同引导图像生成。
7. 通过调节采样步数和 CFG Scale,可以控制生成图像与文本提示的匹配程度。
在这里插入图片描述
图生图 Negative Prompt 和 CLIP Skip
解密Negative Prompt 作用
反向描述词可以避免模型生成不想要的内容,起到负样本的作用。将无条件预测中的空字符串替换为反向描述词,告诉模型应避免生成什么内容。
最终噪声 = w * 条件预测 + (1 - w) * 反向描述词预测
通常我们的引导权重大于 1,比如取 7.5 这个数值,使用反向描述词便可以引导模型避免生成我们不想要的内容。
解密 CLIP Skip = 2 作用
使用CLIP文本编码器的倒数第二层而不是最后一层特征。最后一层特征可能丢失语义信息,因为CLIP通过成对数据训练,图文不总对应。
倒数第二层特征更接近原始文本语义,可以让模型更听话。(经验值)
结语
以上内容从底层角度把Stable Diffusion介绍完,相信也知道AI绘画刚起步,为了各个模块规模和优化有很多路要走。
AI生成一定会淘汰更多生产者,拥抱使用AI,提升竞争能力。
出自:https://mp.weixin.qq.com/s/i_0d6qw1kgQ9McMnOaW9Sw