随着各种AI模型的快速发展,选择合适的模型成为了研究和开发的一大挑战。最近一段时间,国产模型不断涌现,让人应接不暇。尽管开源的繁荣提供了更多的选择,实际上也造成了选型的困难,尽管业界提供了很多评测基准,但是,很多模型在公布的评测结果中对比的模型基准和选择的测试基准都很少,甚至只选择对自己有利的结果。为了更加方便大家对比相关的结果,DataLearner上线了大模型评测综合排行对比表,给大家提供一个更加清晰的对比结果。我们主要关注的是国内开源大模型和一些全球主流模型的对比结果。
DataLearner大模型综合评测对比地址如下:https://www.datalearner.com/ai-models/llm-evaluation
下图是一个截图:
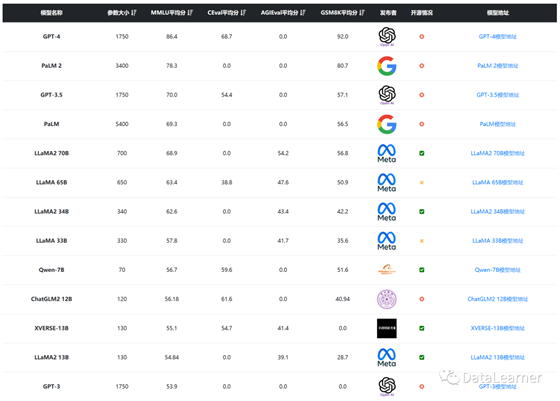
·
为什么要做大模型的综合对比
·
·
各大国产模型在不同评测基准上的表现
·
§
MMLU的评测结果
§
§
C-Eval评测结果
§
§
AGI Eval评测结果
§
§
GSM8K的评测结果
§
·
总结
·
为什么要做大模型的综合对比
简单来说就是希望有一个排行榜可以展示不同模型的评测结果。最近一段时间,清华大学ChatGLM2-6B、阿里巴巴的千问大模型、百川的大模型都陆续开源,中文大模型一篇繁荣。尽管各家在推出自己模型的时候都公布了一些评测结果,但是不同模型选择的评测基准不一样,很难给大家统一的对比结果。例如,有些模型对比结果没有公布业界经常使用的MMLU,而是选择了一些不知名的排行榜,看似结果很好,其实很难有说服力。
为此,DataLearner收集了31个大模型,其中约一半都是国产开源大模型,通过收集它们在MMLU、C-EVAL等评测上的评测结果给大家统一展示对比。
首先,给大家介绍一下DataLearner目前收集的4个评测基准:
·
MMLU :全称Massive
Multitask Language Understanding,是一种针对大模型的语言理解能力的测评,是目前最著名的大模型语义理解测评之一,由UC Berkeley大学的研究人员在2020年9月推出。该测试涵盖57项任务,包括初等数学、美国历史、计算机科学、法律等。任务涵盖的知识很广泛,语言是英文,用以评测大模型基本的知识覆盖范围和理解能力。论文地址:https://arxiv.org/abs/2009.03300
·
·
C-Eval :C-Eval
是一个全面的中文基础模型评估套件。由上海交通大学、清华大学和匹兹堡大学研究人员在2023年5月份联合推出,它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别。用以评测大模型中文理解能力。论文地址:https://arxiv.org/abs/2305.08322
·
·
AGI
Eval :微软发布的大模型基础能力评测基准,在2023年4月推出,主要评测大模型在人类认知和解决问题的一般能力,涵盖全球20种面向普通人类考生的官方、公共和高标准录取和资格考试,包含中英文数据。因此,该测试更加倾向于人类考试结果,涵盖了中英文,论文地址:https://arxiv.org/abs/2304.06364
·
·
GSM8K :OpenAI发布的大模型数学推理能力评测基准,涵盖了8500个中学水平的高质量数学题数据集。数据集比之前的数学文字题数据集规模更大,语言更具多样性,题目也更具挑战性。该项测试在2021年10月份发布,至今仍然是非常困难的一种测试基准,论文地址:https://arxiv.org/abs/2110.14168
·
可以看到,这四种大模型评测结果都有各自的针对性,从一般的知识与广泛的能力到中英文,再到数学推理,应该说是基本可以覆盖大多数的需求。
各大国产模型在不同评测基准上的表现
并不是所有的大模型都公布了自己在这些评测基准上的结果。但是,经过DataLearner工作人员的收集,基本上覆盖到了可以搜集的结果。下面我们将针对这些评测结果做一个总的概述。
MMLU的评测结果
如前所述,MMLU是一个侧重于一般性广泛的知识能力,涵盖了很广的知识范围。不过主要是英文数据集,但是这个评测对于模型的语义理解等都有较好的评测结果。
下图是所有模型的对比:
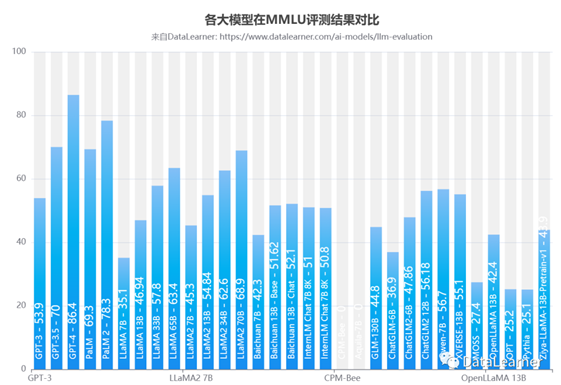
从结果看,这个评测被大家的接受程度也很高。除了2个模型(清华大学NLP小组的CPM-Bee和智源AI研究院的Aquila,十分难以理解的结果)外,大家都公布了自己的得分。
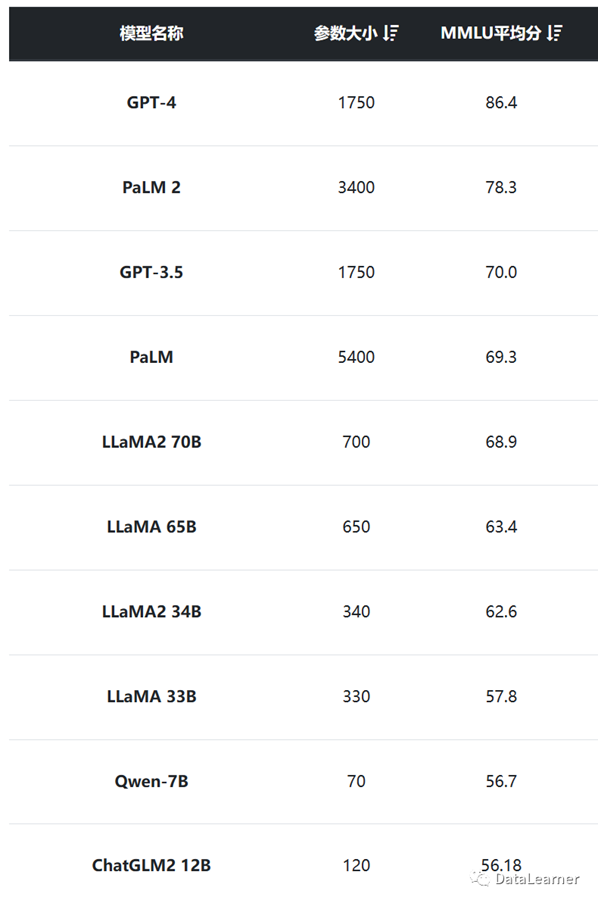
毫无疑问,得分最高的是GPT-4,也是唯一一个超过了80分的模型。而谷歌家的模型这一点表现也很不错。其次就是MetaAI开源的LLaMA系列,甚至第一代的LLaMA 65B依然排名第六。而国产模型中阿里巴巴的千问大模型Qwen-7B和智谱AI的ChatGLM-12B也进入了前10,分别是第九和第十。
C-Eval评测结果
C-Eval主要评测的是中文能力。虽然官方排行榜的第一名是智谱AI的ChatGLM2,但是由于该模型并不是已公开的某个版本,我们这里也没有收集。结果如下:
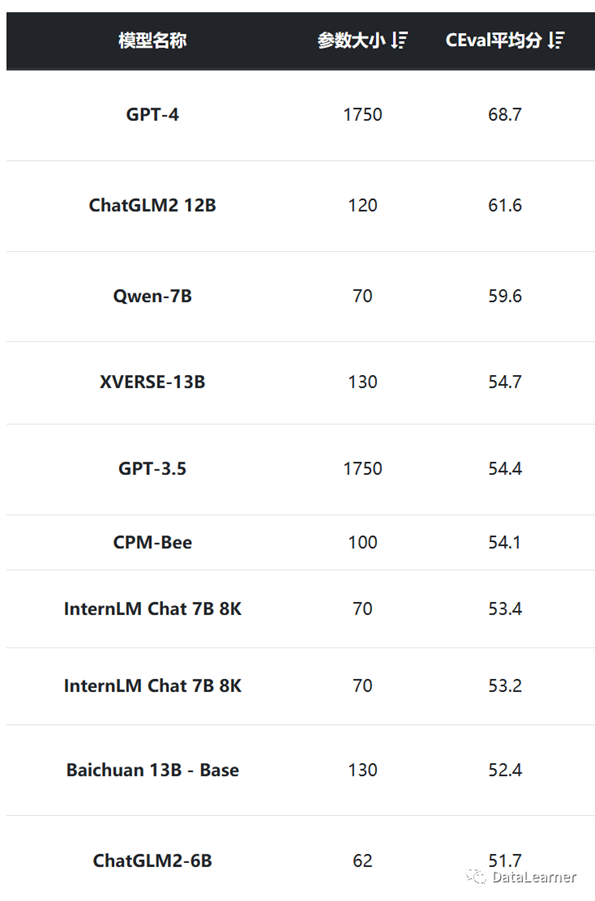
在这个评测排名中,国产模型大幅进步。尽管第一名依然是GPT-4,但是第二名已经是智谱AI的ChatGLM2
12B了,且得分插件不大。而排名前10的模型中,除了OpenAI的GPT-4和GPT-3.5外,都是国产模型。当然,这也与本次排名中大多数国外模型很少参与这个排名有关。或者一些模型也不支持中文。就不多赘述。
AGI Eval评测结果
AGI Eval是微软提供的评测工具。不过可惜的是很多模型并没有相关的数据。而已有的模型排名如下:
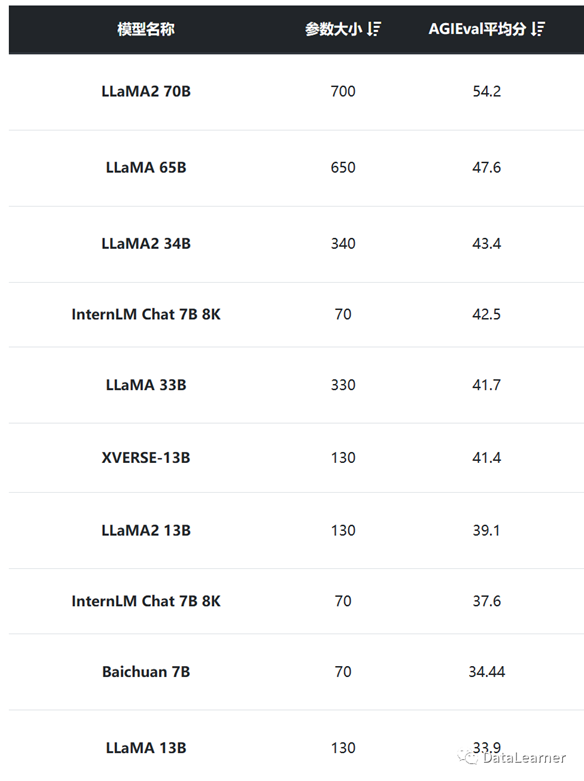
从这个评测结果看,LLaMA的表现很好,而上海人工智能研究院的书生大模型InternLM与元象科技的XVERSE-13B表现都不错。不过,ChatGLM系列没有相关的评测结果,非常可惜。
GSM8K的评测结果
GSM8K是针对数学推理的评测任务,显然也是非常困难的任务。排名如下:
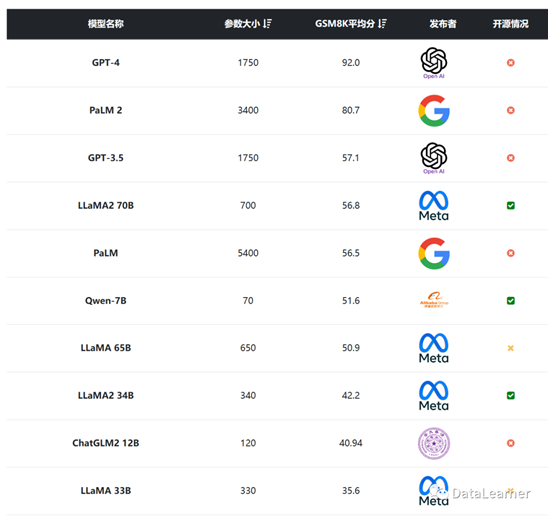
GSM8K的结果不出意外的是GPT-4与谷歌的PaLM2排名靠前。而国产模型中,千问大模型和智谱AI的ChatGLM2 12B表现也不错。尽管如此,与GPT-4的差距非常大,基本上也就只有它的一半得分。
总结
大模型的评价其实非常复杂,与大家的应用场景也有很大关系。不过,从这些排名看,结果与大家实际使用过程中应该大致是符合的。GPT-4与谷歌的模型在各方面表现都非常好。而国产大模型中,智谱AI的ChatGLM2系列与千问大模型表现也很稳。
希望有更多的大模型可以公布自己的结果,为大家提供一个更好的选择。
数据说明:所有数据来源于论文或者GitHub上的评测结果,以官方论文为主,部分数据来源第三方评测!
出自:https://mp.weixin.qq.com/s/lVQorSHWUmYjDK2MgVm9bg