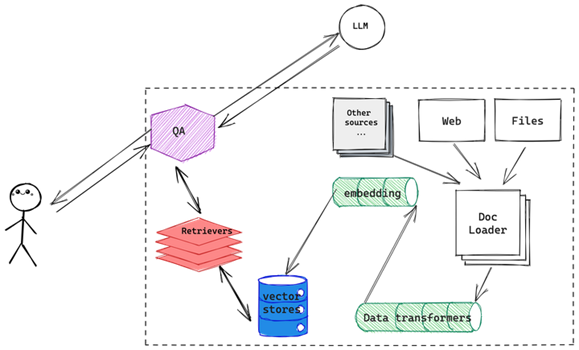
图一:RAG 结构图
在当前这个时间点(2023.9.6)打开 langchain.com 的主站,你会发现不同于之前的 docs 关于应用场景的 8 种介绍,Use-Cases 部分明确的分为了 RAG 和 Agents 两部分,说明这两个月以来,业界对落地的思考慢慢收敛到了这两部分,尤其是 RAG(RetrievalAugmentedGeneration),其实算是一个比较新的词,接下来我们分别从这两个维度来看下最近 LLM 落地的进展。
·
RAG,Retrieval-Augmented
Generation, 众所周知本次 llm 浪潮主打的就是一个 Generation,生成,而 Retrieval-augmented 就是指除了 llm 本身已经学到的知识之外,通过外挂其他数据源的方式来增强 LLM 的能力,这其中就包括了外部向量数据库、外部知识图谱、甚至直接把现有的 ES 接入,或者干脆把现有的生产环境下的搜索引擎接入等方式。接入的方式也大同小异,首先检索外挂数据源中与用户给出的上下文相关的内容,合并之后做 embedding 给到所用的 llm ,最后由 llm 根据模型自己的认知,做出回答。说到底就是一个 map-reduce 的过程,当然 langchain 里面也进一步细化,增加了比如 refine 这种机制,思路一致,实现方式略有区别。详细的介绍可以去翻一下之前写的相关记录。
·
Agents, 如果说 RAG 是通过外挂知识达到让 llm 在垂直领域应用落地的目的,Agents 就是让 llm 学会现实世界中的各种“规则”,比如互联网的各种 API,比如 web 上的各种按钮交互怎么做等等,几年前有个哥们供职于国内做 App 测试服务的头部企业,提出了一个很灵魂拷问的问题,能不能把机器学习应用于 App
自动测试?当时的情况是 BERT 刚刚出来,Transformer
的魔法还没有蔓延到 CV 领域,所以这哥们提的问题相当于需要单独拎出来几个模型,分别把图像识别、意图识别、用于模拟用户行为的代码生成等等单独做一遍,然后再通过某种方式的胶水代码粘在一起,可以想想,效果很差,今时不同往日,突然想到这个问题可以拿出来重新做一遍了。
说回来 RAG,词儿很新,后面代表的事情其实是近一年来业内一直在探索的事情。接下来我们还是画个图来看一下整个 RAG 场景是怎样做到 LLM 和外部数据结合的(图一),这张图显示了 LLM 是如何利用外挂信息库的方式来完成自身能力增强或落地的,这个外挂的信息库不限于向量数据库、传统搜索引擎甚至 DBMS 也可以,正是各种不同的应用场景决定了不同的数据源,根据下图中来自
langchain 官网的图片,截至目前,langchain 已经支持了:
·
154 种数据源的 loader
·
47 种不同的向量存储方式
·
37 种数据
embedding 方式
·
65 个不同大模型的支持

LLM 大模型外挂涉及到的组件数量
具体的数字无需关注,需要看到的是 LLM 大模型外挂数据技术涉及到的组件数量正在以惊人的速度爆发,组件越多,LLM 能力落地的触角也就越深入。
再看下 Agents

「Turn your LLMs into reasoning engines」,reasoning engines 推理引擎,这什么意思呢?翻译一下其实两层含义,第一个,LLMs 会去阅读你提供的 APIs 的说明文档,学会这些 APIs 的实现的目的、使用方式、组合方式,根据你提出的总体要求,按照它自己关于这些
APIs 的理解来拆解成不同的小任务,小任务都完成最后凑成一个大任务完成,到你这交差。需要注意的是,这里的
APIs 不仅仅是指我们传统认为的,网络空间中的 APIs,还可以是操控物理世界里面的开关、机械臂等等实物的「APIs」;第二个含义,由于目前跟 LLMs 交互的实现方式其实是类似 HTTP 协议这种,「无状态」的交互,所以每次交互的上下文是需要通过在类似「chat_history」这样的变量里面保存的,每次交互都把上下文内容带上。
综上,所谓的 reasoning engines 就是基于 LLMs 的理解任务、拆解任务、执行任务的集合。这个思路经过 OpenAI 的两位重要技术人物, Andrej Karpathy 和 Lilian Weng 在近期不遗余力的鼓吹之后,成功变成了 LLMs 落地的另一篇超蓝海。下面是来自 Lilian Weng 的一张图解:
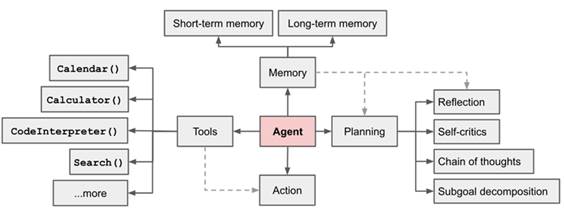
Overview of a LLM-powered autonomous
agent system
接下来将分别从 RAG/Agents 两个方向分别找典型例子实验、记录一下。
出自:https://zhuanlan.zhihu.com/p/654662274