背景:ChatGPT - 或许是2022年末开始至今最热的新词之一,这个词汇如热浪一般席卷大街小巷,充斥朋友圈和各大网站,它的爆火程度简直让人瞠目结舌。ChatGPT的炙手可热点燃了全球AI的狂潮,让曾经有些冷清的AI领域重新燃起了昂扬的风帆。ChatGPT的惊世之举,让大家见识到通用人工智能的辉煌崛起,也让AI在文本创作、摘要提炼、多轮对话甚至代码生成等领域迈向了一个质的飞跃。本文是从零开始了解AI大模型系列的概念篇,带你走进大模型的世界。

AI大模型概念

现阶段大家讨论的AI大模型一般都是围绕着“自然语言”方面的基础大模型。大模型通过海量数据和超高数量的参数,实现面向复杂问题的“预测”能力。
大家可能也有听到一些相关名词或术语如“大模型”、”LLM大型语言模型”、”GPT”、”ChatGPT”和”AIGC”,这些名词之间有什么区别或联系?
简而言之,"大模型"是具有大量参数(通常指在10亿以上)和卓越性能的Transformer结构模型,而"LLM大型语言模型"则是指针对自然语言处理的大型模型,目前在LLM人类自然语言领域取得巨大突破,主要代表为GPT(OpanAI研发的“LLM” 大模型),并且通过针对性的“再训练与微调”实现在人类对话领域的爆炸性效果(ChatGPT),ChatGPT则是AIGC在聊天对话场景的一个具体应用。最后,AIGC是AI大模型自动创作生成的内容,是AI大模型的一种重要应用。
大模型
具有大规模参数和计算能力的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表示能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。它们可以通过训练海量数据来学习复杂的模式和特征,并具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
LLM大型语言模型(Large Language Model)
通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI 的 GPT-3 模型。这些模型可以通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。大型语言模型在自然语言处理、文本生成和智能对话等领域有广泛应用。
GPT(Generative Pre-trained Transformer)和ChatGPT
都是基于Transformer架构的语言模型,但它们在设计和应用上存在一些区别。GPT模型旨在生成自然语言文本并处理各种自然语言处理任务,如文本生成、翻译、摘要等。它通常在单向生成的情况下使用,即根据给定的文本生成连贯的输出。ChatGPT则专注于对话和交互式对话。它经过特定的训练,以更好地处理多轮对话和上下文理解。ChatGPT设计用于提供流畅、连贯和有趣的对话体验,以响应用户的输入并生成合适的回复。
AIGC( AI Generated Content)
是由AI自动创作生成的内容,即AI接收到人下达的任务指令,通过处理人的自然语言,自动生成图片、视频、音频等。AIGC的出现,就像是打开了一个全新的创作世界,为人们提供了无尽的可能性。从用户生成内容(UGC),到专业生成内容(PGC),再到现在的人工智能生成内容(AIGC),我们看到了内容创作方式的巨大变革和进步。
AI大模型历史
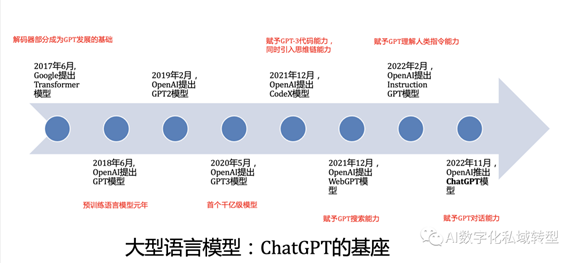
ChatGPT的底层技术框架源于2017年Google推出的Transformer,这个模型采用了Attention机制,彻底颠覆了传统深度学习中的循环和卷积结构,直接呈现了实现“大一统模型”的雄心壮志。2018年6月,openAI发布了第一代GPT(Generative Pre-Training),基于Transformer Decoder的改进,有效地证明了在自然语言处理领域使用预训练+微调方法的有效性。紧接着,同年10月,Google推出了基于Transformer
Encoder的Bert,在相同的参数规模下,其效果一度超越了GPT1,成为自然语言处理领域的佼佼者。
然而,openAI并不满足于此,仅仅依靠增加模型大小和训练数据集来达到与Bert相媲美的效果显然不够高明。于是,他们在GPT2中引入了zero-shot技术,并成功地证明了其有效性。此后,openAI在LLM(大型语言模型)的道路上义无反顾地前行,在2020年6月推出了庞大的GPT3,拥有高达1750亿的参数量,各种实验效果达到巅峰水平。传闻一次训练的费用高达1200万美元,这使得GPT系列成为普通工业界踏足的一座高山,但也因其高昂的代价成为一个不可忽视的挑战。
2022年11月推出的ChatGPT被戏称为AI界的“iPhone时刻”,以它为代表的生成式AI使每个人都能像命令手机一样指挥计算机来解决问题。无论是生产工具、对话引擎,还是个人助手等各种应用,它都扮演着协助、服务,甚至超越人类的角色。这一革命性突破让ChatGPT在搜索引擎和各种工具软件中掀起了应用的热潮,吸引了广大用户对ChatGPT相关技术的极大兴趣和学习热情。
AI大模型概念术语
AI大模型领域有许多常用术语,了解这些术语对于理解和探索这一领域非常重要,以下是建议大家需了解的常用概念术语:
人工智能(AI)是研究、开发用于模拟、延伸和扩展的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它致力于理解智能的本质,并生产出一种能够以人类智能相似的方式做出反应的智能机器。
AGI(Artificial General Intelligence)是指通用人工智能,专注于研制像人一样思考、像人一样从事多种用途的机器。它与一般的特定领域智能(如机器视觉、语音识别等)相区分。
生成式AI(AI-Generated
Content)是基于人工智能技术,通过已有数据寻找规律,并通过适当的泛化能力生成相关内容的技术。它可以生成图像、文本、音频、视频等内容。
LLM(Large Language Model)是大型语言模型,用深度学习算法处理和理解自然语言的基础机器学习模型。它可以根据从海量数据集中获得的知识来识别、总结、翻译、预测和生成文本和其他内容。
NLP(Natural Language Processing)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法,主要应用于机器翻译、文本分类、语音识别等方面。
Transformer模型是一种深度学习模型架构,广泛应用于自然语言处理任务。Transformer模型以自注意力机制为基础,已成为众多AI大模型的核心架构。
注意力机制(Attention Mechanism)是一种用于处理序列数据的机制,允许模型在处理输入序列时对不同位置的信息分配不同的注意力权重。这对于理解长文本和建立语境非常有帮助。
参数量(Model Parameters)是指的是神经网络模型中的可调整参数数量。AI大模型通常有数亿到数千亿的参数,这些参数用于存储和学习模型的知识。B是Billion/十亿的意思,常见6B模型是60亿参数量的大模型。
微调/精调(FineTuning)是针对大量数据训练出来的预训练模型,后期采用业务相关数据进一步训练原先模型的相关部分,得到准确度更高的模型,或者更好的泛化。
指令微调(Instruction FineTuning)是针对已经存在的预训练模型,给出额外的指令或者标注数据集来提升模型的性能。
强化学习(Reinforcement Learning)是一种机器学习方法,其中模型通过与环境的互动来学习决策策略,以最大化某种奖励信号。在某些应用中,AI大模型使用强化学习进行决策。
RLHF(Reinforcement Learning from Human Feedback)是一种涉及多个模型和不同训练阶段的复杂概念,用于优化语言模型的强化学习方式,依据人类反馈来进行训练。
涌现(Emergence)或称创发、突现、呈展、演生,是一种现象。许多小实体相互作用后产生了大实体,而这个大实体展现了组成它的小实体所不具有的特性。研究发现,模型规模达到一定阈值以上后,会在多步算术、大学考试、单词释义等场景的准确性显著提升,称为涌现。
泛化(Generalization)模型泛化是指一些模型可以应用(泛化)到其他场景,通常为采用迁移学习、微调等手段实现泛化。
思维链CoT(Chain-of-Thought)是通过让大语言模型(LLM)将一个问题拆解为多个步骤,一步一步分析,逐步得出正确答案。需指出,针对复杂问题,LLM直接给出错误答案的概率比较高。思维链可以看成是一种指令微调。
出自:https://mp.weixin.qq.com/s/DiwgAc6ysEHSJfmmJ-L-1A