背景:ChatGPT - 或许是2022年末开始至今最热的新词之一,这个词汇如热浪一般席卷大街小巷,充斥朋友圈和各大网站,它的爆火程度简直让人瞠目结舌。ChatGPT的炙手可热点燃了全球AI的狂潮,让曾经有些冷清的AI领域重新燃起了昂扬的风帆。ChatGPT的惊世之举,让大家见识到通用人工智能的辉煌崛起,也让AI在文本创作、摘要提炼、多轮对话甚至代码生成等领域迈向了一个质的飞跃。本文是从零开始了解AI大模型系列的技术篇,带你走进大模型的技术世界,初步开始了解大模型。

一、 AI大模型核心技术
AI大模型,简称“预训练语言大模型”,堪称机器学习的瑰宝,蕴含着“预训练”和“大模型”两大精粹元素,这两者的融合孕育了一种全新的人工智能典范。该模型在大规模数据集上经过预先磨砺,免去了繁琐的微调过程,甚至只需微量数据的调整,就能立刻投身各种领域的应用,简直像是一把多合一的魔法钥匙,能打开各种“任务”的锁。举个例子,一款预训练语言模型既能胜任自然语言分类、命名实体识别和指代消解等任务,也能轻松处理智能对话、阅读理解和文本生成等自然语言生成任务。
黑板报划重点:这里最重要的两个技术原理,第一Transformer是模型的设计架构,第二是Pre-trained预训练。
1.1 关键技术原理一:Transformer模型架构
Transformer模型起源:ChatGPT的底层框架脱胎于2017年Google发布的Transformer模型,此模型引入了注意力机制,彻底颠覆了传统深度学习中的循环和卷积结构,彰显了实现“大一统模型”的雄心壮志。Transformer架构来源于下图一篇被誉为神级论文的《Attention is
all you need》,值得一提的是,这篇论文的八位大神号称Transformer 谷歌八子都已离开公司并创业,可见AI领域的蓬勃发展。

Transformer是一个崭新的端到端模型,采用了注意力机制来巧妙地捕获上下文信息。它的整体结构由编码器和解码器组成,非常灵活。这个模型被广泛应用于各种任务,包括将一种语言翻译成另一种语言的翻译工作、将图片中的文字变成可读的文字的OCR(光学字符识别)任务等等。正因如此,这个模型才如此地名副其实,被称为"Transformer"。
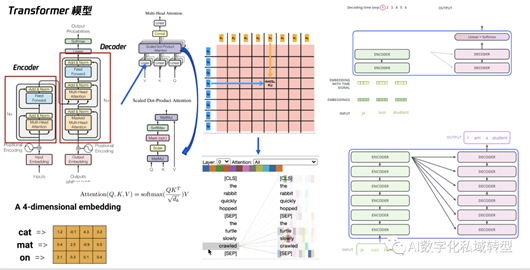
黑板报划重点-科普说人话:Transformer最重要的两个概念是“编码器和解码器构成的端到端模型”和“可以捕获上下文信息的注意力机制”。
1. 编码器和解码器构成的端到端模型
Transformer模型堪称将编码器-解码器思想与注意力机制完美融合的杰作。在模型结构上,GPT模型只采用了Transformer模型的解码器部分,但GPT与Transformer的用途有着天壤之别。Transformer的诞生旨在解决如翻译等实际任务,而GPT的出现则源于先进的预训练思维。
2. 大模型LLM架构方向Encoder & Decoder
目前,许多大型语言模型(LLM)采用了Decoder-only的架构。个人观察是,OpenAI为整个行业提供了成功的范例,因此越来越多的人选择效仿他们的做法。然而,在GPT3之前,以BERT为代表的Encoder-only架构才是主流。然而,随着OpenAI的不断努力,包括创建拥有数百亿参数的大型模型、进行大规模预训练以及使用高质量语料数据,Decoder-only模型的优势逐渐显现出来,尤其是在生成任务方面。
未来,我们可以预期会看到Encoder-decoder和Decoder-only之间的竞争和探索,这将推动模型架构的进一步发展和改进。在不同的应用场景和任务中,不同的架构可能会有各自的优势,因此模型的选择可能会取决于具体的需求和性能要求。
黑板报划重点-科普说人话:目前业界的主流大型语言模型架构受到OpenAI成功的Decoder-only架构的启发,但是否Decoder-only比Encoder-decoder架构更适用于大型语言模型的问题尚未有明确的结论。
3. 注意力机制
注意力机制是一种用于处理文本数据的机制,它通过卷积计算解决了循环神经网络(RNN)无法真正双向捕获上下文以及无法并行计算的限制。为了模拟人类对不同事物具有不同关注程度的特点,人们提出了使用三种向量及相应的计算方法来模拟这种关注行为。举例来说,Q向量可以看作是某个人的关注点,V向量可以看作是具体的事物,而K向量可以看作是人对不同事物的关注程度。通过计算Q向量和K向量的点乘,可以得出一个值,表示这个人对某个事物的关注程度,然后将这个关注程度与V向量相乘,以表示这个事物在这个人眼中的表现形式。这样的方式使得模型能够更好地捕捉文本中不同部分的关联性和重要性。
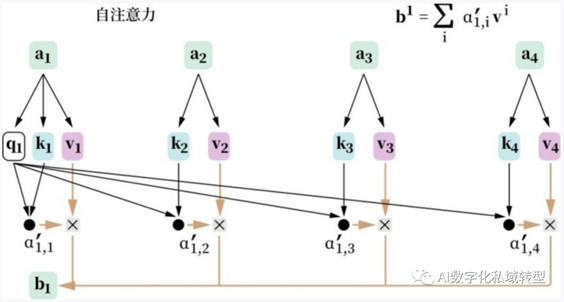
黑板报划重点-科普说人话:注意力机制就像模拟人类思考的方式,它可以帮助计算机更好地理解文本中的关系。就像人们在看待事物时,会把更多的关注放在某些部分,而不是平均对待所有东西一样。这种机制注意力机制就是可以捕获上下文信息,允许计算机集中精力关注文本中不同部分,从而更好地理解上下文信息。
1.2 关键技术原理:预训练Pre-trained模型
预训练大模型的原理是基于深度学习和自监督学习的思想。它的核心思想是通过大规模的无监督学习来培训一个通用的神经网络模型,然后在特定任务上微调它,以使其适应特定的应用。这一方法已经在自然语言处理和计算机视觉等领域取得了巨大的成功,使模型能够在各种任务上表现出色。
预训练分为两个步骤。首先是预训练,通过自监督学习从大规模数据中获得一个与特定任务无关的模型。这个步骤有助于模型理解词语在不同上下文中的语义表示。第二步是微调,针对具体的任务对模型进行调整。训练数据可以是文本、文本-图像对或文本-视频对。预训练模型的训练方法可以使用自监督学习技术,如自回归的语言模型和自编码技术。这些模型可以是单语言的、多语言的,也可以是多模态的。经过微调后,这些模型可用于各种任务,包括分类、序列标记、结构预测和序列生成,同时还可以构建文摘、机器翻译、图片检索、视频注释等应用。
预训练模型的发展趋势包括:首先,模型规模越来越大,参数数量也越来越庞大,例如从GPT-2的1.5亿参数到GPT-3的惊人1750亿参数。其次,预训练方法不断增加,从自回归语言模型到各种自动编码技术,以及多任务训练等。第三,模型的应用领域不断扩展,涵盖语言、多语言、代码和多模态等多个方面。最后,研究还在模型压缩方面不断进行,以使这些模型能够在移动设备等资源有限的环境中高效运行。
黑板报划重点-科普说人话:预训练模型的核心思想就像拥有一把多功能的通用钥匙,这把钥匙可以打开各种不同“任务”的锁。这意味着只需一个通用模型,就可以应对各种不同的算法任务,无论是智能对话、阅读理解、还是文本续写等任务。这种灵活性使得预训练模型在多个领域都能发挥作用,从而提高了其在人工智能应用中的通用性和效能。
二、GPT自回归大模型的演进和技术

2.1
GPT-1:筑基Decoder-only自回归架构,生成式预训练语言模型GPT的奠基者
GPT-1是GPT系列的第一个模型,它采用了12个Transformer模型的解码器进行堆叠,形成了一种预训练语言模型。由于Transformer解码器的主要功能是在每次训练过程中生成一个单词,因此GPT系列模型又被称为“生成式预训练语言模型”。与其他预训练语言模型类似,使用GPT-1完成各种具体任务也需要经过两个步骤:预训练(Pre-Training)和微调(Fine-Turning)。
其涉及的关键理论和技术如下:
无监督预训练:训练使用的数据都是自然文本数据,不需要人工针对不同任务对数据打标签,因此该过程叫作“无监督预训练”。训练数据不需要人工标注,这让数据获取的工作量大大降低,使搜集大规模高质量的数据成为可能。
有监督微调:GPT-1模型需要将待训练的分类文本打上相应的标签,比如判断文本的情感态度是积极的还是消极的,这往往需要用数字来表示态度类别。这一过程就是人工标注,使用这种数据进行训练,也被称为“有监督训练”。因此,微调过程也被称为“有监督微调”(Supervised Fine-Tuning,SFT)
黑板报划重点-科普说人话:GPT-1是生成式预训练语言模型GPT的奠基者,筑基Decoder-only自回归架构,其关键技术涉及到预训练(Pre-Training)和微调(Fine-Turning)
2.2
GPT-2:扩大GPT-1参数量和预训练数据量,应用Prompt和Zero-shot开始可支持多任务的通用大模型
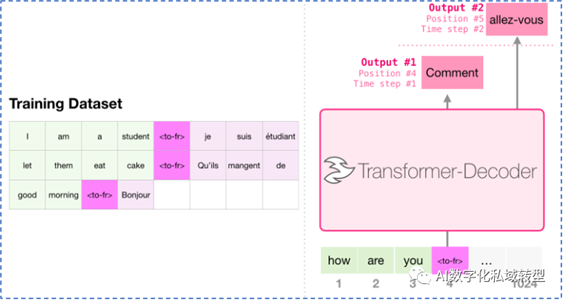
GPT-2模型的核心思想是摒弃了GPT-1中的微调环节和预训练步骤,转而将合理的问题作为输入,让模型通过文字生成的方式直接生成答案。这种输入通常被称为一个“Prompt”。从基本结构上来说,GPT-2与GPT-1是一样的,都是多个Transformer解码器的堆叠。然而,GPT-2在解码器的细节方面做了一些调整,比如改变了归一化层的位置,并新增了一层归一化层。更重要的是,GPT-2通过将解码器的堆叠个数扩展到48个,增加多头注意力机制的头数以及位置编码的个数,大大增加了参数量。GPT-1只有1.2亿个参数,而GPT-2的参数量扩展到了15亿,这极大地提高了模型学习文本的能力。与模型参数量的增加相比,预训练数据规模的扩大也是GPT-2不需要微调的关键。GPT-1的预训练数据规模为5GB,而GPT-2的数据规模则扩大到GPT-1的8倍,达到40GB。
GPT-2在训练数据上的获取方式相当独特。它从著名的在线社区Reddit上爬取了具有问答特性的训练数据,并根据社区用户的投票结果筛选出优质的内容。通过这种方式,GPT-2成功训练出了1.5亿参数量,并且取得了与BERT相媲美的效果。
其涉及的关键理论和技术如下:
Prompt:将合理问题作为输入(Prompt),令模型直接通过文字生成的方式生成答案。
零样本学习(Zero-shot
Learning):只给出任务描述(description)和任务提示(prompt)。任务也可以通过设计相应的Prompt来完成,这里的Prompt中并没有任何关于问题应该如何回答的提示。
黑板报划重点-科普说人话:GPT-2是扩大GPT-1参数量和预训练数据量,不需要像GPT-1进行各任务微调,应用Prompt和Zero-shot开始可支持多任务的通用大模型。
2.3
GPT-3:大力出奇迹并引入上下文学习,落地 few-shot少样本学习
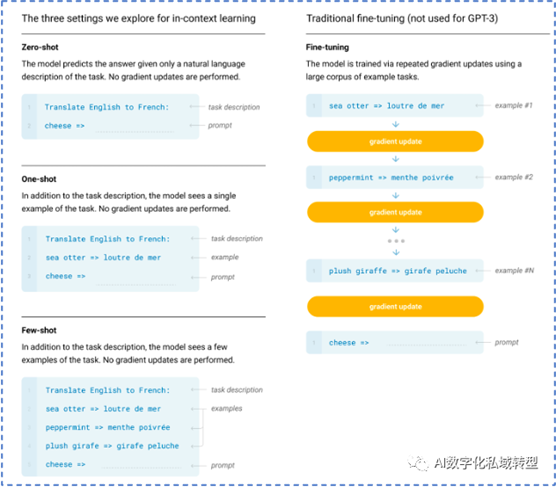
GPT-3可以说是GPT-2的强化版,从GPT-2的15亿个参数量增加到1750亿个。GPT-3的训练数据不再是单纯的自然语言文本,而是针对具体任务的高质量Prompt,并且每个Prompt中都会包含十几个到几百个案例提示。总而言之,GPT-3可以被看作模型参数和预训练数据量增加的GPT-2。
GPT-3实际上可以被看作是GPT-2的强大进化版,将模型参数数量从GPT-2的15亿个飙升到了惊人的1750亿个。同时,GPT-3在训练数据方面也经历了一场革命性的变革。它不再依赖单纯的自然语言文本,而是采用了一种高度质量的"Prompt",而且每个Prompt中都包含了十几个到几百个案例提示。这种全新的训练方式使得GPT-3具备了更为广泛的应用能力,可以处理各种复杂任务。
综上所述,GPT-3可被视为在模型参数和预训练数据量两个方面都取得了显著突破的GPT-2的强大继任者。这一进化使得它在自然语言处理领域成为了一颗璀璨的明星,展示出了无限的潜力。
其涉及的关键理论和技术如下:
小样本学习(Few-shot Learning):给出任务描述,给出若干个例子,给出任务提示。模型根据这些小样本的提示,只需要通过前向计算的方式就可以获得期望的答案
黑板报划重点-科普说人话:GPT-3进一步扩大参数量和预训练数据量,是大力出奇迹的结果,并引入上下文学习,落地 few-shot少样本学习。
2.4
GPT-3.5/ChatGPT:人类反馈强化学习进行后处理生成更符合用户诉求的高质量结果

GPT-3.5/ChatGPT与GPT-3在原理上基本保持一致,但在训练数据方面进行了一些重要的改进。它引入了Codex数据集来进行微调,这使得在ChatGPT中也能展现出对代码的理解和解析能力。ChatGPT在GPT-3的基础上经过人类反馈的强化学习,同时对生成的回答内容进行了"无害化"处理。
"无害化"处理可以看作是对模型结果的一种后处理步骤,旨在确保生成的回答不会包含有害或不适当的内容。这一步骤并没有引入新的技术,而是对模型输出进行了额外的过滤和修正。
可以说,强化学习RLHF和"无害化"处理是GPT-3进化成ChatGPT的关键技术,使其更加适用于各种实际应用场景,并提供更安全和可控的对话体验。这些技术的引入为ChatGPT的性能和可用性带来了显著的提升。
其涉及的关键理论和技术如下:
RLHF(Reinforcement
Learning from Human Feedback):可以将其理解为通过训练一个反馈模型(Reward Model,RM)来模拟人类对语言模型回答的喜好程度,然后借助这个反馈模型使用强化学习的方式来训练语言模型,使其生成的回答越来越符合人类的喜好。
RLHF的训练过程可分为三个核心步骤。
(1) 收集以往用户使用GPT-3的数据,进行有监督微调。
(2) 收集回答质量不同的数据,组合训练反馈模型。
(3) 借助反馈模型,采用强化学习算法PPO训练语言模型。
黑板报划重点-科普说人话:GPT-3.5/ChatGPT是通过强化学习RLHF和"无害化"进行后处理,生成更符合用户诉求的高质量结果。
2.5
GPT-4:史上最强和最接近AGI 通用人工智能的多模态AI大模型
OpenAI的GPT-4技术报告出奇制胜,它没有透露任何模型的架构、参数、训练硬件和算力等具体技术信息。然而,总体而言,GPT-4在各种专业和学术基准上都展现出了与人类水平相媲美的能力,并且显著改善了生成式模型中的虚幻和安全性等问题。
GPT-4更进一步支持多模态数据,包括图片等不同模态的数据识别能力,这一拓展使得GPT-4的应用领域更加广泛,同时也开启了OpenAI的插件应用生态,为未来的应用发展提供了更多可能性。虽然技术细节保持神秘,但GPT-4的实际能力和潜力无疑引领了自然语言处理和人工智能领域的发展方向。
GPT-4目前已知信息如下:
更长的上下文 :ChatGPT支持的最长上下文长度为2048个单词(准确说是token),而GPT-4则大幅提升了这个数字,支持最长32768个单词的上下文。这意味着,GPT-4能够胜任更加复杂的任务。例如,你可以将一篇完整的论文作为输入,让GPT-4解读、摘要论文内容,甚至为你提供对实验分析的深入理解。或者,你也可以让GPT-4阅读冗长的保险条款,为客户解答与保险相关的问题。
支持图像信息 :GPT-4不仅在自然语言领域有着强大的影响力,还开始渗透到计算机视觉领域。它具备了图像识别的能力,可以理解图片中的信息,甚至对图像进行评价。不同于以往的方法,GPT-4不需要将图像转化为文本信息,而是直接将图像作为预训练任务的输入,这让模型能够真正理解图片。
更智能的问答 :GPT-4在回答问题时表现更为出色。举例来说,它可以在SAT(美国高中毕业生学术能力水平考试)中取得高分,甚至通过法律领域相关的专业考试。相比之下,ChatGPT在考试方面的能力相对较弱。此外,GPT-4生成的回答更加安全,不容易引起用户的反感,因此在安全性方面也更为可靠。
黑板报划重点-科普说人话:GPT-4被认为是目前已知的最强大、最接近AGI(通用人工智能)的多模态AI大型模型。它具备了多模态能力,支持插件应用,能够处理更长的上下文信息,并且在智能问答方面表现出色。这使得GPT-4在各种领域和任务中都有着巨大的潜力,为人工智能领域的发展开辟了新的前景。
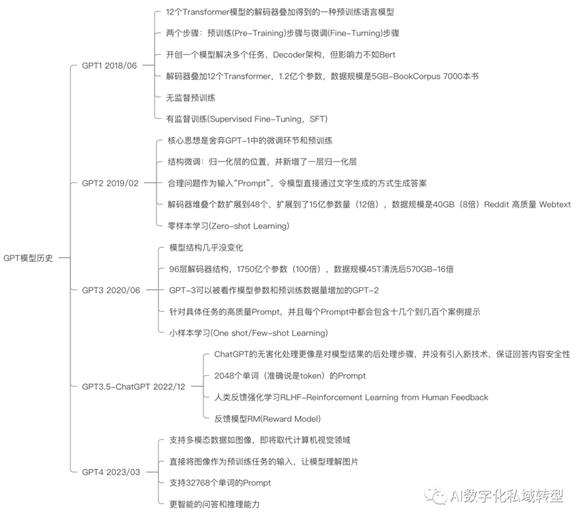
2.6 脑图概览-GPT版本演进版本
一张简易脑图看GPT模型的演进各版本关键点,供大家参考和查询
三、AI大模型技术术语总结
AI大模型领域有许多常用术语,了解这些术语对于理解和探索这一领域非常重要,以下是建议大家需了解的常用偏技术术语的总结:
3.1
Transformer/GPT大模型相关
Transformer模型架构 是一种深度学习模型架构,广泛应用于自然语言处理任务。它以自注意力机制为基础,已成为众多AI大模型的核心架构。
预训练模型(Pre-trained Model)预训练模型是在大规模数据集上完成预训练的神经网络模型。这些模型学习了语言的一般性知识,可以在后续任务中进行微调以适应特定应用。注意力机制(Attention Mechanism)允许模型在处理序列数据时对不同位置的信息分配不同的权重。它在处理长文本和建立语境时非常有用。
编码器(Encoder)是神经网络中的一个组件,用于将输入数据(如文本、图像或音频)转换为中间表示(通常是向量或张量),以便模型能够理解和处理这些数据的信息。在自然语言处理中,编码器通常用于将输入文本转换为一系列词嵌入或句子向量,以便后续任务(如翻译或情感分析)使用。
解码器(Decoder)神经网络中的另一个组件,通常与编码器一起使用,用于将中间表示或编码的信息转换为所需的输出数据。在自然语言处理中,解码器通常用于生成文本序列,例如翻译任务中将编码的源语言文本解码成目标语言文本。
编码-解码模型(Encoder-Decoder Model)是一种通用架构,适用于多种任务,如机器翻译、文本摘要和对话生成。它包括一个编码器和一个解码器,编码器用于将输入数据转换为中间表示,解码器用于生成输出数据。
Token(标记)是文本中的最小单元,通常可以是一个单词、一个字母,甚至是一个标点符号。模型会将文本分割成一系列 Token 来处理和理解。
Embedding(嵌入) 是一种将文本或数据映射到低维向量空间的技术。在自然语言处理中,单词或Token通常被嵌入到一个连续的向量空间中,以便模型能够更好地理解它们的语义关系。
词嵌入(Word Embedding)是将单词映射到连续向量空间的技术,以便模型能够理解单词的语义。Word2Vec 和 GloVe 是常见的词嵌入技术。
Few-shot
Learning(少样本学习)是一种机器学习任务,其中模型需要从非常有限数量的样本中学习并进行泛化,以在新的任务或类别上做出准确的预测。通常,few-shot learning 涉及到使用非常少的训练示例(通常是少于五个或更少)。
One-shot
Learning(一样本学习)是 few-shot learning 的特例,其中模型仅从单个训练示例中学习,然后尝试在新的示例上做出正确的分类或预测。这对于模型来说是一个极具挑战性的任务,因为它需要从非常有限的信息中进行学习和泛化。
Zero-shot
Learning(零样本学习)是一个更极端的情况,其中模型需要在没有任何训练示例的情况下进行分类或预测。模型依赖于有关类别或任务的附加信息,例如属性或语义描述。
In
Context Learning(在上下文中学习)是一种强调模型在处理数据时考虑上下文信息并进行学习的方法。这意味着模型能够根据不同的上下文情境来适应和调整其行为,从而提高了其适应性和泛化能力。
思维链CoT(Chain-of-Thought)是通过让大语言模型(LLM)将一个问题拆解为多个步骤,一步一步分析,逐步得出正确答案。需指出,针对复杂问题,LLM直接给出错误答案的概率比较高。思维链可以看成是一种指令微调。
RLHF(Reinforcement Learning from Human Feedback)是一种涉及多个模型和不同训练阶段的复杂概念,用于优化语言模型的强化学习方式,依据人类反馈来进行训练。
涌现(Emergence)或称创发、突现、呈展、演生,是一种现象。许多小实体相互作用后产生了大实体,而这个大实体展现了组成它的小实体所不具有的特性。研究发现,模型规模达到一定阈值以上后,会在多步算术、大学考试、单词释义等场景的准确性显著提升,称为涌现。
泛化(Generalization)模型泛化是指一些模型可以应用(泛化)到其他场景,通常为采用迁移学习、微调等手段实现泛化。
幻觉(Hallucination)是指在自然语言处理和文本生成领域,大型AI模型有时会生成虚构的、不真实或不合理的信息,而不是基于输入数据的准确信息。这种现象类似于人类产生幻觉,即看到或感知不存在的事物。
鲁棒性(Robustness)鲁棒性指的是模型在面对不同类型的输入或数据变化时能够保持稳定性和可靠性的能力。在AI大模型中,鲁棒性非常重要,因为它们需要处理多样性的真实世界数据。
提示工程(Prompt)是一个在AI大模型领域中经常使用的术语,它指的是一种用户或程序向模型提供的输入,通常是一段文字或问题,用于引导模型生成所需的输出。Prompt 的目的是明确指示模型应该执行的任务或生成的内容,以确保模型生成符合用户期望的结果。
混合专家系统(Mixture of
Experts, MoE)是将预测建模任务分解为若干子任务和训练一个专家模型(Expert Model)开发一个门控模型(Gating Model)。
模型蒸馏(Model Distillation)是一种技术,用于将大型复杂模型的知识传递给小型模型,以便在保持性能的情况下减小模型的大小和计算开销。
推理(Inference)是指根据已有信息和规则来得出新的结论或信息的过程。在机器学习中,推理通常指的是使用训练好的模型来进行预测或分类。
拟合(Fitting)是指在机器学习中调整模型参数以最好地适应训练数据的过程。拟合的目标是使模型能够准确地预测未见数据的表现。
损失函数(Loss Function)是机器学习中的一个关键概念,它用于度量模型的预测与实际数据之间的差异。模型的目标是最小化损失函数,以获得更准确的预测。
梯度下降(Gradient Descent)是一种优化算法,用于最小化损失函数。它通过计算损失函数对模型参数的梯度来更新参数,以找到损失最小的点。
3.2 机器/深度学习相关
神经网络(Neural Network)是一种计算模型,受到人脑神经元工作方式的启发,用于模拟复杂的非线性关系。它在AI大模型中广泛用于处理和理解文本。
机器学习(Machine Learning)是一种人工智能分支,通过使用统计技术,模型能够从数据中学习并进行预测或决策。大多数AI大模型基于机器学习原理。
深度学习(Deep Learning)是机器学习的子领域,它涉及使用深层神经网络来模拟和解决复杂问题。大多数AI大模型,尤其是神经网络模型,都是深度学习的一部分。
强化学习(Reinforcement Learning)是一种机器学习方法,模型通过与环境互动来学习最优的决策策略。模型根据执行动作后的奖励信号来调整策略,这在游戏玩法、机器人控制等领域有广泛应用。
生成对抗网络(Generative Adversarial Network,GAN)是一种深度学习模型,包括生成器和判别器两个部分。生成器试图生成伪造的数据,而判别器则尝试区分真实数据和伪造数据。它们之间的对抗过程驱使生成器不断改进,以生成更逼真的数据,这在图像生成等领域有广泛应用。
迁移学习(Transfer Learning)一种机器学习方法,其中模型从一个任务或领域中学到的知识可以迁移到另一个相关的任务或领域中。这可以加速模型的训练和提高性能。
序列到序列模型(Sequence-to-Sequence Model)是一种深度学习模型,用于将一个序列映射到另一个序列,如机器翻译和文本摘要。
卷积神经网络(Convolutional Neural Network,CNN)是一种特殊类型的神经网络,专门用于处理图像和空间数据。它包含卷积层和池化层,常用于图像分类和物体识别。
循环神经网络(Recurrent Neural Network,RNN)是一种具有循环连接的神经网络,适用于序列数据处理。它们在自然语言处理任务中广泛应用,如语言建模和机器翻译。
自监督学习(Self-Supervised Learning)是一种无监督学习的分支,模型通过自己生成标签或目标来学习。它常用于预训练大模型,如BERT和GPT。
监督学习(Supervised Learning)是一种机器学习方法,其中模型从有标签的数据中学习,并用于进行分类或回归预测。大多数深度学习任务都涉及监督学习。
无监督学习(Unsupervised Learning)是一种机器学习方法,模型从无标签的数据中学习,通常用于聚类和降维等任务。
NLP(自然语言处理,Natural Language Processing)是一种人工智能子领域,涉及计算机如何理解、处理和生成自然语言文本。NLP技术用于机器翻译、情感分析、问答系统等任务。
NLU(自然语言理解,Natural Language Understanding)是一种技术,用于使计算机能够理解和解释人类自然语言文本。它涉及识别文本中的语法、语义和语境信息,以提取有意义的内容。NLU在问答系统、文本分类、情感分析等任务中有广泛应用。
NLG(自然语言生成,Natural Language Generation)是一种技术,用于使计算机能够生成自然语言文本。它涉及将非语言数据(例如数据、图表、知识)转换为可读的文本。NLG在自动生成新闻报道、自动回复生成等任务中发挥作用。
CV(计算机视觉,Computer Vision)是研究计算机如何理解和处理图像和视频的领域。计算机视觉技术用于图像分类、物体检测、人脸识别等应用。
CLIP(Contrastive Language–Image Pretraining)是一种综合了自然语言处理和计算机视觉的模型。它可以理解文本和图像之间的关系,用于图像分类、文本图像检索等任务。
出自:https://mp.weixin.qq.com/s/SyogdXmjzsN7aUOjzEZFeg