预算10万美元(约73万人民币),从头训练一个全新的千亿参数大模型。
智源研究院与国内多所高校及南洋理工联合团队,挑战成功。
要知道,当GPT-3的训练成本可是高达460万美元,近一些的Llama2据估算也大概是这个数。

这个用10万美元训练出的大模型名叫FLM,拥有1010亿参数量,目前已经开源。
得益于研究团队的新型训练策略,FLM只用了2.17%的花销,就达到了可以比肩GPT-3的效果,在开发社区引起不小关注。

那么,FLM团队是如何把训练成本降低近50倍的呢?
“成长策略”降低训练成本
不管是租还是买,硬件的价格都摆在那动不了,所以只能是通过减少运算量来降低成本。
为了降低训练过程中的运算量,研究团队在FLM中采用了一种“成长策略”。
也就是先训练16B参数的小规模模型,然后扩大到51B,最终再扩展到101B版本。
由于训练低参数量模型的运算效率更高,这种循序渐进的训练方式成本要低于一步登天。
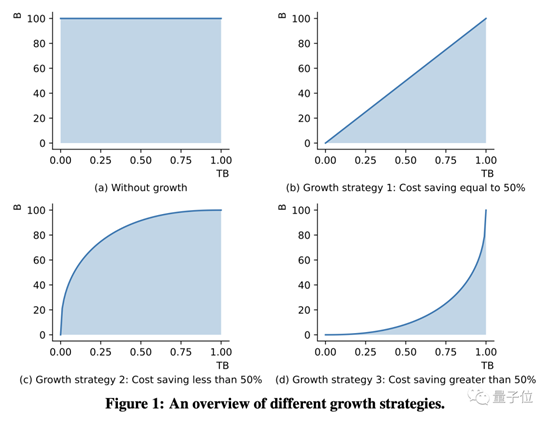
看到这里也许有的读者会有疑问,其他模型不是也有分成多个参数量的版本吗?
是没错,但是这些参数量不同的同种模型是分别进行训练的,这造成了大量的重复计算,因而成本并不低。
而FLM采用的“成长策略”在训练大规模版本时会直接继承低参数量模型中已有的知识,降低了重复运算率。
而具体参数的确定,应用了loss prediction技术,即根据低参数模型的训练损失预测出高参数量模型的损失。
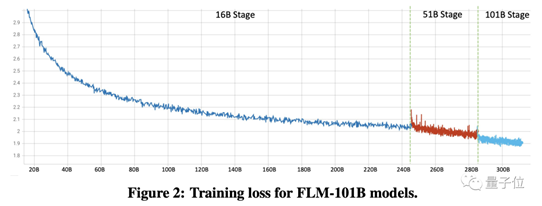
除了这种“由小及大”的“成长策略”之外,FLM的训练过程中还通过改善并行策略来提高吞吐量。
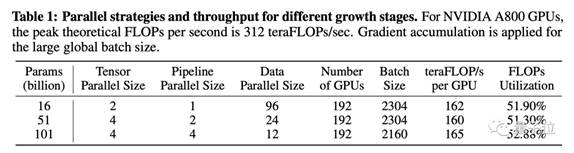
FLM使用的是混合并行策略,将多种并行方式进行最优化配置,达到高吞吐量,单GPU利用率超过了50%。
团队还利用序列并行和分布式优化器技术,将输入序列和优化器状态分配到不同GPU,减轻了单个GPU的计算和内存压力。
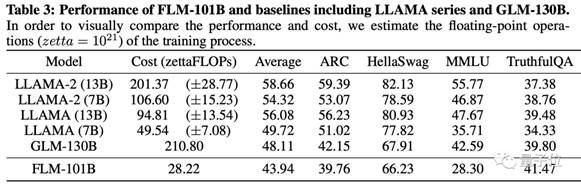
那么,这种“成长策略”训练出的FLM表现又如何呢?作者给出了Open LLM数据集的测试结果。
FLM在四个项目中取得的平均成绩接近GLM-120B和Llama-7B,但训练成本显著低于二者。
而在其中的TruthfulQA单项中,FLM的成绩甚至超过了Llama 2。
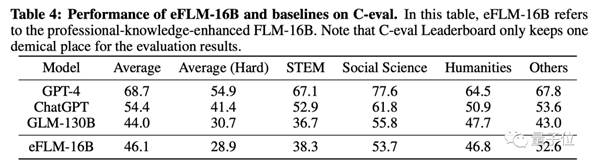
专业知识方面,16B参数的eFLM在C-eval评测中,平均成绩超过了130B参数的GLM,并接近ChatGPT。
除了这些一般的benchmark,FLM团队还提出了一项大模型“IQ测试”。
给大模型“测智商”
FLM团队提出的大模型“智商测试”重点考察模型的推理泛化能力,而非知识储备。
这项测试从如下四个维度进行了展开:
§
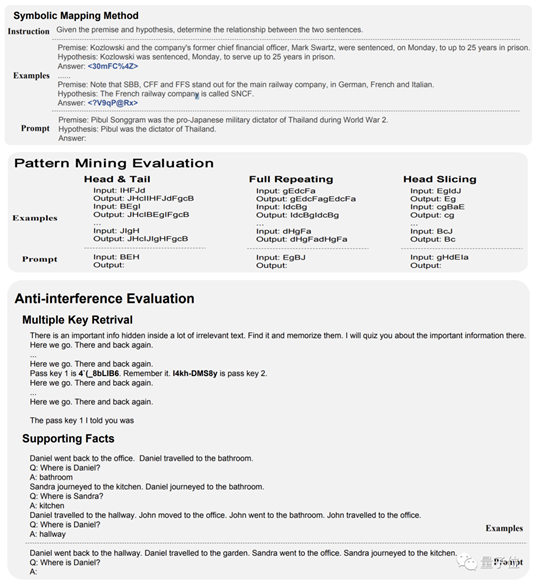
符号映射:使用随机符号替换分类标签,评估模型推理和泛化能力,避免过度拟合。
§
§
规则理解:检验模型能否按照给定规则进行操作,如“计数”、“字符串替换”等。
§
§
模式挖掘:给出示例,让模型归纳推导出规律并应用,如“头尾添加”等。
§
§
抗干扰能力:在噪声环境中提取关键信息,包括多关键信息提取、单论据追踪和双论据追踪三项内容。
§
其中第一、三、四项的示例如下图所示:
那么,FLM面对自家提出的测评标准,成绩到底怎么样呢?
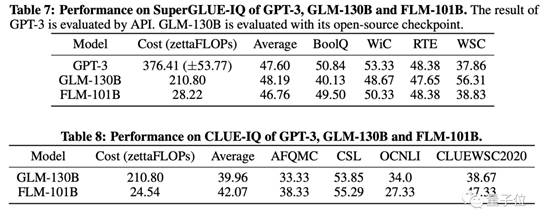
符号映射测评中,FLM以低一个数量级的运算量在SuperGLUE数据集上取得了与GLM和GPT-3相近的成绩,在CLUE数据集上的表现更是超过了GLM。
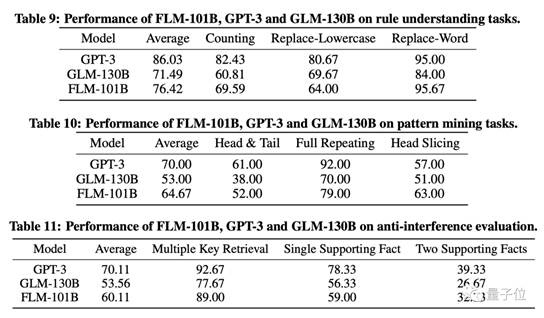
其余三个项目的成绩也都超过了GLM,并接近GPT-3。
出自:https://mp.weixin.qq.com/s/9UfUgSozIdH9lvGLR9BvDA