æŖŌ“±¾µŲ»Æ²æŹšµÄ”øĆīŃ¼Ļą»ś”¹£¬ÕęµÄŅŖøļĮĖ”øŗ£ĀķĢ唹ĆĒµÄĆüĮĖ£æ£üŹÖ°ŃŹÖ½ĢÄć“ī½Ø”øĆīŃ¼Ļą»ś”¹
”¾ŠĀÖĒŌŖµ¼¶Į”æEasyPhoto×÷ĪŖĆīŃ¼Ļą»śĘ½Ģę£¬ÓŠ×Ų»ŹäĆīŃ¼Ļą»śµÄÉś³ÉÖŹĮ棬»¹ÓŠøüŗƵĶØÖĘ»ÆæÕ¼äŗĶ±¾µŲ²æŹšµÄÓÅŹĘ”£
Äź³õÓÉChatGPTŅż·¢µÄAIĄĖ³±±¼ÓæÖĮ½ń£¬³żĮĖOpenAIĶĘ³öµÄµ±ŗģÕØ×Ó¼¦Ö®Ķā£¬ÖŠĪÄ»„ĮŖĶųÄŚČȶČ×īøߵIJśĘ·£¬·ĒĒ°¶ĪŹ±¼ä°ŌĘĮµÄ”øĆīŃ¼Ļą»ś”¹ÄŖŹōĮĖ”£
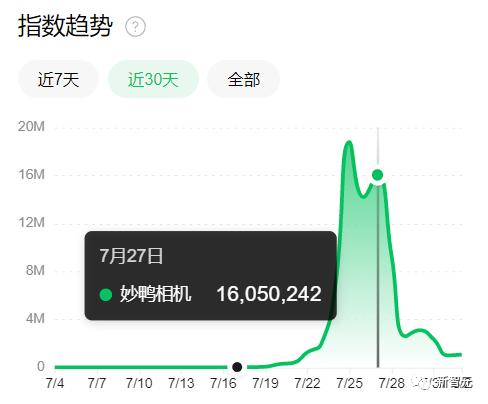
Ö»ŅŖÉĻ“«20ÕÅ×Ō¼ŗµÄ×ŌÅÄÕÕ£¬¾ĶæÉŅŌÓµÓŠŅ»øö×ØŹōµÄŹż×Ö·ÖÉķ”£ÓĆ»§Ö»ÓĆĢōŃ”×Ō¼ŗĻ²°®µÄŠ“ÕęÄ£°å£¬¾ĶæÉŅŌµĆµ½Ņ»ÕÅÕÅ×ØŅµÖŹøŠµÄŠ“Õę”££Ø9æé9µÄĢåŃéŹŪ¼Ū£©

×īøß·åµÄŹ±ŗņ£¬ÓĆ»§½»ĮĖĒ®Ö®ŗóŠčŅŖµČ½Ó½ü10øöŠ”Ź±²ÅÄÜ»ńµĆ×Ō¼ŗµÄŹż×Ö·ÖÉķŗĶŠ“Õę”£Ķų“«Ņ»øöŌĀĮ÷Ė®³¬¹ż1000ĶņČĖĆń±Ņ”£
µ«“ÓÉĻ±ßµÄ”øĆīŃ¼Ļą»ś”¹ĖŃĖ÷Ē÷ŹĘĶ¼Ņ²ÄÜ擳öĄ“£¬Ķųŗģ²śĘ·µÄĖŽĆü£¬ŗÜÄŃĢÓæŖ”ø»šĖŁ“Śŗģ”¹+”ø¼«ĖŁŌÉĀ䔹”£
ŅņĪŖÓĆ»§ŠŅéÖŠ¹ŲÓŚÓĆ»§Źż¾Ż¼«ĪŖĄėĘ׵Ĕø°ŌĶõĢõæī”¹£¬¼ÓÉĻ°ĮĀżµÄ”ø²»ÓčĶĖæī”¹Õž²ß£¬±¬»šÖ®ŗóµÄĆīŃ¼Ļą»śŗÜæģ¾Ķ±»øŗĆęÓßĀŪ·“ŹÉ£¬ČȶČŅ²ŃøĖŁĻĀ»¬”£
¶ųČē¹ūÓĆ»§ÄÜŌŚ±¾µŲ²æŹšŅ»øö”øĆīŃ¼Ļą»ś”¹£¬¾ĶÄÜĶźČ«²»ÓĆČĢŹÜøß·åĘŚ³¤“ļŹżøöŠ”Ź±µÄ”øÅŶÓČ”ÕÕ”¹£¬Ņ²ĶźČ«²»ÓƵ£ŠÄ×Ō¼ŗµÄÕÕʬŗĶÓĆ»§Źż¾Ż±»æŖ·¢ÕߥÄÓĆ”£
ÓɹśÄŚŅ»øöĶŶÓĶĘ³öµÄEasyPhoto£¬¾ĶĆé×¼ĮĖÕāøöĶ“µć£¬ŌŚGithubÉĻæŖŌ“ĮĖŅ»øöÓÉStable Diffusion×÷ĪŖ»ł“”£¬æŖŌ“ĒŅÖ§³Ö±¾µŲ»Æ²æŹšµÄ”øĆīŃ¼Ļą»ś”¹”£

Ķ¬ŃłŅ²ŹĒĶعż5-20ÕÅ×Ō¼ŗÕÕʬµÄѵĮ·£¬±¾µŲ²æŹšµÄÄ£ŠĶ¾ĶÄÜĶعżEasyPhotoĶĘĄķ³öæ°±Č”øĆīŃ¼Ļą»ś”¹µÄŠ“Õę·ēÕÕʬ”£

¶ųĒŅĻą±ČÓŚĆīŃ¼Ļą»ś£¬Ėü»¹Ö§³ÖÉś³É¶ąČĖµÄÕÕʬ”£Ķ¬Ź±£¬ÓĆ»§»¹æÉŅŌ×Ō¼ŗŃ”Ōń³żĮĖSDÖ®ĶāµÄĘäĖūÄ£ŠĶĄ“Éś³ÉŠ“ÕęÕÕʬ”£
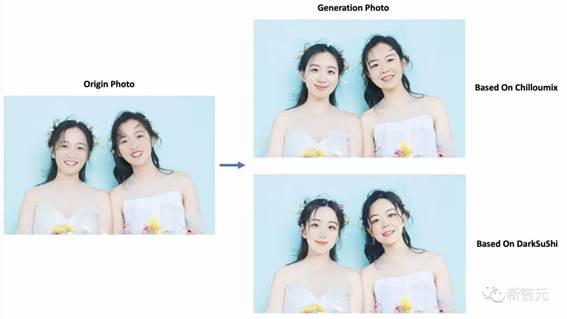
¶ŌÓŚÄĒŠ©¶ÆŹÖÄÜĮ¦ĒæµÄÓĆ»§£¬EasyPhotoĻąµ±ÓŚŅ»øö¼ÓĒæ°ęĒŅĆā·ŃµÄĆīŃ¼Ļą»ś”£
ÉõÖĮ£¬Ö»ŅŖ×Ō¼ŗÓŠ×ć¹»µÄĖćĮ¦×ŹŌ“£¬ÕāøöĶØÓƵĔøAIŠ“ÕęÉś³Éæņ¼Ü”¹æÉŅŌÖ±½ÓĻņĘäĖūÓĆ»§Ģį¹©ŗĶĆīŃ¼Ļą»śĄąĖʵÄAIGC·žĪń”£
Ź¹ÓĆÖøÄĻ
Ä£ŠĶѵĮ·
EasyPhotoѵĮ·½ēĆęČēĻĀ£ŗ
”¤
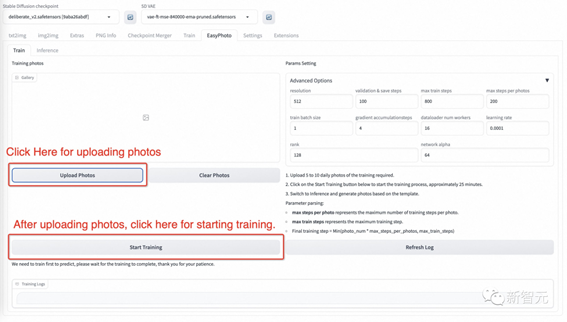
×ó±ßŹĒѵĮ·Ķ¼Ļń£¬Ö»Ščµć»÷ÉĻ“«ÕÕʬ¼“æÉÉĻ“«Ķ¼Ę¬£¬µć»÷Ēå³żÕÕʬ¼“æÉɾ³żÉĻ“«µÄĶ¼Ę¬£»
”¤
ÓŅ±ßŹĒѵĮ·²ĪŹż£¬²»ÄÜĪŖµŚŅ»“ĪѵĮ·½ųŠŠµ÷Õū”£
µć»÷ÉĻ“«ÕÕʬŗó£¬ÓĆ»§¾ĶæÉŅŌæŖŹ¼ÉĻ“«Ķ¼ĻńÕāĄļ×īŗĆÉĻ“«5µ½20ÕÅĶ¼Ļń£¬°üĄØ²»Ķ¬µÄ½Ē¶ČŗĶ¹āÕÕ”£×īŗĆÓŠŅ»Š©²»°üĄØŃŪ¾µµÄĶ¼Ļń”£Čē¹ūĖłÓŠĶ¼Ę¬¶¼°üŗ¬ŃŪ¾µŃŪ¾µ£¬ŌņÉś³ÉµÄ½į¹ūæÉŅŌČŻŅ×µŲÉś³ÉŃŪ¾µ”£
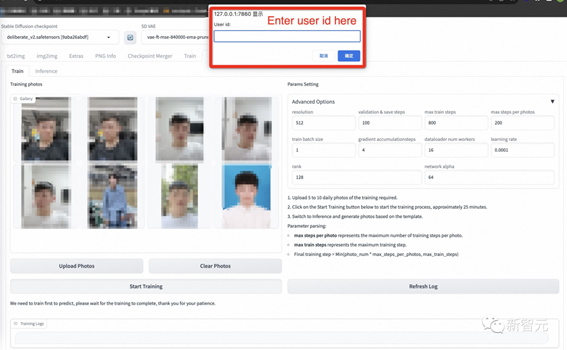
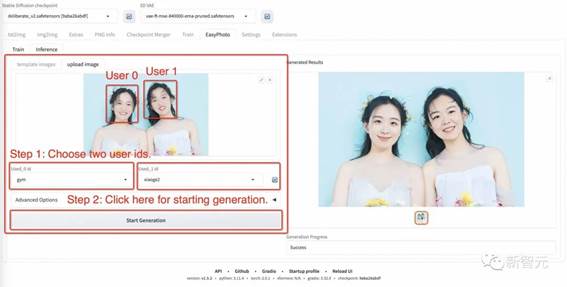
Č»ŗóµć»÷ĻĀĆęµÄ”øæŖŹ¼ŃµĮ·”¹£¬“ĖŹ±£¬ŠčŅŖĢīŠ“ÉĻĆęµÄÓĆ»§ID£¬ĄżČēÓĆ»§Ćū£¬²ÅÄÜæŖŹ¼ÅąŃµ”£
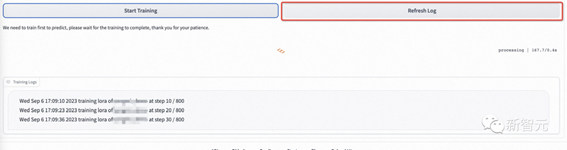
Ä£ŠĶæŖŹ¼ŃµĮ·ŗó£¬webui»į×Ō¶ÆĖ¢ŠĀѵĮ·ČÕÖ¾”£Čē¹ūƻӊĖ¢ŠĀ£¬Ēėµ„»÷”øRefresh Log”¹°“Å„”£
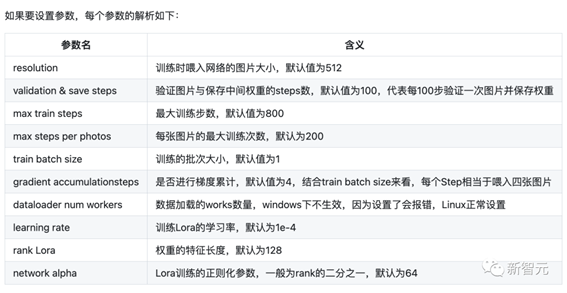
Čē¹ūŅŖÉčÖĆ²ĪŹż£¬Ćæøö²ĪŹżµÄ½āĪöČēĻĀ£ŗ
2.ČĖĪļÉś³É
a.µ„ČĖÄ£°ę
”¤
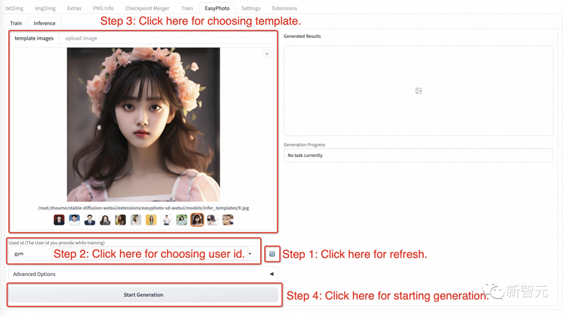
²½Öč1£ŗµć»÷Ė¢ŠĀ°“Å„£¬²éŃÆѵĮ·ŗóµÄÓĆ»§ID¶ŌÓ¦µÄÄ£ŠĶ”£
”¤
²½Öč2£ŗŃ”ŌńÓĆ»§ID”£
”¤
²½Öč3£ŗŃ”ŌńŠčŅŖÉś³ÉµÄÄ£°å”£
”¤
²½Öč4£ŗµ„»÷”øÉś³É”¹°“Å„Éś³É½į¹ū”£
b.¶ąČĖÄ£°å
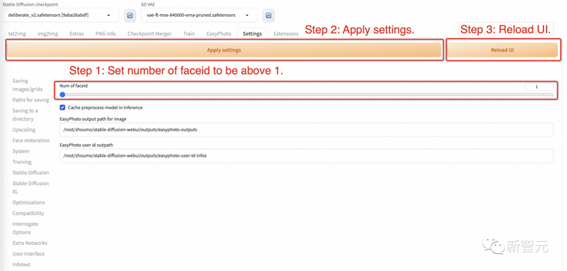
²½Öč1£ŗ×Ŗµ½EasyPhotoµÄÉčÖĆŅ³Ćę£¬ÉčÖĆnum_of_Faceid“óÓŚ1”£
”¤
²½Öč2£ŗÓ¦ÓĆÉčÖĆ”£
”¤
²½Öč3£ŗÖŲŠĀĘō¶ÆwebuiµÄui½ēĆę”£
”¤
²½Öč4£ŗ·µ»ŲEasyPhoto²¢ÉĻ“«¶ąČĖÄ£°å”£
”¤
²½Öč5£ŗŃ”ŌńĮ½øöČĖµÄÓĆ»§ID”£
”¤
²½Öč6£ŗµ„»÷”øÉś³É”¹°“Å„”£Ö“ŠŠĶ¼ĻńÉś³É”£
Ėć·ØĻźĻøŠÅĻ¢
¼Ü¹¹øÅŹö
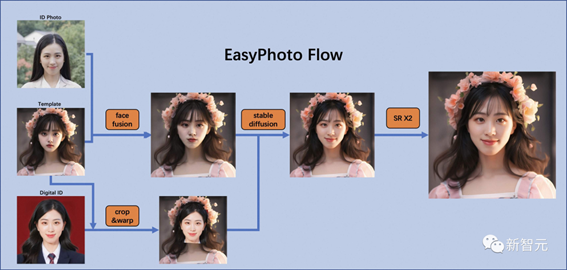
ŌŚČĖ¹¤ÖĒÄÜŠ¤ĻńĮģÓņ£¬ĶŶÓĻ£ĶūÄ£ŠĶÉś³ÉµÄĶ¼Ļń±ĘÕęĒŅÓėÓĆ»§ĻąĖĘ£¬¶ų“«Ķ³·½·Ø»įŅżČė²»ÕꏵµÄ¹āÕÕ£ØČēČĖĮ³ČŚŗĻ»ņroop£©”£ĪŖĮĖ½ā¾öÕāÖÖ²»ÕꏵµÄĪŹĢā£¬ĶŶÓŅżČėĮĖStable DiffusionÄ£ŠĶµÄĶ¼Ļńµ½Ķ¼Ļń¹¦ÄÜ”£Éś³ÉĶźĆĄµÄøöČĖŠ¤ĻńŠčŅŖæ¼ĀĒĖłŠčµÄÉś³É³”¾°ŗĶÓĆ»§µÄŹż×Ö¶žÖŲÉķ”£Ź¹ÓĆŅ»øöŌ¤ĻČ×¼±øŗƵÄÄ£°å×÷ĪŖĖłŠčµÄÉś³É³”¾°£¬²¢Ź¹ÓĆŅ»øöŌŚĻßѵĮ·µÄČĖĮ³ LoRA Ä£ŠĶ×÷ĪŖÓĆ»§µÄŹż×Ö¶žÖŲÉķ£¬ÕāŹĒŅ»ÖÖĮ÷ŠŠµÄStable DiffusionĪ¢µ÷Ä£ŠĶ”£ĻīÄæĶÅ¶ÓŹ¹ÓĆÉŁĮæÓĆ»§Ķ¼ĻńĄ“ѵĮ·ÓĆ»§µÄĪČ¶ØŹż×Ö¶žÖŲÉķ£¬²¢ŌŚĶĘĄķ¹ż³ĢÖŠøł¾ŻČĖĮ³ LoRA Ä£ŠĶŗĶŌ¤ĘŚÉś³É³”¾°Éś³ÉøöČĖŠ¤ĻńĶ¼Ļń”£
ѵĮ·Ļø½Ś
Ź×ĻČ£¬¶ŌŹäČėµÄÓĆ»§Ķ¼Ļń½ųŠŠČĖĮ³¼ģ²ā£¬Č·¶ØČĖĮ³Ī»ÖĆŗ󣬰“ÕÕŅ»¶Ø±ČĄż½ŲČ”ŹäČėĶ¼Ļń”£Č»ŗó£¬Ź¹ÓĆĻŌÖųŠŌ¼ģ²āÄ£ŠĶŗĶʤ·ōĆĄ»ÆÄ£ŠĶ»ńµĆøɾ»µÄČĖĮ³ŃµĮ·Ķ¼Ļń£¬øĆĶ¼Ļń»ł±¾ÉĻÖ»°üŗ¬ČĖĮ³”£Č»ŗó£¬ĻīÄæĶŶÓĪŖĆæÕÅĶ¼ĻńĢłÉĻŅ»øö¹Ģ¶Ø±źĒ©”£ÕāĄļ²»ŠčŅŖŹ¹ÓƱźĒ©Ę÷£¬¶ųĒŅŠ§¹ūŗÜŗĆ”£×īŗó£¬ĻīÄæĶŶӶŌStable DiffusionÄ£ŠĶ½ųŠŠĪ¢µ÷£¬µĆµ½ÓĆ»§µÄŹż×Ö¶žÖŲÉķ”£
ŌŚŃµĮ·¹ż³ĢÖŠ£¬»įĄūÓĆÄ£°åĶ¼Ļń½ųŠŠŹµŹ±ŃéÖ¤£¬ŌŚŃµĮ·½įŹųŗó£¬ĻīÄæĶŶӻį¼ĘĖćŃéÖ¤Ķ¼ĻńÓėÓĆ»§Ķ¼ĻńÖ®¼äµÄČĖĮ³ID²ī¾ą£¬“Ó¶ųŹµĻÖLoraČŚŗĻ£¬Č·±£ĻīÄæĶŶӵÄLoraŹĒÓĆ»§µÄĶźĆĄŹż×Ö¶žÖŲÉķ”£
“ĖĶā£¬ĻīÄæĶŶӽ«Ń”ŌńŃéÖ¤ÖŠÓėÓĆ»§×īĻąĖʵÄĶ¼Ļń×÷ĪŖface_idĶ¼Ļń£¬ÓĆÓŚĶĘĄķ”£
ĶĘĄķĻø½Ś
a.µŚŅ»“ĪĄ©É¢£ŗ
Ź×ĻČ£¬½«¶Ō½ÓŹÕµ½µÄÄ£°åĶ¼Ļń½ųŠŠČĖĮ³¼ģ²ā£¬ŅŌČ·¶ØĪŖŹµĻÖStable Diffusion¶ųŠčŅŖĶæÄصÄÕŚÕÖ”£Č»ŗ󣬽«Ź¹ÓĆÄ£°åĶ¼ĻńÓė×ī¼ŃÓĆ»§Ķ¼Ļń½ųŠŠČĖĮ³ČŚŗĻ”£ČĖĮ³ČŚŗĻĶź³Éŗ󣬽«Ź¹ÓĆÉĻŹöÕŚÕÖ¶ŌČŚŗĻŗóµÄČĖĮ³Ķ¼Ļń½ųŠŠÄŚ»ę£Øfusion_image£©”£“ĖĶā£¬»¹½«Ķعż·ĀÉä±ä»»£Øreplace_image£©°ŃѵĮ·ÖŠ»ńµĆµÄ×ī¼Ńface_idĶ¼ĻńĢłµ½Ä£°åĶ¼ĻńÉĻ”£Č»ŗ󣬽«¶ŌĘäÓ¦ÓĆControlnets£¬ŌŚČŚŗĻĶ¼ĻńÖŠŹ¹ÓĆ“ųÓŠŃÕÉ«µÄcannyĢįČ”ĢŲÕ÷£¬ŌŚĢę»»Ķ¼ĻńÖŠŹ¹ÓĆopenposeĢįČ”ĢŲÕ÷£¬ŅŌČ·±£Ķ¼ĻńµÄĻąĖĘŠŌŗĶĪČ¶ØŠŌ”£Č»ŗ󣬽«Ź¹ÓĆStable Diffusion½įŗĻÓĆ»§µÄŹż×Ö·Öøī½ųŠŠÉś³É”£
b.µŚ¶ž“ĪĄ©É¢£ŗ
ŌŚµĆµ½µŚŅ»“ĪĄ©É¢µÄ½į¹ūŗ󣬽«°ŃøĆ½į¹ūÓė×ī¼ŃÓĆ»§Ķ¼Ļń½ųŠŠČĖĮ³ČŚŗĻ£¬Č»ŗóŌŁ“ĪŹ¹ÓĆStable DiffusionÓėÓĆ»§µÄŹż×Ö¶žÖŲÉķ½ųŠŠÉś³É”£µŚ¶ž“ĪÉś³É½«Ź¹ÓĆøüøߵķֱęĀŹ”£
²Īæ¼×ŹĮĻ£ŗhttps://github.com/aigc-apps/sd-webui-EasyPhoto
³ö×Ō£ŗhttps://mp.weixin.qq.com/s/jCIDMihALIopslyK-rh8lA