AI Agent 今年 4 月在开发者社区格外火热,AutoGPT 成为 Github 历史上涨星最快的项目。火热的背后是 Agent 的思路为我们带来了
Software 2.0 的图景:LLM 作为推理引擎能力不断增强,AI Agent 框架为其提供结构化思考的方法,软件生产进入“3D 打印”时代,可以根据用户需求进行个性化定制,agent 框架打造每个知识工作者信赖的 AI 工作伙伴。
但人们会高估短期影响, Agent 在实际知识工作中还不够可靠。而且在未来,我们也认为 Autonomous Agent 不会是好的商业落地方向,因为其太过强调 LLM 的自驱和自动化规划。
因此,我们认为agent 产品需要具备的特性是,要给产品设计者和用户提供干预空间。目前实践中最具代表性的有两类:中间层的 Agent Framework 和垂直领域的 Vertical Agent。前者能让行业中的领域专家为自己打造 Agent 工作伙伴和工作流分身,使未来的组织更加精简;后者能在某一个领域中深耕行业的最佳实践,并收集到高质量的专有工作流数据。其中 Coding Agent 是这两个方向的结合,潜力很大能成为未来所有 Agent 与人类之间的翻译官。
长期来看,我们对 AI Agent 需要保持耐心。一方面,OpenAI
等大模型公司会在 Agent 标准定义和模型推理能力上持续进化:11 月 OpenAI Devday 可能会踏出定义标准的第一步,当前 next token prediction 的模型对连续的复杂推理问题有根本性瓶颈,需要用更复杂、结构化的数据和目标函数来进一步学习。另一方面,Agent 的应用落地还需要 Generative UI 带来的人机交互方式的革新,就像曾经施乐实验室对个人 PC GUI 的定义。
我们在本文中探讨了对 AI agent 的思考,并对这个领域看好的创业公司进行了 mapping。
以下为本文目录,建议结合要点进行针对性阅读。
👇
01 关于 AI agent 的四个关键问题
02 AI agent
landscape
03 AI Agent 的未来展望
01.
关于 AI agent 的
四个关键问题
What
are agents:
怎么理解 AI Agent
AI agent 是有能力主动思考和行动的智能体。当我们提出需求时,agent 有能力自行感知环境、形成记忆、规划和决策行动,甚至与别的 agent 合作实现任务。对比之下,LLM 是被动的推理引擎,用户每 prompt 点拨一次才会回复一次。
由于 LLM 的能力边界还在快速拓展,其产品形态仍有待探索,LLM-based
Agent 的组件和定义还存在模糊的地方。我们根据现有的实践,归纳了三种理解方式:
1.
AI agent 是 AI-native
software 的开发方法,不是独立的商业赛道或产品形态。
未来的 AI-native 应用都会有 agent 的思路,产品形态可能是 Copilot,也可能还未出现。这一框架下
LLM 是核心推理引擎,而 agent 是使 LLM 扬长避短、结构化思考的方法论。
2. 优秀的 AI Agent 产品比传统软件更灵活,比 LLM 更可靠。
传统软件中有很多规则和启发式算法,带来了高可靠性、确定性,但也使其难以灵活解决长尾问题。优秀的 AI agent 应用需要充分发挥 LLM 推理 (reason)、扮演 (act) 和交互 (interact) 的能力。
短期内,这样的应用会牺牲一定软件的可靠性,因此 agent 应用的落地现状并不乐观。但是沿着当前的技术路径走下去,可以预期在长期达到与当前的传统软件接近的可靠性。
3.
Agent 和早期的 LLM-based 应用相比,有几个显著差异点:
• 合作机制 orchestration:存在多模型、多 agent 分工与交互的机制设计,能实现复杂的工作流。例如编程场景下可能有 developer agents 和 quality
assurance agents,类比开发团队里的工程师和测试;产品战略场景下可能有 growth agents 和 monetization
agents,类比公司中投放和商业化团队在用户规模和商业收入上的多目标博弈。
• 与环境交互 grounding:Agent 能理解自己的不足,并适时从外部寻找合适的工具解决问题。人和动物的区别是人会使用工具,agent 框架能帮助 LLM 认识自己的能力边界,从外部环境中寻找合适的工具。
• 个性化记忆 memory:能记忆用户偏好和工作习惯,使用越久越了解用户。未来的 agent 作为人类的工作伙伴会接受大量文本和多模态信息,过程中积累的用户偏好和工作习惯会使产品成为知识工作者最信赖的伙伴。
• 主动决策 decision:Agent 有能力在虚拟环境中探索、试错、迭代。目前的 LLM 应用还缺少在环境中连续决策的能力,因为 next
token prediction 落子无悔的预测形式和人类的思考方式是截然不同的:开发者在 coding 解题的时候,会对一系列假设方案进行实验总结出最优解,而不是在一开始就能够得到最优解。
以上四个特点的实现时间由短到长排序:
• 短期:Orchestration 和
grounding 短期内值得重点探索,当下 LLM 能力还不够强,需要自己与外部环境交互找到合适的工具,并且由用户专家对 AI 的工作流进行设计和编排,使其成为靠谱的合作伙伴。如果当前的应用在这两个方向上没有足够深的编排和实践,不能称为是 AI agent 应用。
• 中期:Memory 是需要重点强化的方向。随着人类与
AI agent 的信任加深之后,如何让人机协作带来新的数据飞轮是一个相当重要的问题。有了个性化记忆的生成模型,是 Gen AI 时代新形态的推荐引擎。
• 长期:Decision 则是长期目标,也是需要 OpenAI、Anthropic 等大模型公司一起去解决的问题。目前的 next token prediction 模型和 chat-based UI,目标函数太简单很难让
agent 真正学会主动探索、试错,需要模型复杂推理能力和产品形态的双重进化。
说到这里不难发现,当前这个领域还有很多问题等待解决,但我们仍然非常看好 AI Agent 的前景有很强的信心——
So
what: 为什么 AI agent 重要?
1.
AI Agent 将使软件行业降低生产成本、提高定制化能力,进入软件的“3D 打印”时代
Andrej
Karpathy 在著名博客 "Software
2.0" 中探讨过人工智能改变软件开发的方式:Software
2.0 意味着我们可以用大量的数据和算力来解决以前需要大量人力和成本来解决的复杂问题。AI agent 正是这一方式的具象化,因此开发者们对 AutoGPT 的兴奋和 hype 都是情理之中。
AI agent 是达到这一图景的可实现路径:
一方面,成熟的 AI Agent 可以使软件生产大幅降低成本。未来
Coding 工作流中会很多 agent 临时写成的软件和测试方案,不追求长期的可复用性,可以随用随抛。因为其生产是自动化的,软件生产的边际成本趋近于 0(我们倾向于认为未来inference cost
会指数级降低)。目前一家软件行业巨头动辄上万甚至十万人,有了 AI agent 之后研发需要耗费的人力将大幅降低。
另一方面,软件可以灵活地解决更多长尾需求,实现软件生产的“3D打印”。现在能够被抽象成大产品,让公司愿意投入大量人力开发的的软件多是用户量大、标准化、群体性的需求:聊天框、dashboard、CRM 系统。就像工厂出于成本考虑,订单量大到一定程度才愿意为产品开模生产。
但其实有很多相对小众、长尾的需求没有被充分满足,需要用户自己去实现使用过程中的最后一公里。这个问题在 SaaS 系统中经常出现,也带来了比较重的运营和服务成本。而 AI Agent 有潜力能从根本上解决这一问题,就像从工厂流水线生产变成“3D打印”、服装的大货生产变成“小单快反”,为用户带来更个性化的产品。
2.
LLM 扮演人类思考的系统 1(快思考),AI Agent 扮演人类思考的系统 2(慢思考)
Andrej
Karparthy 在 State of LLM 演讲中把 LLM 比作人类的系统 1。这一概念来自行为经济学:人类思考模式可以被分为两个系统,系统1是快速、直觉性的,负责我们的自动反应和本能决策;系统2是慢速、分析性的,负责我们的深思熟虑和复杂决策。
LLM 能胜任系统1的工作,因为它能够快速地处理大量信息并生成反馈,就像人类在听到某事时的快速理解和回答。但 LLM 也会出现幻觉(hallucination)带来的捏造事实问题,这一点同样很像人类的系统 1 中常见的思维谬误和本能反应。
AI agent 的长期目标则是使 LLM 胜任系统2的工作,为 LLM 搭建一套框架来进行深度思考和分析,从而做出更复杂和可靠的决策。一个典型的例子就是 chain/ tree of thoughts 系列研究,通过 prompting 加上 Python glue
code 框架去模拟人类的复杂推理过程,激发出 LLM 更强的智能。
模拟系统 2 的路径会成为未来大模型公司和 Agent 创业公司共同思考和探索的问题。只通过 prompting 这类比较浅的方式无法从根本上进行优化,一定需要优秀的 framework 以及模型的设计优化来做到。这一定是 11 月 OpenAI Devday 进行发布时会考虑的目标。
3. 推荐系统让每个人看到个性化的信息, AI Agent 将让每个人有个性化的工作方式,为每一个知识工作者提供 AI 合作伙伴和工作分身
移动互联网时代,AI重塑了人类接受信息和知识的方式,诞生了
TikTok 这样重要的信息流产品。而来到 Gen AI 时代,LLM-based Agent 将改变人们进行知识工作的方式,诞生优秀的工作方式产品。
工作方式产品指的是人们可以根据自己的工作习惯进行定制化设计,设计自己合作的 AI 同事。当前的 Saas 产品是根据工作者的普遍需求取交集设计的。但实际应用中每个人的使用习惯都有所不同,尤其是高手会有特殊的使用方式。但目前相对机械死板的软件设计并没有给用户灵活设计工作分身的空间。
而 AI agent 有能力实现这一需求。这一点在很多行业专家对 LLM 的使用中能够初见端倪,例如陶哲轩把 GPT-4 当作了自己科研中的 thinking partner,未来好的 agent
framework 将让大家更好地设计和打造自己的合作伙伴。关于这一点,陶哲轩是这么说的:
目前通过努力,人类专家可以将 LLM 不起作用的想法修改为正确和原创的论点。2023级别的AI已经可以为数学家生成建议性的提示和有前景的线索,并积极参与决策过程。我期待 2026 级别的AI,如果使用得当,将成为数学研究以及许多其他领域中值得信赖的合作者。
实现这一需求对业界和学界的知识工作都将带来巨大的变革。公司的组织架构将有一部分外包给 AI agents,顶级组织也可以变得规模很小,这一趋势已经在 MidJourney, Character 这样的新公司身上初见端倪。
同样的思路也发生在科学领域:传统的基于知识的革命需要的时间很长,计数基本单位是按十年计,而
AI agent 有能力将其缩短为按年计。
Framework:
理想的 Agent 框架是什么样的?
Agent 是在大模型语境下,可以理解成能自主理解、规划、执行复杂任务的系统。LLM 是整个系统的“大脑”,围绕其语言理解能力,Agent 系统有以下几个模块组成:
1. 记忆:
LLM 是无状态(stateless)的,大参数量使产品无法基于每一次交互的经验来更新模型的内部参数。不过由于 LLM 能理解大量语义信息,Agent 系统可以在模型之外建立一个记录信息的记忆系统,来模仿人类大脑那样从过往的经验中学习正确的工作模式。
以下分类根据医学中人类的几种记忆方式类比,将 AI agent 的记忆系统分为短期记忆与三种长期记忆:
短期记忆:
• 工作记忆(Working Memory):这一轮决策所需要用到的所有信息。其中包括上下文内容,例如从长期记忆中检索到的知识;也包括 LLM context 以外的信息,例如
function call 时使用其他能力所产生的数据
长期记忆:
• 事件记忆(Episodic Memory):Agent 对过去多轮决策中所发生事情的记忆。每一次 LLM
有了新的行为和结果,agent 都会把内容写进情节记忆。例如在 Generative agents 小镇中,虚拟小镇的 agent 居民会把自己每天看到的事、说过的话计入事件记忆。要使得用户得到个性化的使用体验,这一部分的优化是至关重要的。
• 语义记忆(Semantic Memory):Agent 对自身所在世界的语义知识记忆,一般通过外部向量存储和检索来调用。这一部分记忆可以用类似知识图谱的思路,使 agent 之间的知识更方便共享和更新。同样以 Generative agents 小镇为例,agent 居民会记忆其他居民的爱好、生日等信息,这都是语义记忆。
• 程序记忆(Procedural Memory):在一些特定场景下,agent 执行操作的 workflow 会通过代码的形式在框架中写出来。这类记忆使部分行为能够按照更可控的工作流来执行。以 Generative agents 小镇类比,agent 居民会有自己的行为习惯,比如每天晚上要去某条街散步等等。
2. 行动:
面对不同的任务,Agent 系统有一个完整的行动策略集,在决策时可以选择需要执行的行动。以下罗列几个最常见、重要的行为,实际应用中根据不同场景会有补充和优先级的差异:
• 工具使用:智人与其他动物的重要区别是其使用工具的能力,而 LLM 同样可以通过这一点来扬长避短。AI Agents
可以通过文档和数据集教会 agent 如何调用外部工具的 API,来补足 LLM 自身的弱项。例如复杂的数学计算就不是 LLM 的长处,调用 Calculator() 可以事半功倍。
• 职责扮演:AI agent 系统中,不同 LLM 需要进行分工的机制设计。就像在工厂和公司制中常常出现的角色配合和博弈那样,LLM 之间也需要各司其职,按照各自的职责去完成任务,形成一个完整的协同组织。
• 记忆检索:指的是从长期记忆中找到与本次决策相关的信息,将其放到工作记忆、交给 LLM 处理的过程。
• 推理:从短期工作记忆生成新知识,并将其存入长期记忆中
• 学习:将新的知识和对话历史加入长期记忆,让 Agent 更了解用户
• 编程:AI agent 可以实现很多长尾的开发需求,让软件变得接近定制。而编程是最适合 AI agent 去自己迭代和收集反馈(是否能有效执行)的环境,因为能自己形成反馈的闭环
3. 决策:
前面提到很多行动可以由 Agent 进行规划和执行,而决策这一步就是从中选择最为合适的一个行为去执行。
• 事前规划:LLM 能够将一个大目标分解为较小的、可执行的子目标,以便高效的处理复杂任务。对于每一个目标,评估使用不同行为方案的可行性,选择其中期望效果最好的一个。
• 事后反思:Agents 可以对过去的行为进行自我批评和反省,从错误中吸取经验教训,并加入长期记忆中帮助 agent 之后规避错误、更新其对世界的认知。这一部分试错的知识将被加入长期记忆中
Is
it now: 现状如何?
1.
Autonomous Agent 有很强的启发意义,但缺乏可控性,不是未来的商用方向
Autonomous
agent 指的是完全由 LLM 自驱的规划工作流、并完成任务的 agent 产品,最典型的就是今年 3 月发布的 AutoGPT 和 BabyAGI。AutoGPT 发布以来已经是 Github 历史上涨星速度最快的项目。甚至不到 3 个月就超越了 PyTorch,可见其思想影响力之大。
以 AutoGPT 为首的 Autonomous
agent 其实是把学术圈很多 agent 的点子(例如 ReAct、Reflexion、Generative Agents)用一个简洁的 Python 项目的方式聚合在了一起,让所有开发者感受到了 LLM 作为推理引擎的强大,引发了大量开发者进行各种有趣的实验。最开始大家体验到的是以下优点:
• 智能程度和普适性高,能较好的理解和推理复杂的任务并且做出规划
• 能高效的判断并使用外部工具,整个过程的衔接非常流畅
但随着使用深入,发现其实验性强于实用性,大部分问题并不能真的解决:
• 效果不稳定,多步推理能力不够:大部分产品 demo 看上去效果惊艳,但是对于抽象复杂的问题,能有效解决的比例不到 10%(让AI自我规划容易产生死循环,或者会出现一步走错,步步走错的问题),只适合解决一些中等难度的问题。这需要等 LLM 的下一次技术突破,尤其是其复杂推理能力的提升
• 外部生态融合度不高:第三方 api 支持的数量和生态不多(基本以搜索和文件读取功能为主),很难做到比较完整的跨应用生态
而以上的这两个缺陷正是 existing company 的优势,第一点是
OpenAI/Anthropic 这类 LLM 公司的目标,第二点是 Apple/Google/Microsoft 这类有自己软硬件生态、操作系统公司最适合做的。
因此尽管 AutoGPT 是好的思想实验,但通用的 Autonomous agent 并不适合 startup 作为商业方向。
2.
Agent Framework 和 Vertical Agent
是 AI agent 商业上最可行的两个方向,需要持续探索人机交互的方式
既然 Autonomous agent 不是好的商业方向,现阶段适合创业公司的机会就是需要人为干预和设计的 agent 产品。目前有两类介入使
Agent 更可控的思路,这两类产品从不同的视角切入,我们认为都有未来的商业前景。
当下 AI Agent 领域中 startup 涌现的方向有二:一类是中间层,提供设计 agent 的 infra 工具,由用户介入为 agent 提供规划思路;一类深入细分垂类,运用 agent 思路设计 Copilot 产品,由产品设计者介入是 agent 思路更为可控。
中间层 Infra 关注的是提供实用可复用的
agent framework,降低开发 agent 的复杂度,并为 Agent 的合作提供机制设计。对于这样的中间层基础设施类工具,可以考虑从模块化、适配性、协作等方面进行创新:
a. 模块化设计:这是降低复杂性的关键。模块化设计可以让开发者专注于特定的功能,而不需要关心整个系统的复杂性。有了独立可解耦的感知、决策、执行模块,开发者可以灵活组合以适应不同需求。
这里的模块化要求对 LLM 和 Agent 都有很深的理解,因为在低代码领域,模块化的颗粒度是一直备受讨论的话题,抽象程度太高只能实现简单任务,抽象程度低了其交互又难以承载。而在 agent 这样更新的领域设计难度就更大了,Langchain
最近就遭遇了这样的阵痛。
b. APIs
和 SDKs: 设计通用的接口与协议,让不同的Agent可以兼容配合。这些工具应当包括各种插件,以便于在不同的环境中灵活地部署和使用 Agents。这里潜在的风险是 OpenAI
有在密切关注与设计 agent 领域的 api,其与 LLM 的密切耦合会对该方向上目前的创新有降维打击。
c. 合作机制设计:将 agent 应用到企业中去是一个复杂的问题,需要考虑许多因素:如与企业/用户数据的共享、安全、权限管理机制等;还有各
agent 之间的合作分工、层级方式,就像我们前面提到过的
Agent Framework 与工厂制、公司制存在着一定的相似度。理想情况下,
Agent Framework 应该提供一种方式,使得各个 Agent 能轻松地协作,同时保证数据的安全和隐私。
而 Vertical Agent 则是深入某个垂直领域,理解该领域专家的工作流,快速形成 PMF 开始累积用户数据。未来的 Copilot 类产品一定是多个 agent 在这一领域上的合作所实现的,也可能诞生更新的产品形态。这一领域的核心竞争力是领域知识针对性和交互反馈:
a. 领域知识:Agent 需要理解并掌握领域知识,以便于处理特定领域的问题。这可能包括专门的训练数据、领域专家的输入等。
b. 工作流理解:每个垂直领域都有自己的工作流,Agent 应用开发者需要选择具体场景,理解真实用户的工作流程,并探索如何与 AI 协同。例如,在法律领域,Agent 应用开发需要理解法律的工作流程,比如 Harvey 专攻的诉讼索赔流程。
c. 数据反馈:收集反馈数据的机制是非常重要的,这一点在 Coding 领域尤有着显著的优势。这可以帮助
Agent 不断改进,更好地满足用户的需求。
d. 多 Agent 协作:在某些情况下,可能需要多个 Agent 合作来解决问题。例如,一个
Agent 可能负责收集数据,另一个 Agent 负责分析数据,再有一个 Agent 负责做出决策。这就需要一个强大的协作机制来支持这些 Agents 的合作。同时,也要避免Copilot形成过度依赖,保持用户的主体地位来进行管理和 review 也同样重要。
以下就基于 Agent Framework 和 Vertical Agent 这两个重要方向,展开讲讲 AI agent 领域景观。
02.
AI agent landscape
1. Agent Framework
1.1
Agent Platform
前面提到过 AI Agent 未来的发展,会给各行各业的专家定制自己 AI 合作伙伴的能力。而 Agent 平台就是各种能力 agent 的聚合平台:不同agent专供不同细分领域或细分功能,例如“文章总结 agent”,“投资顾问 agent”。
这样的平台同时具有 PGC 和 UGC 特点,官方会定义一些默认的 Agent 设定,用户可以在相对低代码(prompt
为主)的环境下自定义一些agent,并提供第三方API接口来实现多 agent 之间的协同和合作。此类产品的主要评价标准是:平台 agent 的丰富度、自主开发易上手程度。其中 Fixie AI 是这一领域最具有代表性的公司。
Case
Study:Fixie AI
Fixie.AI是一家于2022年在西雅图成立的初创公司,他们将自己定位为“大语言模型的自动化平台”,用于构建、托管和扩展AI Agent。创始人 Zach Koch 是Shopify 前产品总监,也曾担任 Google Chrome 和 Android 团队的产品主管;另外两位创始人则来自 Xnor.ai(边缘端 AI 解决方案公司,被 Apple 收购)、OctoML 等团队。在 23 年初,他们得到了 Redpoint 领投的 1200 万美元,成为了 Agent 平台中的引领者。
其平台中有大量官方和用户创建的 agent。创建的成本比较低,只需要LLM+一些代码(让LLM链接到外部数据如数据库或API)再通过 Fixie 提供的工具即可让用户轻松的构建自己的Agent并且将其托管到平台中。
以一个客服 agent 为例,实际使用时当 Fixie
AI 收到用户提的 support ticket:T恤的码数出现错误时,LLM 会对加工其退换货请求,然后将其拆解为以下几个任务:
1. Call
订单历史 agent :获取订单详细信息中的货品号
2. Call
库存 agent:了解当前该 SKU 的实际存货
3.Call
标签 agent:为该顾客的地址发一张退货表亲
4. Call
邮件回复 agent:向该顾客生成一封客服邮件,沟通以上步骤获得的信息
这样的Agent 系统背后大致是以下图的架构实现的。当一个任务启动之后,首先会由 Fixie 官方 agent 使用 Anthropic Claude 2 模型理解用户需求,拆解成需要执行的任务。然后再将这个交给 Router agent(AI 分工总管),这个 agent 的职责是负责从 agent 库中找到最合适的 agent,进而去执行任务。
Fixie 团队在搭建平台的同时,还发现 Gen AI 应用的前端开发需要更好的框架,于是基于 JSX 和 React 开发了 AI.JSX 。在前端框架中了一种能够直观、灵活地编排多个 LLM 调用的机制。在这个框架下,用户可以依靠 LLM 从一组标准 React 组件动态构建
Generative UI。尽管这与 Agent 不直接相关,但 Generative UI 的确是未来 AI 应用最重要的部件之一。
其他典型案例:Spell, MindOS, Dify, Character.AI, Myshell
值得一提的是类似 Character AI 的产品现阶段并不是 Agent 平台,但有 agent 平台的潜力。因为当其平台上有大量
Chatbot 时,平台可以根据用户的需求为其选择合适的角色来进行一段对话/完成一个任务,实现娱乐场景 function
call 不同 IP 下的 agent。
1.2
Agent Workflow
前面提过 Autonomous agent 并不可靠,因为其可控性很差。而提高可控性最好的方式就是去帮 AI 设计 workflow,把规划职责部分转移给用户。
这类 workflow 平台和前面的 UGC 平台最大的差异是切入点不同,更专注企业端客户的工作流程。把业务流程交给企业中的业务实操者,而非 LLM来规划,因此会更容易在企业端落地。
Case
Study: Voiceflow
这是一家在语音领域有过一段时间积累的老公司,最早致力于为亚马逊智能音箱 Alexa 构建构建交互式语音娱乐平台,后来他们开始专注于客服 Chatbot 软件。与传统其他客服软件不同的是,他们希望为客服提供尽可能多的可能性,而 LLM 的出现为他们的愿景带来机会。
他们把产品改造成了适合 LLM agent 的设计平台,可以在其中设计
LLM 的工作流。
其中有几个比较有特色的功能:
• 意图识别与管理
对于 AI 对话类产品,用户的话题常常会“跑偏”。Voiceflow 允许设计 Chatbot 的用户设置意图(Intent)变量并对意图进行实时检查,当用户偏离正确路径时,会引导用户回到正轨上。
• 从用户回答中提取结构化信息
在一些重要的回答轮次中,用户可以指定 AI 从用户的回答中提取某些关键信息,并将该信息提取为状态变量,在之后的对话中再次用到。
这类产品的开发门槛不高,但是对企业端落地非常实用,需要兼具对工作流需求和对 LLM 的理解
类似产品:Steamship, Ironclad Rivet
2. Vertical Agent
2.1
Coding Agent
Coding 是 agent 方向中我最看好能快速落地的,且有可能成为未来所有 Agent 的底层翻译员。开发领域解决的问题形式化、输入的数据结构化,非常适合 AI 学习和收集数据反馈:生成的代码是否达到开发者的预期,用户如何与开发出的应用进行交互等等。
而且开发领域也有着清晰的工作流,成本更低的垂直生成模型,而 Devops 等 Infra 工具则相对零散。因此开发领域使用 agent 思路的产品是最多的,我们根据各产品的形态将其分为 6 类:
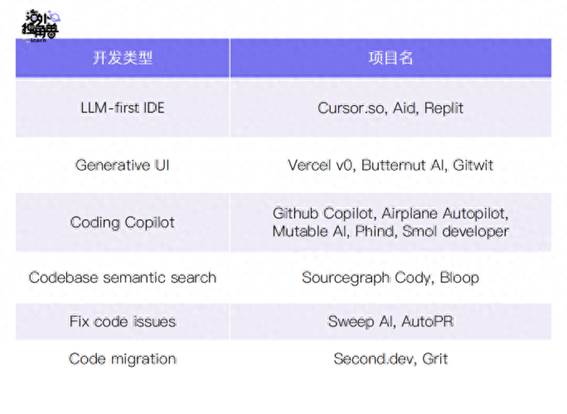
这 6 个方向中中,我最看好 LLM-first IDE
和 Generative UI 这两个领域能诞生独角兽。因为这两个领域本身的数据飞轮是最为闭环,且带来的 impact 也是最大的:
方向1: LLM-first IDE
可以根据 LLM 需要学习的用户行为设计埋点,更好地收集开发中的行为反馈。并且 IDE 可以将开发中的版本控制、测试等流程完整地涉及,覆盖一个项目开发上限的完整生命周期。随着 LLM 对开发工作流的逐渐渗透,云 IDE 的开发协作平台可能成为新的开发者入口。
Case
Study: Cursor
Cursor 是一款由 Anysphere 团队开发的 IDE,他们得到 OpenAI 生态基金的投资,在 GPT-4 发布的第一时间就将其加入了自己的产品中。
他们将自己的产品称为 AI-first IDE,其产品 UI 与 VS Code 接近,加入了很多 LLM 原生的 feature,比 Github
Copilot 能做得更深入。可以认为是 AI agent 化的 VS Code + Github Copilot:
Cursor 可以直接输入链接,LLM 会阅读开发者文档进行总结,并在之后的开发过程中随时检索使用。这一点符合 agent 能进行外部行为和世界知识记忆的特点:
在 debug 检查错误的阶段,Cursor 也用了 agent feature 去进行自动化反思。当出现问题时点击下图中蓝色的 auto debug,agent 将开始产生一个基于项目所有代码的 debug 思维链,并重新生成正确的代码直到解决了问题。相比起来,Github Copilot 如果出现类似问题,只能在
Chat UI 中告诉 Copilot 出现问题时的报错方式,通过对话的形式来试图解决。Cursor 在 IDE 中的 debug 和调试是更为深入和闭环的。
cursor
自动
debug
cursor
手动
debug
github
copilot chat debug
方向2:Generative UI
Generative
UI 是 Chat UI 和 GUI 结合最重要的组件之一。当灵活的 UI 生成实现之后,AI 应用中随用随抛的软件创造就距离不远了:用户可以根据自己的长尾需求生成临时的 UI 完成任务。
我们在之前的研究中提到过,目前在真正存在数据飞轮的 AI 产品只有两个:Github Copilot 和 Midjourney。而 Generative UI
的用户反馈既可以是 Copilot 式的代码优化,也可以是 MJ 的四选一,想象空间很大。
Case
Study: Vercel v0
v0 是由 Vercel 团队打造的 AI 前端代码生成工具。其使用过程非常直接:用户使用自然语言描述需求,v0 根据需求描述来生成组件代码。然后用户继续对不满意的地方提出修改意见,将其迭代为 v1、v2... 直到满足用户的要求。
由于前端的特殊属性,其 UI 和交互方式更加直观:当我们想将一个生成网页的标题改为渐变色时,只需要选择标题部分并提出“增加一个渐变色”,产品便会只对这一部分代码进行修改。
这款产品目前还在测试阶段,但展现出的能力很优秀,代码生成基本正确且能很好的理解用户需求。可以参考一个用户目前使用 v0 生成机票订购页面的实例:
https://v0.dev/r/Sn4TuN1FuGP
第一步用户用比较长的 prompt 描述了页面中核心文本框和内容的形式。
第二步在网页下方加入导航页引向别的页面:
第三步,在网页中加入几个建议的旅游方向:
此外其他几类产品也有着各自比较值得关注的点:
• Coding
Copilot 类的助手产品是 Github Copilot 最擅长的领域,其产品同时包括了代码编辑、代码生成,和 Chat 形式的问答式编程,对于该方向可以做的产品基本都在
Github 的射程之内,其他创业公司的机会可能相对小一些。他们目前做得不够好的,就是企业用户的离线部署和隐私安全。
• 余下的三个方向,都是开发领域相对垂直的方向,之前有一些 devops 工具,但是有了 LLM 确实能够更好的解决对应的问题:
• Codebase
semantic search 问题中 LLM 解决的是之前的 indexing 和 keyword search
所不能覆盖的 case,并且 LLM 有能力在宏观上对代码的结构进行一定的理解。
• Fix code
issues 产品中 LLM 解决的是之前按规则修复 issue 不够 scalable 的问题。有了 LLM 的理解和生成能力,确实能够高效地解决很多之前有难度的长尾问题。
• Code
migration 中 LLM 发挥的作用与 Fix code issues 的作用接近。区别在于 fix
code issues 是一个特别高频、琐碎的需求,而 code
migration 是一个相对低频但 heavylifting 的工作,前者的实现可能性和容错率更高一些。
2.2 个人助理
对于很多硅谷的优秀投资人/创始人而言,executive
assistant 的同事非常重要,优秀的行政同事能够做到最合理的日程管理和对外沟通。但这件事情本身并不是 ChatGPT 这类产品能够实现的,因为助理任务往往需要很多隐式上下文(latent context)。优秀的助理安排线上 zoom meeting 和线下饭局时需要考虑的因素很多:见面对方的重要性、当天的其他日程、交通天气、地理位置和偏好等等。这些任务的实现很需要 agent 的记忆和工具模块来获得一些背后隐藏的信息。
Case
Study: Lindy.ai
Lindy.ai 是一款基于办公场景的智能个人AI助手产品,帮助用户智能化处理日常办公任务。Lindy
由来自 Uber 的产品 head Flow Crivellow成立,该团队在 LLM 浪潮来临前的创业方向是线上协同办公。也正是基于他们对办公场景比较深的理解,他们对自己产品的定位是 personal AI executive assistant。
其主要产品功能包括:
• 智能日程规划及预定
• 邮件起草及发送
• 每日日程总结
• 会议纪要撰写及总结
主要应用场景:
• 销售:根据会议更新CRM
• 招聘:自动搜索候选人并发送邮件
• 日程规划:自动发送日程邮件和更新日历
• 市场营销:起草营销方案
类似产品:MultiOn
2.3 写作 Agent
从 GPT-3 开始,个人写作助手类产品就是最快能够为用户提供价值、产生收入的。撰写工作邮件、销售文案等场景加入了 LLM 的文本理解、生成能力都有着比较明显的效果优化,因此我们会看到去年的 Jasper、今年的 Writer.ai 都在用户反馈和商业化收入上做到了不错的效果。
但这一领域常被诟病的问题是没有 moat,其产品核心的创作能力来自 LLM 的技术壁垒。而 Agent 的出现给 writing
agent 了一个新的技术路径: 让我们的写作助理可以自由的与网络交互,
通过浏览能力和调用工具能力的增强来提升写作体验,并且能将产品的功能延伸至其他领域,比如在线预定行程、在线购买物品等同样需要 agent action 的用户行为。
Case
Study: Hyperwriter
Hyperwriter 是由来自纽约的 AI 公司 Otherside AI 开发的产品,很大部分 AI for writing 公司一样,他们的产品以辅助写作的
Chrome 插件为最早的形态。
随着 Agent 类产品的发布,他们很快在自己的插件中开始结合 agent 的能力。团队在 8 月发布了第一个 agent 方向微调的大模型 Agent-1,可以做到在 Google Chrome 中通过阅读前端代码,理解网页布局,并找到正确的地方填写参数。在他们对外的 demo 中,该 agent 在 UI 设计非常难用的 GCP 界面能够成功在正确的文本框填写内容、完成操作。
我们在预约去美国机票的时候也使用了这个 agent 插件,总体感觉优点和缺点比较鲜明。优点是:
• 功能比较强大,能理解指令自动访问网页,找到对应的参数位置然后填写
• 能清晰实时地看到他的每一步规划和操作
但其缺点也对于现在的 agent 应用有普世性:
• 每一步操作中,模型思考碎碎念的步骤很多,效率较低
• 因为大模型的 latency 不够低,有明显的卡顿感
• 容易进入死循环,缺少自己纠错和反问的能力:写指令时没有写单程还是来回,agent 的操作就卡住了需要人工介入
总的来说,写作和浏览场景都是适合 agent 发挥的领域。但确实对于这个方向的创业公司来说,需要意识到这是 OpenAI、Anthropic 等大模型公司一定也会涉足探索的方向,需要尽快积累用户数据获得独特的优势。
2.4 数据分析 Agent
数据分析的大部分工作是可以离线完成的,例如数据可视化、探索性实验等。因此相比编程开发而言,数据分析对 latency、稳定性的要求更低,对其分析能力、数据安全性的要求更高。同时 LLM 的确对结构化数据有了更好的理解和加工能力,让很多原本重复、机械的 BI 任务能够自动完成。
因此 OpenAI code interpreter 上线之后,用户主要的 use case 都集中在做数据分析上。Code
Interpreter 在这一领域的局限也相当明显:无法处理超过
1000 行的数据表,没有办法规模化地处理严肃任务。而且这个方向也不是 OpenAI 的主要重心,这就为创业公司留下了机会。
目前在 Analytics + LLM 方向的公司很多,其中大部分都有使用 Agent 思路。最为代表性的是三家基于
Notebook 形式的产品:Julius AI 是一个 AI-native 新产品中的代表,而 Hex 和 Deepnote 这两家相对成熟一些的公司也在自己的 Notebook 产品中集成了 Analytics
Agent。
Case
Study: Julius AI
Julius AI
founding team 的核心成员 Matt Brockman 来自上文 Hyperwrite(其公司为 Otherside
AI)的团队。独立创业后他们的产品得到了 YC 和 AI Grant 的支持。
他们的产品是基于外部 LLM api 的能力进一步优化数据能力开发的
agent 应用。实际使用中,开展一个分析前需要设置这次分析的主题和对话风格。这一步使用了其 Agent 的职责扮演能力:
设置完成后,需要读取此次分析所用的数据。添加时可以像使用 excel 一样看到数据预览,并且对其中内容直接进行变换。例如下图中使用自然语言进行的数据清洗和标注:
在执行数据分析时,Julius 也能够执行多步的数据加工处理:数据聚合、可视化,再到最后的建模分析和模型评估。每一步 agent 会尽量把自己的操作过程用文字表达出来,同时也可以查看其执行时的代码以 review 准确性:
Julius 目前的使用体验确实明显优于 Code Interpreter,能更好更快地处理数据、且能比较准确地理解用户意图。同时也能感觉到目前的 analytics agent 还在一个处理 toy case 的阶段,并不能用于处理复杂的任务。
在现实的数据分析场景中,往往需要对数据和业务场景进行更多维度的理解和探索,规划自己的分析思路。但目前 Julius、Hex、Deepnote 这些产品都不能在接触到数据集,之后主动根据需求去规划和拆解一些分析任务。这个需要更多的业界合作和数据积累才能够有效地实现,成为数据科学家的工作伙伴和分身。
03.
AI Agent 的
未来展望
1.
AI Agent 需要更模块化的框架,11 月 OpenAI devday 有机会定义标准
现在在 AI 应用领域,绕不开的话题是 OpenAI 会做什么、不会做什么。对于 AI Agent 领域也是如此,Andrej
Karpathy 多次表示了对 Agent 前景的看好,OpenAI 很可能会在 11 月的 devday 发布定义 AI Agent 的 api 和开发框架。我们对 OpenAI 的发布有以下预测:
• OpenAI
发的 Agent 框架可能与他们在 16 年发布的 OpenAI Gym 接近。当时 Greg 等人写的框架为之后的 RL 研究使用的环境定义了统一的标准:obs, reward, done, info = env.step(action) 这样的形式很出色地将 RL 中的学术概念模块化,这次他们也很可能会对 AI
Agent 做类似的框架定义,例如 Memory,
Action, Agent class 等。
• Agent
api/framework 会和 fine-tune api
两者结合会成为比较完备的 to B 服务体系。企业可以通过定义 agent 更好地使用 LLM 并收集领域数据和行为序列,为 fine-tune 提供更完整的数据反馈;同时
fine-tune 又可以支持在某个领域有更专业、可靠的 agent,两者一起能使 LLM 在企业端更容易落地。这对 Anthropic 这样的竞争者在后续的 api 发布会带来挑战。
2.
AI agent 概念在强化学习领域早已出现,LLM-based
agent 在探索试错的能力上要向
RL-based agent 学习
上文中 OpenAI Gym 的图片中也出现了 Agent 这个词,其实 AI 领域 agent 的概念并非第一次出现,强化学习中的智能体也是非常符合 AI agent 的定义,但是技术路径完全不同。RL-based
agent 是通过大量与环境的交互试错,评估不同行动的结果,根据奖励或惩罚来更新其策略,最终学会如何执行任务。
但强化学习一直距离大规模落地存在着距离,因为其职能在一小部分场景之下使用,泛化能力较弱。这一小部分场景的特点是:其环境下的策略有限、能用数学完美地模拟复现。例如围棋、Flappy Bird 这类非开放、有明确输赢目标的游戏,RL 能够做到比最优秀的人类更出色。但是当 agent
被放在一个随时可能变化的场景中,如通用机器人、自动驾驶想达到的目标,一旦当环境出现变化时
RL-based agent 的泛化能力就会遇到瓶颈。
泛化能力正是 LLM 的强项,也是这次 LLM-based agent
大火的重要原因。且大模型压缩了大量世界的语义信息,让模型有能力在接触环境时真正理解环境中每一个物品是什么、发挥什么作用,进而根据用户需求并进行规划和执行。这解决了很多之前 RL 无法定义的长尾问题。
但技术上的 tradeoff 也带来了很多落地困难的问题,其中与强化学习对比最欠缺的是:当前的 LLM agent 还没有高效从错误中学习的能力。由于 LLM 本身训练成本高,不可能根据每个任务和犯错经验去调整参数,目前还没有特别好的从错误中吸取经验的 practice。trial-and-error
模式的可行性是对 AI agent 的挑战。目前强化学习还只在 LLM 的 RLHF 阶段出现,在 agent 领域引入 RL 的思想可能能帮助 AI Agent 有进一步的突破。
3.
AI agent 应用的真正成熟还需要等待 LLM
的优化:复杂推理能力不够强、延迟过高
让我们回到 agent 这个词的本意:代理人,也就是具备主动决策能力、代为行使权力的智能体。这两个修饰词之间是有因果关系的,这对 AI agent 的实际落地有启发:只有证明了
AI 的决策可靠,用户才愿意交给 Agent 代为行使权力。
目前 AI Agent 实际落地的问题中有两个瓶颈是来自于 LLM 作为推理引擎不够强大:
• 现有的LLM虽然在某些领域的任务上表现不错,但对于需要多步复杂推理的任务,表现还是很弱。这主要是因为LLM的训练目标是next token
prediction,而不是进行复杂的推理。所以在需要链状推理的任务上,LLM的表现仍有很大提升空间。这个提升空间来自于模型架构和数据上的优化。可以用更复杂的训练任务使LLM学习复杂推理,如问答、阅读理解、分步规划等。
• 同时,LLM 响应输入和执行任务的速度还很慢。目前尚在技术早期,大家对 LLM 的延迟宽容度还比较高。但未来对于许多应用来说,低延迟是至关重要的,其速度直接影响了知识工作者的工作效率。例如最极端的,在自动驾驶汽车或高频交易系统中,延迟的减小可能会直接影响到系统的性能和安全性。
因此需要通过知识蒸馏、模型压缩等方法缩小模型大小,降低计算量,并且等待大模型推理硬件和算法侧的持续优化。
其中,延迟优化是工程问题,需要业界的时间来渐进式优化;更难的瓶颈还在复杂推理能力上,这是个需要被解决的科学问题,将随着科研的进展和 agent 行为序列数据的累积逐渐明朗。
4.
Multi-agent 协作会产生比 Chatbot 大一个数量级的文本量,带来成本控制和激励机制的挑战
在 AI agent 框架中,其中的 AI 之间会有大量的文本/代码沟通与协作,因此 AI agent 产生的 token 数会有数量级的上升,需要模型侧进行持续的成本优化。AI 小镇框架开源之后,根据开发者的测试一个
agent 一天需要消耗 20 美金价格的 token 数,因为其需要记忆和行动的思考量非常大。这一价格是比很多人类工作者更高的,需要后续 agent 框架和 LLM 推理侧的双重优化。
与成本对应的是合作机制中的多 agent 场景下需要更明确的目标和激励机制,类比强化学习中的 reward function。这一个方向是目前还没有好的实践,可能是 web 3 token 机制适合引入的方向。数字货币与代码,可能是未来 Agent 生产和协作过程中相当重要的生产要素。由于篇幅限制,这一点就暂不详细展开了。
总的来说,我们对 AI Agent 需要保持耐心。一方面,OpenAI
等大模型公司会在 Agent 标准定义和模型推理能力上持续进化:11 月 OpenAI Devday 可能会踏出定义标准的第一步,连续的复杂推理问题对于当前 next token prediction 的模型存在根本性的瓶颈,需要用更复杂、结构化的数据和目标函数来进一步学习。另一方面,Agent 的应用落地还需要 Generative UI 带来的人机交互方式的革新,就像曾经施乐实验室对个人 PC GUI 的定义。这也需要业界持续探索和创新才能逼近正确答案。
出自:
https://www.toutiao.com/article/7289417876849984058/?app=news_article×tamp=1697419785&use_new_style=1&req_id=20231016092945524A4A550AC70D992376&group_id=7289417876849984058&share_token=66ED84ED-F7A1-4165-9858-E84098C759AF&tt_from=weixin&utm_source=weixin&utm_medium=toutiao_ios&utm_campaign=client_share&wxshare_count=1&source=m_redirect