前期我们使用大量的篇幅介绍了手写数字识别与手写文字识别,当然那里主要使用的是CNN卷积神经网络,利用CNN卷积神经网络来训练文字识别的模型。
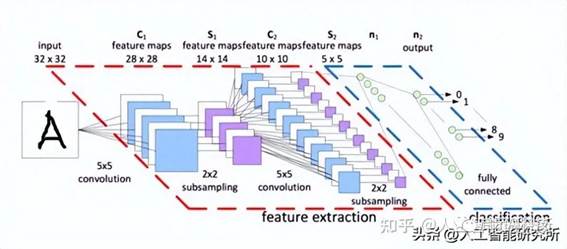
这里一旦提到OCR相关的技术,肯定第一个想到的便是CNN卷积神经网络,毕竟CNN卷积神经网络在计算机视觉任务上起到了至关重要的作用。有关CNN卷积神经网络的相关知识与文章,可以参考往期的文章内容。
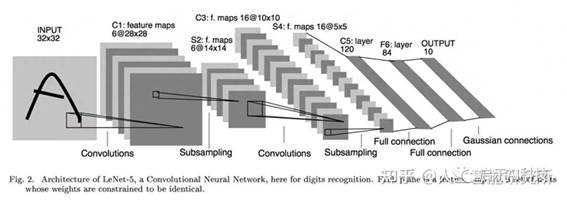
但是随着transformer模型attention注意力机制进入计算机视觉任务,我们同样可以使用transformer来进行计算机视觉方面的任务,比如对象检测,对象分类,对象分割等,这里毕竟著名的模型VIT,Swin便是成功的把transformer的注意力机制应用到了计算机视觉任务,那么基于transformer模型的OCR识别任务,便是理所当然的了。
TrOCR是transformer OCR的简写,是microsoft发布的一个OCR识别模型,光看这个模型的名字就知道此模型基于transformer模型,其模型架构如下,完全采用了标准的transformer模型。
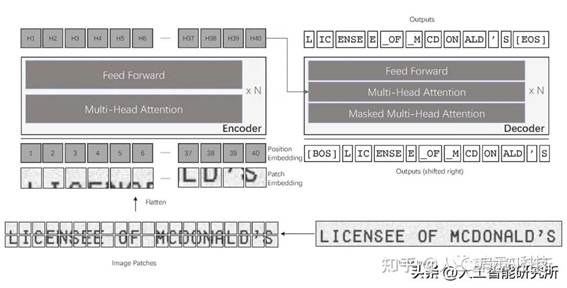
编码器有预训练的Vision transformer组成,这里主要采用了DeIT作为Vision transformer模型。
解码器有预训练的language transformer模型组成,这里主要采用了RoBERTa 与 UniLM 模型。
首先,图像被分解成小块,类似VIT模型的patch
embedding操作,然后再添加位置编码。
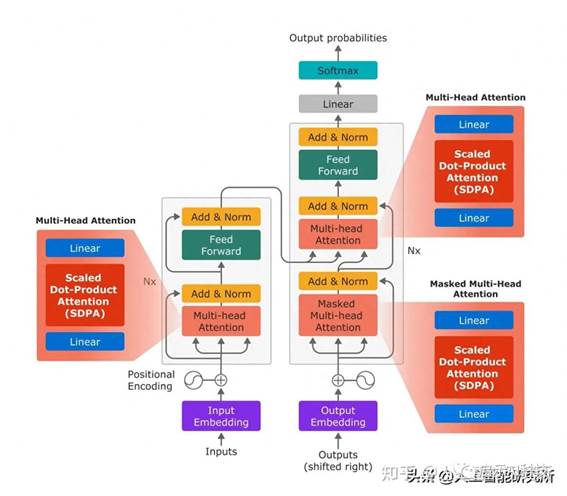
第二步,我们将图像输入到 TrOCR 模型,该模型经过图像编码器,编码器主要包括多头注意力机制与feed forward 前馈神经网络
第三步便是我们的解码器部分,解码器的输入是标准的文本,其文本需要跟编码器的数据进行注意力机制的计算。
最后,我们对编码输出进行解码以获得图像中的文本。
需要注意的一件事是,在进入编码器之前,图像的大小已调整为 384×384 分辨率。 这是因为 DeIT 模型统一了输入图片的尺寸。
TrOCR 预训练模型
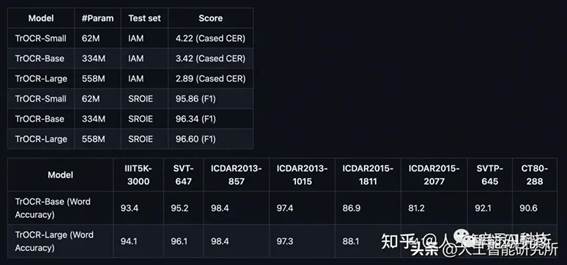
TrOCR 系列中的预训练模型是根据大规模综合生成的数据进行训练的。 该数据集包括数亿张打印文本行的图像。官方存储库释放了预训练阶段的三个模型。
TrOCR-Small
TrOCR-Base
TrOCR-Large
.
TrOCR 微调模型预训练阶段结束后,模型在 IAM 手写文本图像和 SROIE 打印收据数据集上进行了微调。IAM 手写数据集包含手写文本的图像。
微调该数据集使模型比其他模型更好地识别手写文本。同样,SROIE 数据集由数千个图像样本组成。 在此数据集上微调的模型在识别印刷文本方面表现非常好。像预训练阶段模型一样,IAM 手写模型和SROIE 打印数据集模型也分别包含三个维度的模型:
使用TrOCR 来进行图片文字识别,我们可以直接使用GitHub开源代码来实现
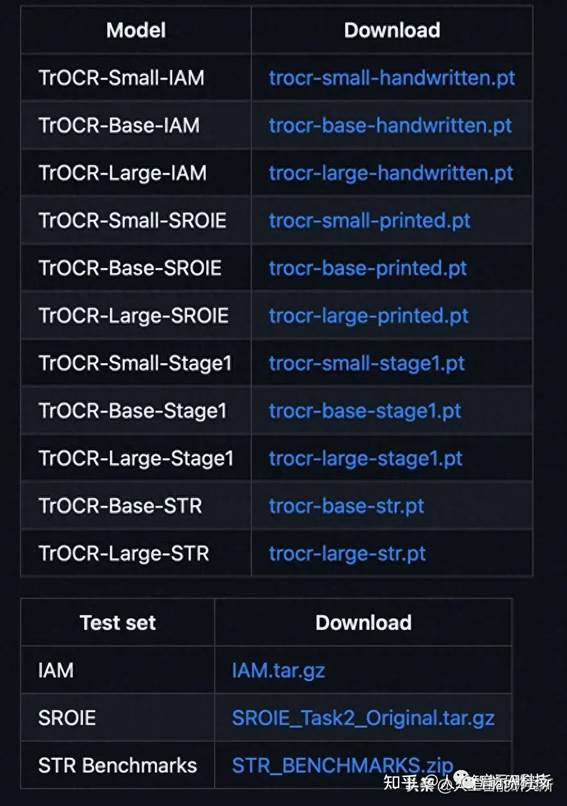


这里我们需要下载预训练模型,并传递一张需要的图片来进行识别即可。
当然既然是transformer模型,我们就可以使用hugging face的transformers库来实现上面的代码,且代码量就精简了很多。
这里我们首先需要安装transform库,并插入如下代码来进行TrOCR的文字识别。
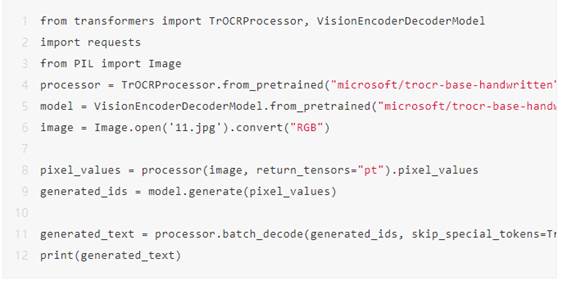
首先需要使用TrOCRProcessor来进行图片的预处理,然后使用VisionEncoderDecoderModel建立一个OCR图片识别模型,然后打开一张需要识别的图片,当然图片需要使用processor进行图片的预处理操作,最后使用model函数进行图片的预测,预测完成后,就可以识别完整的文本文件了。

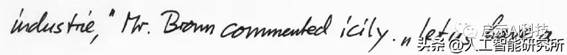
代码运行后,会自动下载相关模型,并输出最终的文本。
industry, " Mr. Brown commented icily. " Let us have a
这里我们可以看一下TrOCR的主要配置,可以看到整个数据库有50265个词表,且embedding维度为1024,每个encoder与decoder有12层的结构,且每个注意力层有16个头,虽然TrOCR完全复制了整个transformer模型,但是更改了一些参数。
出自:https://mp.weixin.qq.com/s/tYb07dpzfIulG36K4OrLWA

启示科技