伙伴们,平时都会用到文字识别吧?
最近,在Github上发现了一个厉害的开源OCR项目——Umi-OCR,真的很强大,而且还可以离线使用,现在已经有了14.6k+的星标。
简介
下面是项目在Github上的官方介绍。

项目是基于PaddleOCR开发的,支持截图识别、批量导入识别、个性化识别等功能。
整个项目都是用Python编写的,所以win7系统的朋友们可能用不了。推荐使用Win10 x64及以上版本。
体验
直接在releases中选择合适的版本,下载解压即可。
下面就是工具的界面。
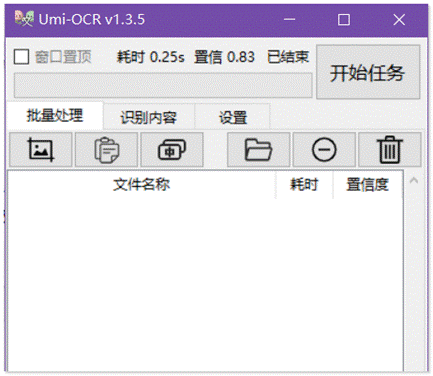
接下来给大家展示一下它的亮点功能:
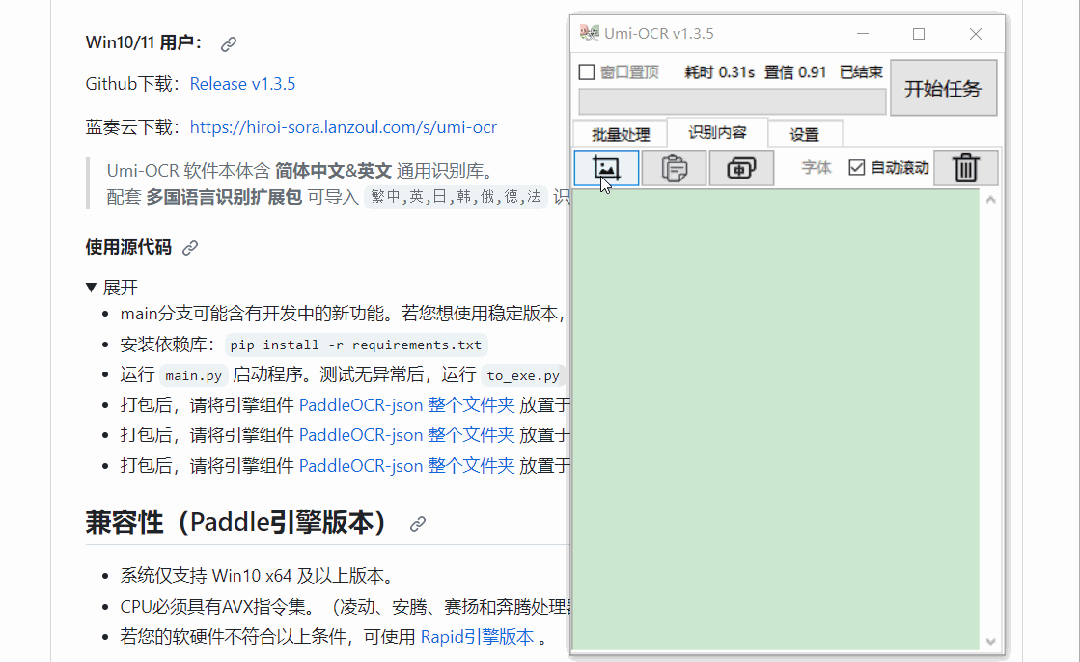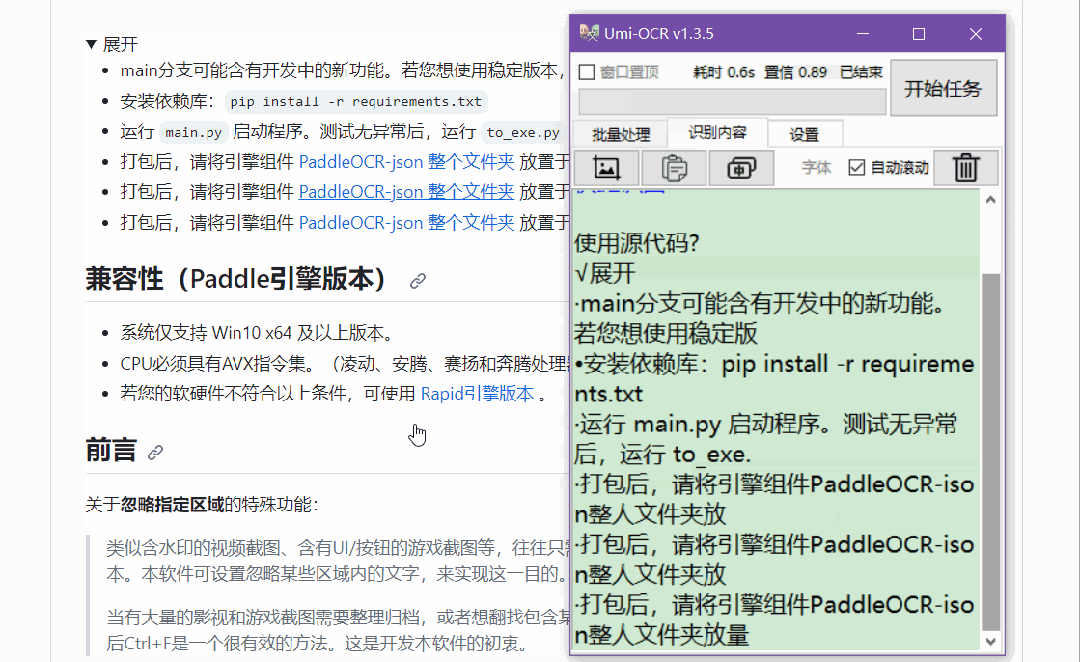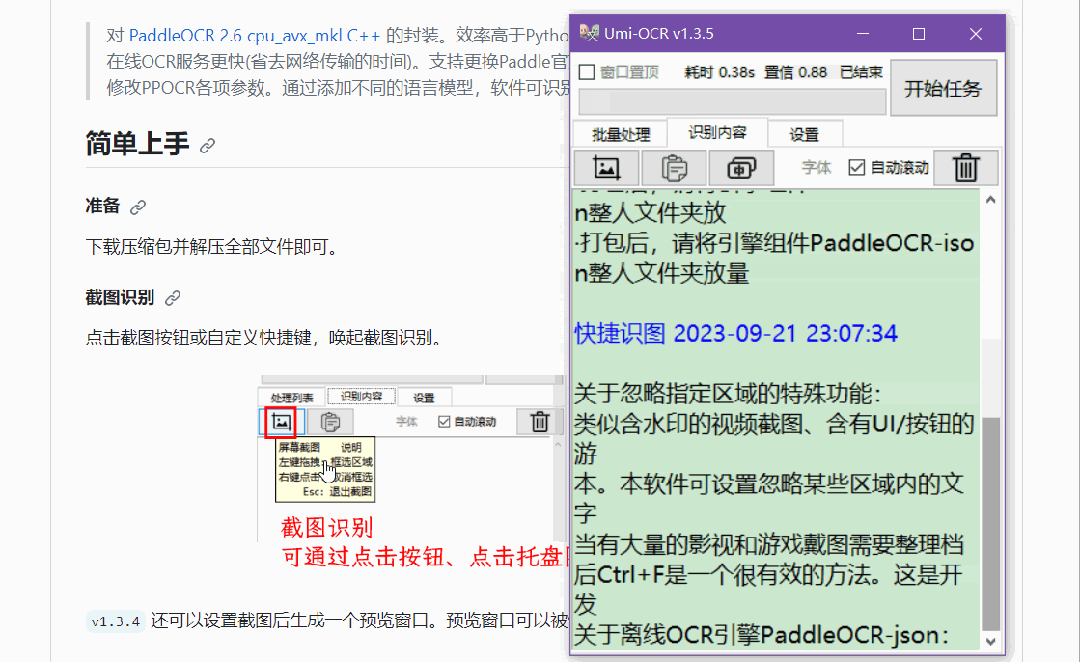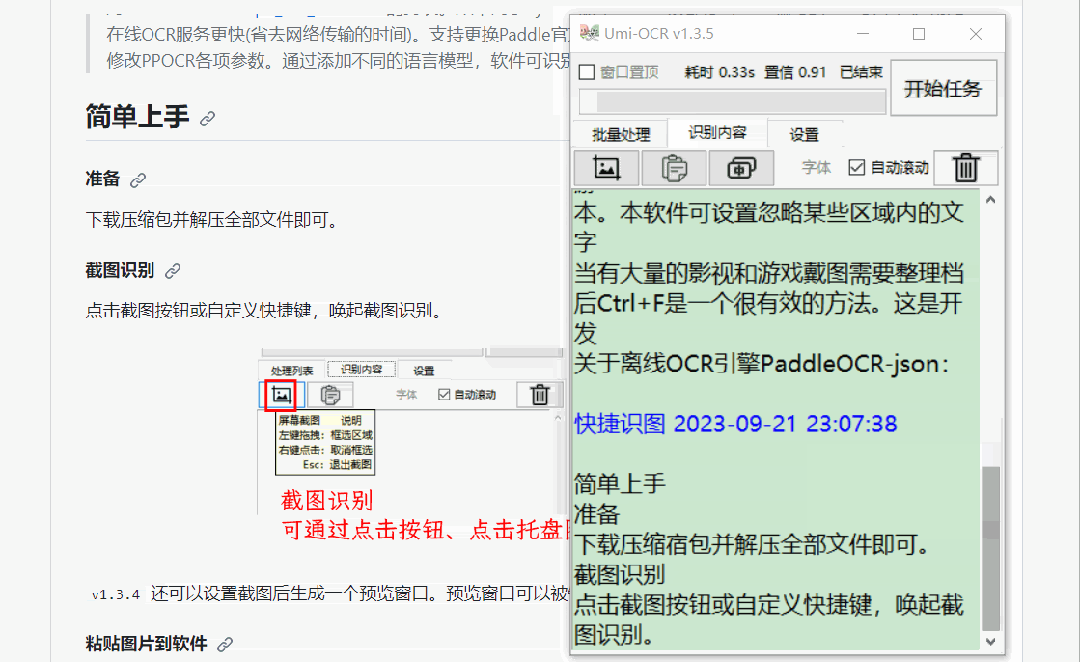
截图识别
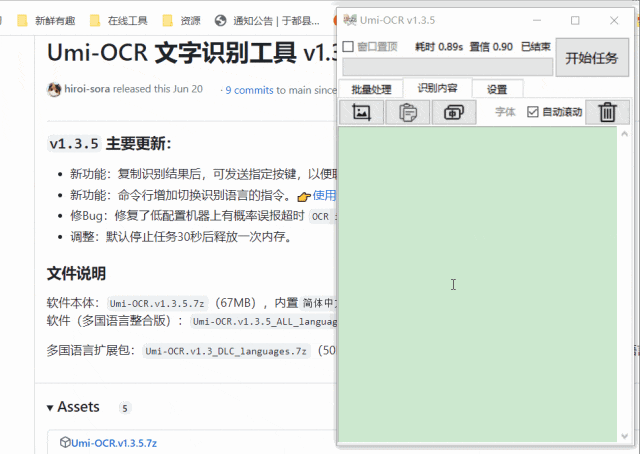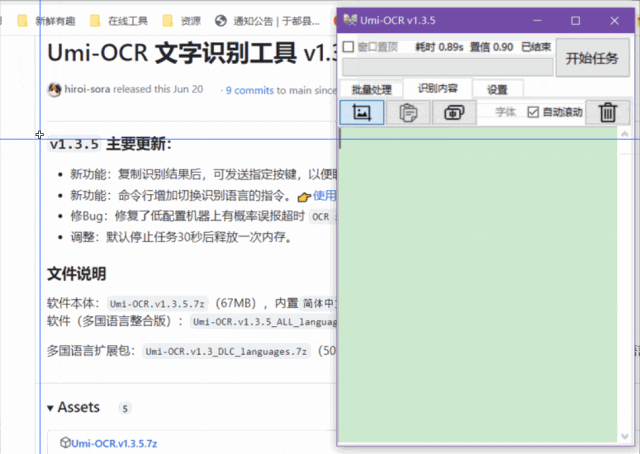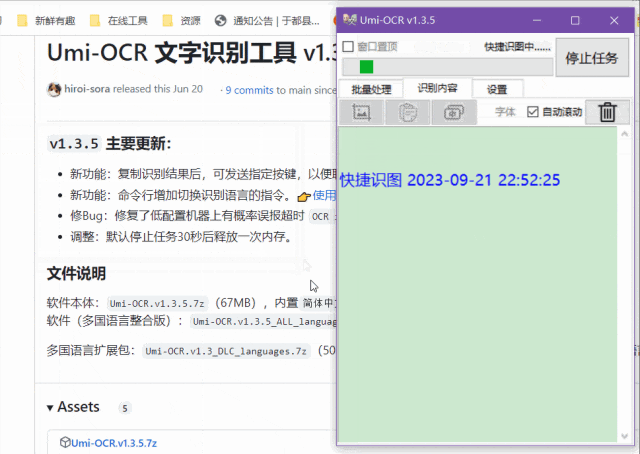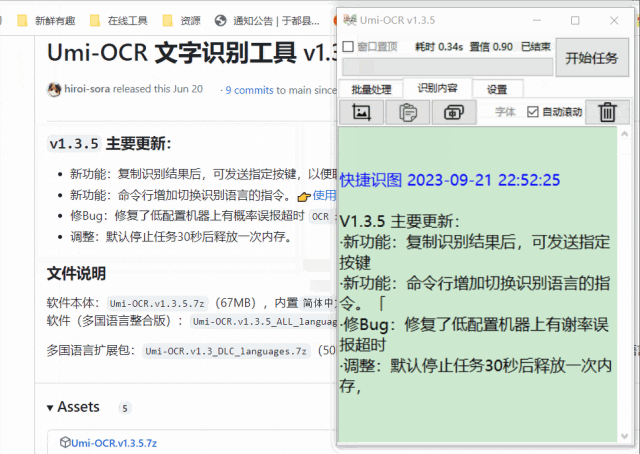
这个功能很适合在一些不能复制的网页上使用,速度很快,准确率也很高。
也就是说,你可以一次性截取所有的图片,然后再从记录板里复制所有识别出来的文字,不需要一张一张地截取和复制。
批量识别
如果有很多图片需要识别,这个功能非常好用。
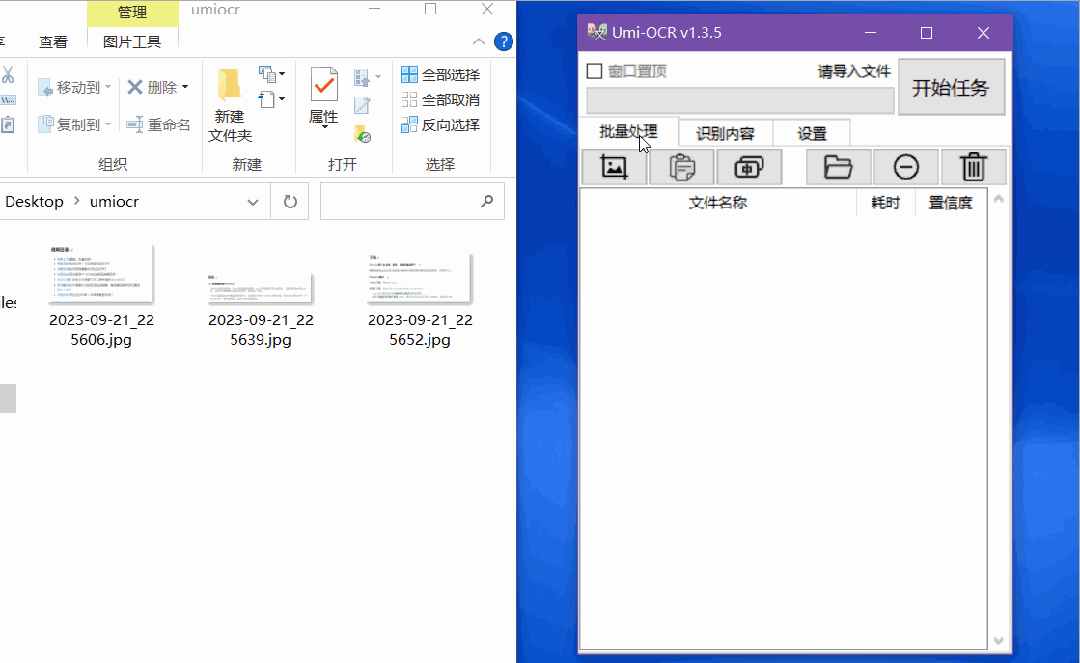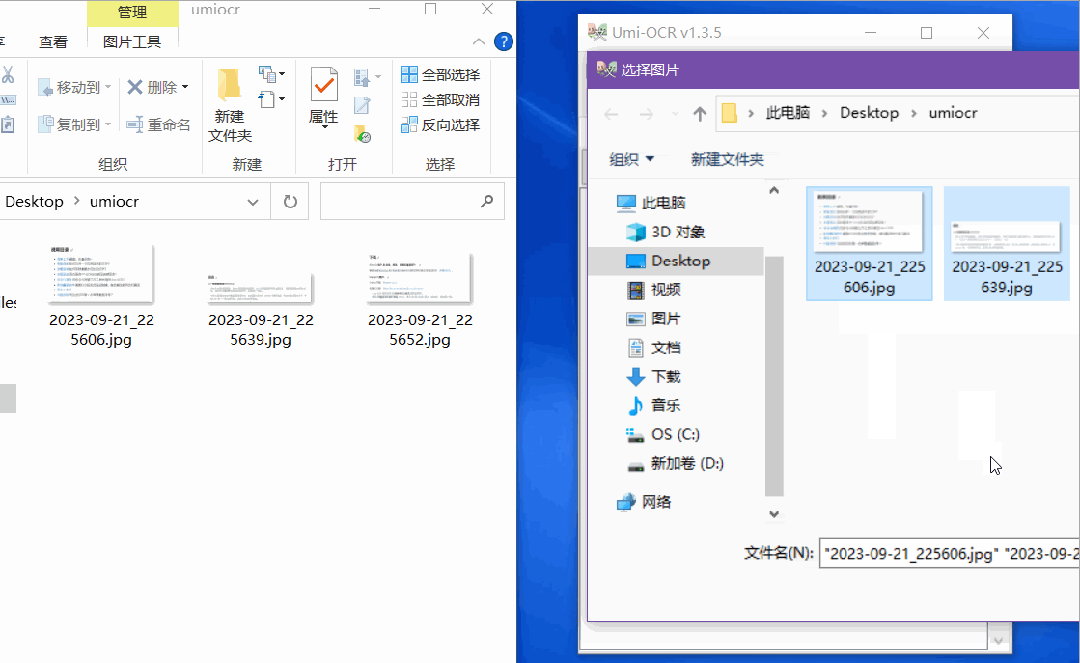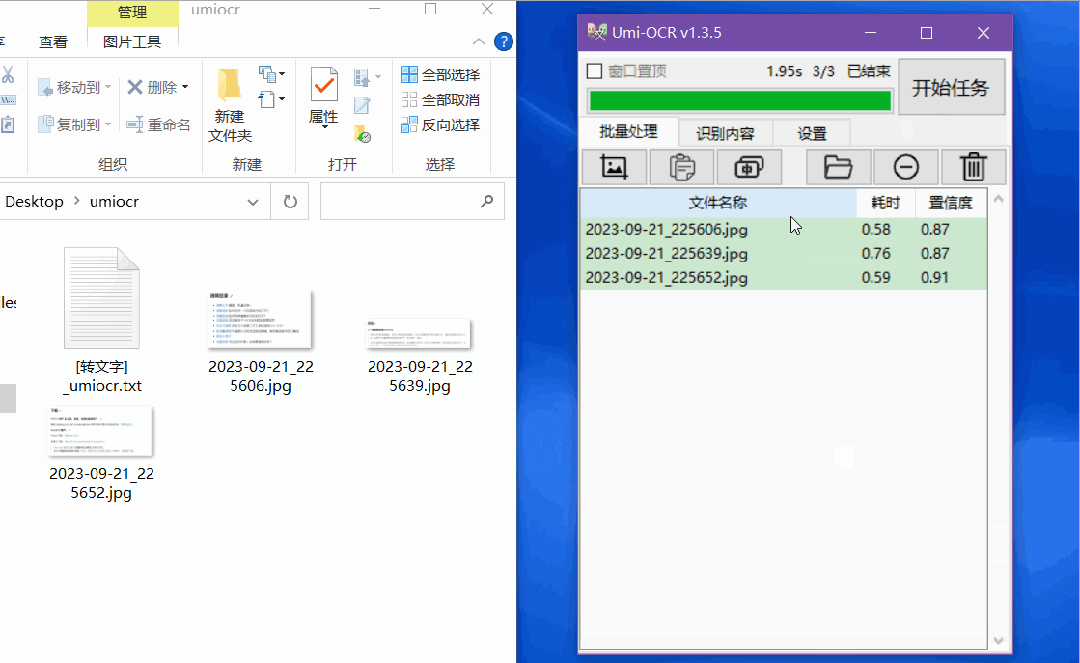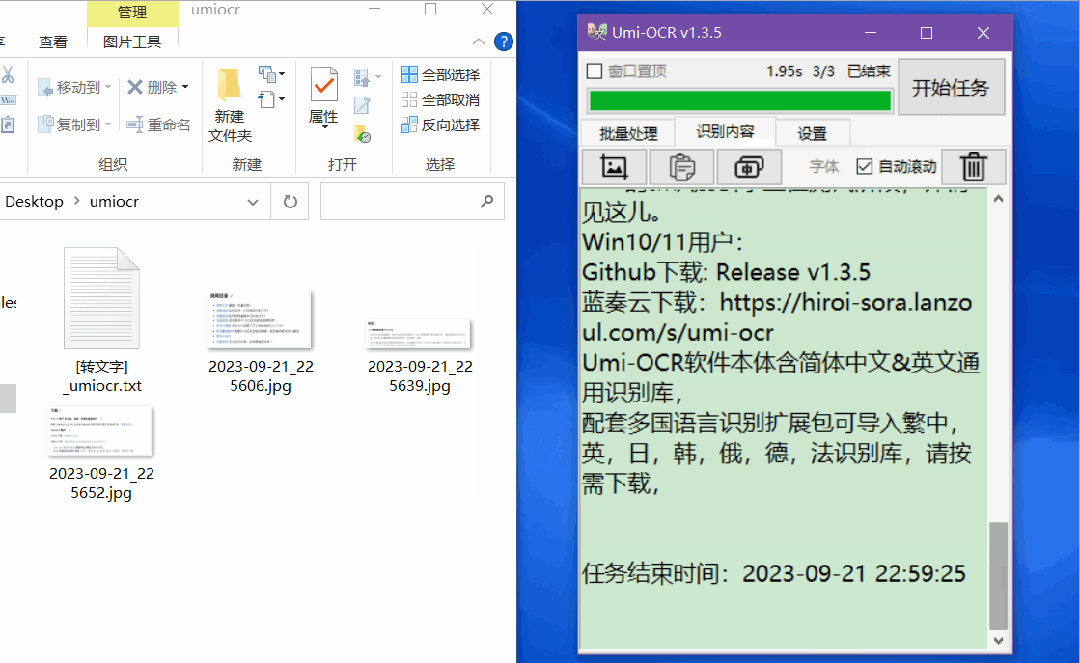
只需要将所有的图片导入,然后点击开始任务,就可以批量识别了。
完成之后,识别的内容会保存在一个txt文档中。
如果你不喜欢txt,需要md、jsonl 的格式,它一样可以满足你。

自定义识别内容
这个功能是Umi-OCR的一大亮点,可以指定识别的内容区域,或者屏蔽掉不需要识别的区域。
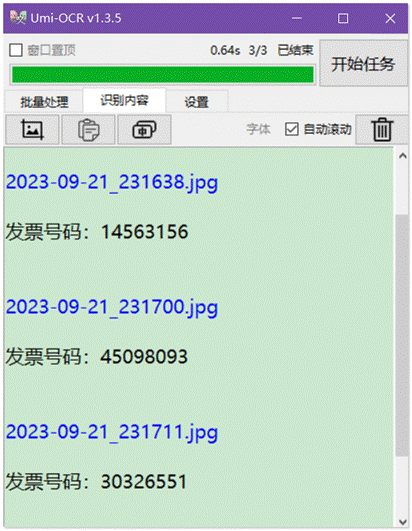
比如说,我有三张和下图类似的图片,我只希望提取出发票号码。

只需要在设置里点击打开忽略区域编辑器,将不需要的内容用红框框起来。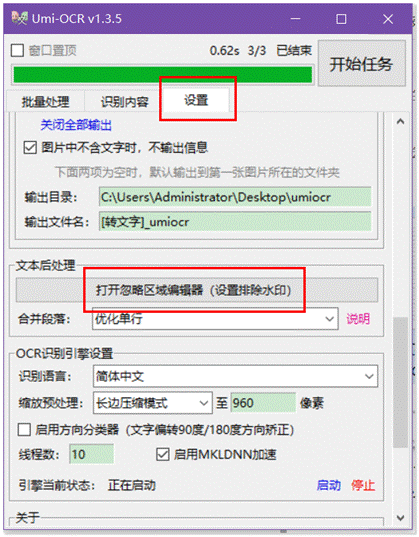
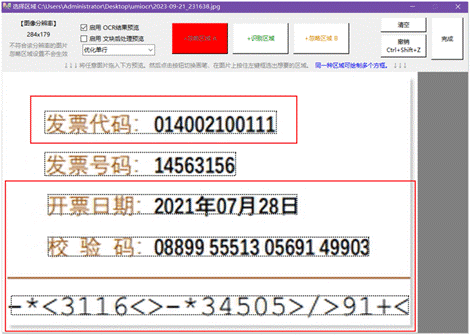
然后点击开始任务即可。
出自:https://mp.weixin.qq.com/s/GQCpkzTWg7xLJYPDAhWTYQ