ddddocr库介绍
ddddocr(Deep Double-Digital
Digits OCR)是一个基于深度学习的OCR(Optical
Character Recognition,光学字符识别)库,该库可以识别图片中的文字,并返回文字内容。ddddocr库在多个领域有着广泛的应用,包括自动化办公、图像处理、文字识别等。
ddddocr库的安装
pip install ddddocr -i https://pypi.tuna.tsinghua.edu.cn/simple/
利用dddocr库可以支持识别不同类型的验证码。
ddddocr库的使用
官方地址:https://pypi.org/project/ddddocr/1.2.0/
import ddddocr
ocr = ddddocr.DdddOcr(show_ad=False)
with open('test.png', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
print(res)
使用时需要调用DdddOcr()先创建一个文字识别对象,然后用with open()方法将验证码图片以二进制方式读取,接着调用classification()方法将图片的二进制字节类型进行文字识别,识别出来的文字会返回到变量之中。
网页中验证码的识别
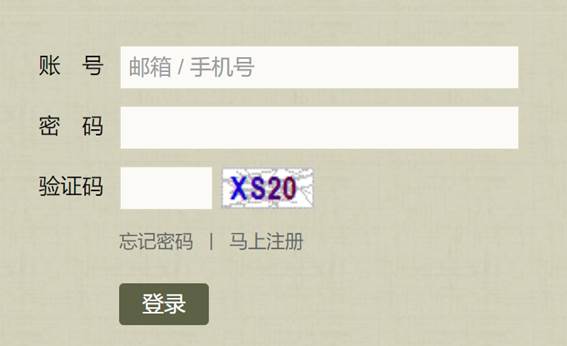
思路一:验证码截图,进行识别
定位到验证码图片的位置,采用screenshot_as_png进行截图,通过ddddocr库识别。
screenshot_as_png 方法是 Selenium
WebDriver 中用于获取页面截图的方法。它返回一个 PNG 格式的二进制图像数据,可以保存到文件或进行进一步处理。
import ddddocr
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 创建一个谷歌驱动器
driver = webdriver.Chrome()
# 打开页面
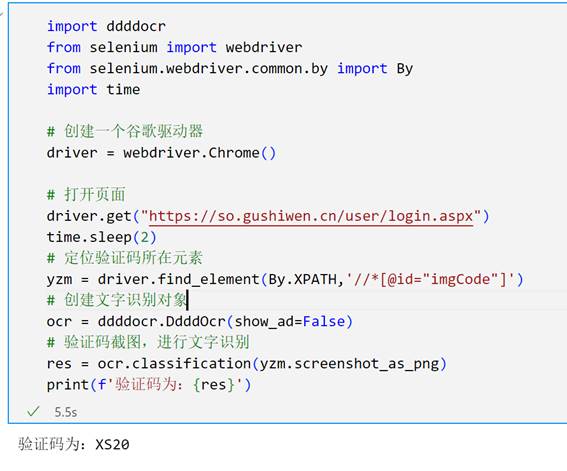
driver.get("https://so.gushiwen.cn/user/login.aspx")
time.sleep(2)
# 定位验证码所在元素
yzm = driver.find_element(By.XPATH,'//*[@id="imgCode"]')
# 创建文字识别对象
ocr = ddddocr.DdddOcr(show_ad=False)
# 验证码截图,进行文字识别
res = ocr.classification(yzm.screenshot_as_png)
print(f'验证码为:{res}')
运行该程序,验证码识别成功
思路二:获取验证码图片网址进行访问,进行识别
分析网页源码获取图片地址,对该地址发送请求,接收返回的二进制文件,通过ddddocr库识别。
import ddddocr
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import requests
# 创建一个谷歌驱动器
driver = webdriver.Chrome()
# 打开页面
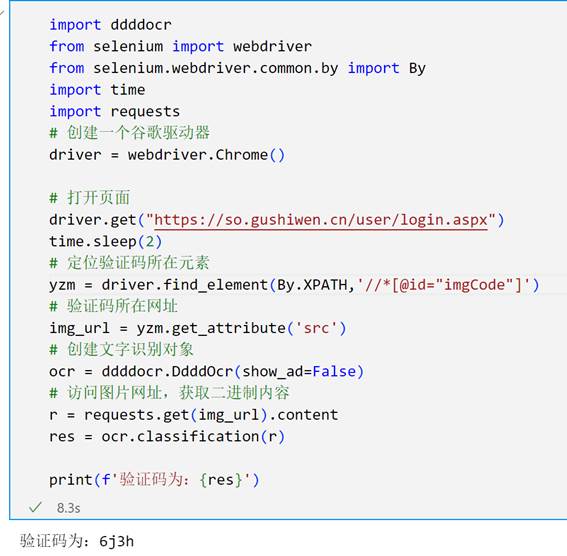
driver.get("https://so.gushiwen.cn/user/login.aspx")
time.sleep(2)
# 定位验证码所在元素
yzm = driver.find_element(By.XPATH,'//*[@id="imgCode"]')
# 验证码图片所在网址
img_url = yzm.get_attribute('src')
# 创建文字识别对象
ocr = ddddocr.DdddOcr(show_ad=False)
# 访问图片网址,获取二进制内容
r = requests.get(img_url).content
res = ocr.classification(r)
print(f'验证码为:{res}')
运行该程序,发现验证码识别出来了,但是跟网页中的验证码不一样!
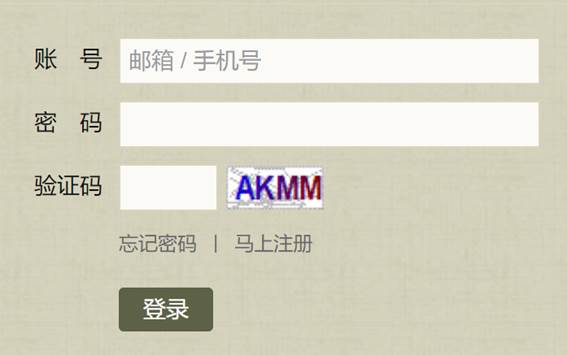
为什么呢?我们看一下验证码图片所在网址。
点击进去,发现网验证码是动态刷新的,每次访问验证码的url时验证码都会变化。
也就是说,我们通过解析源代码获取验证码的访问链接,但当我们访问该验证码链接时,验证码又刷新了,所以这个方法对于动态刷新的图片验证码行不通。
出自:https://mp.weixin.qq.com/s/2qUS3XYKPBcH8pMUw1rvQA