「能不能把这张图里的产品,都放到另一张图的桌子上?」

面对这样的要求,设计师肯定会脑瓜嗡嗡的。
把指定物品放进另一张图片不像贴张贴纸一样简单,想要做到无缝接入,贴图的形状、材质、光影等等都需要在编辑软件里细致地调整。
如果有一种能让贴图穿进背景图里,它们根据你的指令自动摆好姿势、站位的「魔法」呢?

来自香港大学、阿里巴巴和蚂蚁集团的新成果 Anydoor 为图片编辑打开了一扇「任意门」。任何物品,只需要一张照片,就能被传送到另一张图片的世界中。

·
论文链接:https://arxiv.org/pdf/2307.09481.pdf
·
项目链接:https://damo-vilab.github.io/AnyDoor-Page/
例如,想让这只柯基按照涂鸦的姿势,在墙角站卧坐躺,没有问题。

让哆啦 A 梦从背着手换成向你打招呼的姿势,分分钟搞定,还保留了原本的毛毡材质质感。

交换位置,移动物品,也是小 case。



不需要实物的多角度照片,也不需要 3D 建模,就可以看到这只鞋子的正面和侧面。

把野餐布上的另一只小熊换成这只鞋,再给它做个镜像效果,画个框,就可以静待魔法生成了。重新合成后,餐布的褶皱没有产生明显的形变。

试穿衣服也能玩成贴画游戏版本,给照片贴上想要的衣服,立体的上身效果立即可见。

随着扩散模型的发展,图像编辑界卷出了不少新成果。此前的模型已经可以根据文本提示或给定图像重新生成局部的图像区域。但是这些方法对于不在训练数据内的新图象,泛化性较差,或者需要输入多个图像,在近一个小时后,才能等到生成结果。
Anydoor 做到的是「对象传送」,这意味着将目标对象准确无缝地放置在场景图像的期望位置。具体来说,Anydoor 以目标对象为模板,重新生成场景图像被框中的局部区域,在图像合成、效果图像渲染、海报制作、虚拟试穿等应用场景都很实用。
方法简介
对于给定目标对象、场景和位置,Anydoor 实现了高保真度和多样化的零样本对象 - 场景合成。为了做到这一点,作者的核心思想是用身份和细节高度相关的特征来表示目标对象,然后将它们组合到与背景场景的交互之中。作者用一个 ID 提取器来生产有区分度的 ID token,并设计了一个以频率感知的细节提取器来获取细节图作为补充。再将 ID token 和提取器获得的细节图注入一个预训练好的文本到图像扩散模型中,指导生成所需的图像。
为了使定制对象生成泛化性更强,作者从视频中收集了同一对象的图像对,方便模型学习生成对象的外观变化。在保证场景多样性方面,他们运用了大规模统计图像。为了提高视频和图像学习效率,作者们还设计了一个自适应时间步长采样器,对不同的训练数据源采取不同的去噪步骤。

身份提取特征
作者采用了预训练的视觉编码器来提取目标对象的身份信息。由于 CLIP 的训练数据是粗略描述的文本图像对,只能嵌入语义级别的信息,而难以保留有区分度的对象身份表示。为了克服这一挑战,作者在目标图像输入 ID 提取器之前,使用了分割器以去除背景,并将对象对齐到图像中心。此操作有助于提取更简洁和更有辨别性的特征。
在保留高辨别度特征方面,自监督模型展现了更强大的能力。因此,作者选择了 DINO-V2 作为 ID 提取器的底座,使用单个线性层将 ID 提取器的 token 对齐到预训练的文本到图像的 UNet 中。
细节特征提取
由于 ID token 会失去空间分辨率,很难保持目标对象的精细细节,作者尝试了将移除过背景的对象拼接到场景图像的给定位置。虽然生成保真度有了显著提高,但生成的结果与给定的目标过于相似,缺乏多样性。为此,作者设计了一个表示对象的高频图,它可以保持精细的细节,同时允许灵活的局部变体,如手势、照明、方向等。

特征注入
在获得 ID token 和细节图后,需要将它们注入一个预先训练好的文本到图像扩散模型中来指导生成。作者选择了 Stable Diffusion 将图像投影到潜在空间中,并使用 UNet 进行概率采样。
训练策略
在这项工作中,本文利用视频数据集来捕获包含同一对象的不同帧,数据准备流程如图 4 所示:
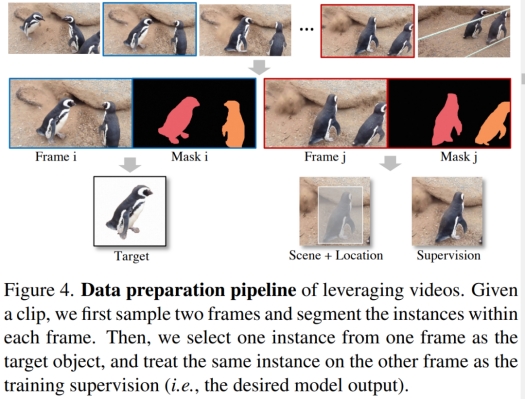
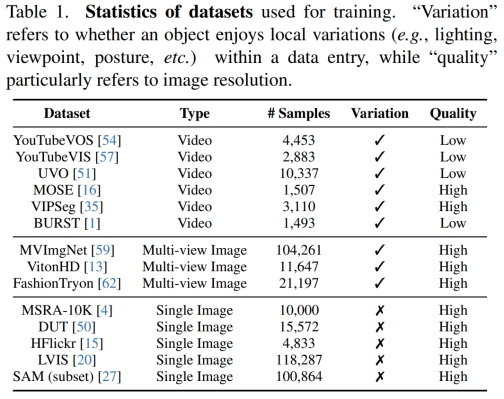
完整数据列在表 1 中,涵盖了自然场景、虚拟试穿、多视图对象等多种领域。
实验
该研究选择 Stable Diffusion V2.1 作为基础生成器。图 5 展示了与基于参考的图像生成方法的对比结果。Paint-by-Example 和 Graphit 支持与本文相同的输入格式,它们以目标图像作为输入来编辑场景图像的局部区域,而无需参数调整。此外,本文还与 Stable Diffusion 进行了比较。

图 6 表明,AnyDoor 兼具基于参考和基于调整的方法的优点,无需进行参数调整即可生成多主题合成的高保真结果。具体而言,Paint-by-Example 对于经过训练的类别(如狗和猫)(第 3 行)表现良好,但对于新概念(第 1-2 行)表现不佳。DreamBooth、Custom Diffusion 和 Cones 为新概念提供了更好的保真度,但仍然存在多主体混淆的问题。

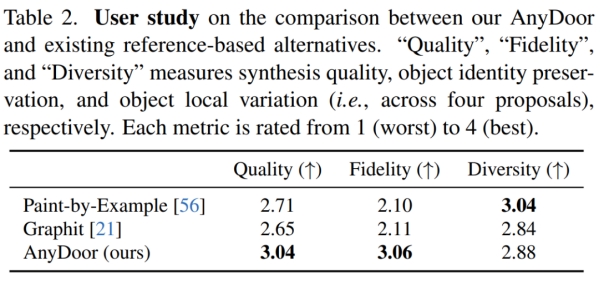
表 2 表明本文模型在保真度和数量上,尤其是保真度方面具有明显的优势。然而,由于其他方法只保持了语义一致性,而本文方法保留了实例身份,因此它们自然具有更大的多样性空间。在这种情况下,AnyDoor 仍然获得了比 Graphit 更高的速率,并且获得了与 Paint-by-Example 有竞争力的结果,这验证了本文方法的有效性。
参考链接:
https://arxiv.org/pdf/2307.09481.pdf
https://github.com/damo-vilab/AnyDoor/tree/main
https://damo-vilab.github.io/AnyDoor-Page/
https://twitter.com/alexcarliera/status/1737244116189372895
出自:https://mp.weixin.qq.com/s/zZmE4h9nE6RInvyXtpIRXA