文章地址:https://arxiv.org/pdf/2312.04461.pdf
项目地址:https://github.com/TencentARC/PhotoMaker
真的秀!以后人均设计师!

00 | 导言
现状:
在文本到图像生成方面的最新进展在合成基于给定文本提示的逼真人类照片方面取得了显着进展。然而,现有的个性化生成方法无法同时满足高效、有保证的身份保真度和灵活的文本可控性的要求。
解决:
提出一种高效的个性化文本图像生成方法PhotoMaker,
·
它主要是将任意数量的输入ID图像编码到堆栈ID嵌入中以保留ID信息。这样的嵌入作为一个统一的ID表示,既可以全面封装同一输入ID的特征,又可以容纳不同ID的特征,便于后续集成。这为更有趣和更有实际价值的应用铺平了道路。
·
·
此外,为了驱动PhotoMaker的训练,提出了一个面向id的数据构建管道来组装训练数据。在通过提议的管道构建的数据集的滋养下,PhotoMaker展示了比基于测试时间微调的方法更好的ID保存能力,同时提供了显著的速度改进,高质量的生成结果,强大的泛化能力,以及广泛的应用。
·
01 | 方法
1.1 概述
给定一些要定制的ID图像,PhotoMaker的目标是生成一个新的逼真的人物图像,该图像保留了输入ID的特征,并在文本提示符的控制下更改生成ID的内容或属性。
虽然PhotoMaker像DreamBooth一样输入多个ID图像进行定制,但PhotoMaker仍然享受与其他免调优方法相同的效率,通过单个向前传递完成定制,同时保持有希望的ID保真度和文本可食性。此外,PhotoMaker还可以混合多个输入id,生成的图像可以很好地保留不同id的特征,这为更多的应用释放了可能性。上述功能主要是由作者提出的简单而有效的堆叠ID嵌入带来的,它可以提供输入ID的统一表示。此外,为了方便训练PhotoMaker,设计了一个数据构建管道来构建一个以人为中心的数据集,按id分类。图2(a)显示了提出的PhotoMaker的概述。图2(b)显示了数据构建管道。
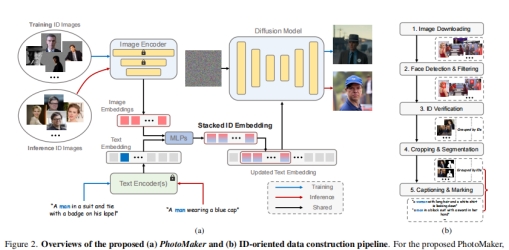
对于所提出的PhotoMaker,首先分别从文本编码器和图像编码器中获得文本嵌入和图像嵌入。然后,通过合并相应的类嵌入(如男人和女人)和每个图像嵌入来提取融合嵌入。接下来,沿着长度维度将所有融合嵌入连接起来,形成堆叠ID嵌入。最后,将堆叠的ID嵌入馈送到所有跨注意层,以自适应地合并扩散模型中的ID内容。需要注意的是,虽然在训练过程中使用的是相同ID,背景masked的图像,但是我们可以在推理过程中直接输入不需要背景失真的不同ID的图像,从而创建一个新的ID。
1.2 堆叠ID嵌入
编码器 最近的研究使用CLIP图像编码器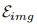 提取图像嵌入,以使其与扩散模型中的原始文本表示空间对齐。在将每个输入图像馈送到图像编码器之前,用随机噪声填充特定ID的身体部分以外的图像区域,以消除其他ID和背景的影响。由于用于训练原始CLIP图像编码器的数据主要由自然图像组成,为了更好地使模型从掩码图像中提取id相关的嵌入,在训练PhotoMaker时对图像编码器中的部分transformer层进行了微调。同时引入了额外的可学习投影层,将从图像编码器获得的嵌入注入到与文本嵌入相同的维度。设
提取图像嵌入,以使其与扩散模型中的原始文本表示空间对齐。在将每个输入图像馈送到图像编码器之前,用随机噪声填充特定ID的身体部分以外的图像区域,以消除其他ID和背景的影响。由于用于训练原始CLIP图像编码器的数据主要由自然图像组成,为了更好地使模型从掩码图像中提取id相关的嵌入,在训练PhotoMaker时对图像编码器中的部分transformer层进行了微调。同时引入了额外的可学习投影层,将从图像编码器获得的嵌入注入到与文本嵌入相同的维度。设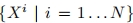 表示从用户处获取的N个输入ID图像,因此得到提取的嵌入
表示从用户处获取的N个输入ID图像,因此得到提取的嵌入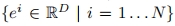 ,其中D表示投影维度。每个嵌入对应于输入图像的ID信息。对于给定的文本提示符T,使用预训练的CLIP文本编码器
,其中D表示投影维度。每个嵌入对应于输入图像的ID信息。对于给定的文本提示符T,使用预训练的CLIP文本编码器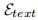 提取文本嵌入
提取文本嵌入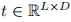 ,其中L表示嵌入的长度。
,其中L表示嵌入的长度。
叠加 最近的研究表明,在文本到图像模型中,个性化的字符ID信息可以用一些唯一的令牌来表示。本文的方法也有类似的设计,以更好地表示输入的人类图像的ID信息。具体来说,在输入标题中标记相应的类词(例如,man和woman)。然后在文本嵌入的类词对应位置提取特征向量。该特征向量将与嵌入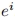 的每张图像融合。这里使用两个MLP层来执行这样的融合操作。融合嵌入可以表示为
的每张图像融合。这里使用两个MLP层来执行这样的融合操作。融合嵌入可以表示为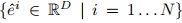 。通过结合类词的特征向量,这种嵌入可以更全面地表示当前输入ID图像。此外,在推理阶段,这种融合操作也为定制生成过程提供了更强的语义可控性。例如,可以通过简单地替换类词来定制人类ID的年龄和性别。
。通过结合类词的特征向量,这种嵌入可以更全面地表示当前输入ID图像。此外,在推理阶段,这种融合操作也为定制生成过程提供了更强的语义可控性。例如,可以通过简单地替换类词来定制人类ID的年龄和性别。
得到融合嵌入后,沿着长度维度将它们连接起来,形成堆叠id嵌入(stacked id embedding):
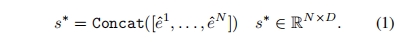
这种堆叠ID嵌入可以作为多个ID图像的统一表示,同时保留每个输入ID图像的原始表示。它可以接受任意数量的ID图像编码嵌入,因此,其长度N是可变的。与基于dreambooth的方法相比,该方法输入多个图像来微调模型以进行个性化定制,方法本质上是同时向模型发送多个嵌入。将具有相同ID的多幅图像打包成批作为图像编码器的输入后,通过一次前向传递即可获得堆叠的ID嵌入,与基于调优的方法相比,显著提高了效率。同时,与其他基于嵌入的方法相比,这种统一表示由于包含了更全面的ID信息,可以保持良好的ID保真度和文本可控性。另外,值得注意的是,虽然在训练时只使用相同ID的多张图像来形成这个堆叠ID嵌入,但在推理阶段,可以使用来自不同ID的图像来构建它。这种灵活性为许多有趣的应用程序提供了可能性。例如,可以将现实中存在的两个人混合在一起,或者将一个人和一个知名角色IP混合在一起.
合并 利用扩散模型固有的交叉注意机制,自适应地合并堆叠ID嵌入中包含的ID信息。首先用堆叠id嵌入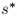 替换原始文本嵌入t中类词对应位置的特征向量,得到更新文本嵌入
替换原始文本嵌入t中类词对应位置的特征向量,得到更新文本嵌入 。那么,交叉注意操作可表述为:
。那么,交叉注意操作可表述为:
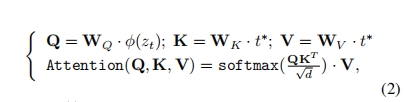
其中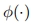 是一个嵌入,可以通过UNet去噪器从输入潜伏中编码。
是一个嵌入,可以通过UNet去噪器从输入潜伏中编码。 、
、 是投影矩阵。此外,还可以通过提示加权来调整一张输入ID图像在生成新的定制ID中的参与程度,这体现了PhotoMaker的灵活性。最近的研究发现,良好的ID自定义性能可以通过简单地调整关注层的权重来实现。为了使原始扩散模型更好地感知堆叠ID嵌入中包含的ID信息,在注意层中额外训练矩阵的LoRA残差。
是投影矩阵。此外,还可以通过提示加权来调整一张输入ID图像在生成新的定制ID中的参与程度,这体现了PhotoMaker的灵活性。最近的研究发现,良好的ID自定义性能可以通过简单地调整关注层的权重来实现。为了使原始扩散模型更好地感知堆叠ID嵌入中包含的ID信息,在注意层中额外训练矩阵的LoRA残差。
1.3 面向id的人类数据构建
由于PhotoMaker在训练过程中需要对相同ID的多个图像进行采样以构建堆叠ID嵌入,因此需要使用按ID分类的数据集来驱动PhotoMaker的训练过程。然而,现有的人类数据集要么没有标注ID信息,要么包含的场景丰富度非常有限(即只关注人脸区域)。因此,PhotoMaker提出用于构建以人为中心的文本-图像数据集的管道,该数据集按不同的id进行分类。图2(b)显示了拟议的管道。通过这个管道,可以收集一个面向ID的数据集,其中包含大量的ID,每个ID都有多个图像,这些图像包含不同的表情、属性、场景等。这个数据集不仅促进了PhotoMaker的训练过程,而且可能会激发未来潜在的id驱动研究。
图片下载 首先列出一个名人名单,该名单可以从VoxCeleb1和VGGFace2中获得。根据列表在搜索引擎中搜索名字并抓取数据。每个名字大约下载了100张图片。为了生成更高质量的人像图像,在下载过程中过滤掉了分辨率小于512的最短边的图像
人脸检测和过滤 首先使用retinaNet检测人脸边界框,滤除小尺寸(小于256 × 256)的检测。如果图像中没有任何符合要求的边界框,则该图像将被过滤掉。然后,对剩余的图像执行ID验证。
身份验证 由于一张图像可能包含多个面孔,首先需要确定哪个面孔属于当前的身份组。具体来说,将当前身份组检测框中的所有人脸区域送入ArcFace,提取身份嵌入,并计算每对人脸的L2相似度。将每个身份嵌入计算的相似度与所有其他嵌入的相似度相加,得到每个边界框的得分。作者为每个具有多个面的图像选择具有最高总和分数的边界框。在边界框选择之后,重新计算每个剩余框的总和分数。作者按ID组计算总得分的标准差δ。使用8δ作为阈值来过滤id不一致的图像。
裁剪和分割 首先根据检测到的人脸面积对图像进行较大的方框裁剪,同时保证裁剪后的人脸区域能够占据图像的10%以上。由于在将输入ID图像发送到图像编码器之前,需要从输入ID图像中删除不相关的背景和ID,因此需要为指定的ID生成掩码。具体来说,使用Mask2Former对“person”类执行全景分割。留下与ID对应的面部边界框重叠度最高的掩码。此外,选择丢弃未检测到掩码的图像,以及边界框与掩码区域之间没有重叠的图像。
标题和标记 使用BLIP2为每个裁剪的图像生成标题。由于需要标记类词(例如,man、woman和boy)以促进文本和图像嵌入的融合,因此使用BLIP2的随机模式重新生成不包含任何类词的字幕,直到出现类词。在获得标题后,将标题中的类词单一性,以聚焦于单个ID。接下来,需要标记对应于当前ID的类字的位置。只包含一个类词的标题可以直接注释。对于包含多个类词的标题,计算每个标识组标题中包含的类词。出现次数最多的类字将作为当前标识组的类字。然后,使用每个标识组的类词来匹配和标记该标识组中的每个标题。对于不包含与对应身份组匹配的类词的标题,采用依赖解析模型,根据不同的类词对标题进行分割。并且计算分割后的子标题与图像中特定ID区域之间的CLIP分数。此外,通过SentenceFormer计算当前段的类词与当前身份组的类词之间的标签相似度。这里选择标记CLIP分数和标签相似度的最大乘积对应的类词
02 | 实验结果
2.1 Setup
实现细节 为了生成更逼真的人体肖像,采用SDXL模型stable-diffusion-xl-base-1.0作为文本到图像的合成模型。相应的,训练数据的分辨率调整为1024 × 1024。使用CLIP v - l /14和一个额外的投影层来获得初始图像嵌入。对于文本嵌入,在SDXL中保留原始的两个文本编码器以进行提取。整体框架由Adam在8个NVIDIA A100 gpu上进行了两周的优化,批处理规模为48个。LoRA权重的学习率设置为1e−4,其他可训练模块的学习率设置为1e−5。在训练过程中,随机抽取1-4张与当前目标ID图像具有相同ID的图像,形成堆叠ID嵌入。此外,为了通过使用无分类器引导来提高生成性能,有10%的机会使用空文本嵌入来替换原始更新的文本嵌入t *。还使用概率为50%的掩蔽扩散损失来鼓励模型生成更忠实的id相关区域。在推理阶段,使用延迟主语条件反射来解决文本条件和ID条件之间的冲突。使用50步DDIM采样器。无分类器引导的尺度设为5。
评价指标 继DreamBooth之后,使用DINO和CLIP-I指标来测量ID保真度,并使用CLIP-T指标来测量提示保真度。为了更全面的评估,还通过检测和裁剪生成图像与具有相同ID的真实图像之间的面部区域来计算人脸相似度。使用RetinaFace作为检测模型。人脸嵌入是通过FaceNet提取的。为了评估生成质量,采用FID度量。重要的是,由于大多数基于嵌入的方法倾向于将面部姿势和表情结合到表示中,因此生成的图像通常缺乏面部区域的变化。因此,作者提出了一个名为Face Diversity的度量来衡量生成的面部区域的多样性。具体来说,首先在每个生成的图像中检测和裁剪人脸区域。接下来,计算所有生成图像的每对面部区域之间的LPIPS分数并取平均值。这个值越大,生成的面部区域的多样性就越高。
评估数据集 评估数据集包括25个id,其中包括来自Mystyle的9个id和自己收集的另外16个id。请注意,这些id不会出现在训练集中,用于评估模型的泛化能力。为了进行更全面的评估,准备了40个提示,涵盖了各种表情、属性、装饰、动作和背景。对于每个ID的每个提示,生成4个图像用于评估.
2.2 结果

不同方法的普通语境比较
可以观察到,PhotoMaker 可以很好地满足生成高质量图像的能力,同时确保 ID 的高保真度。
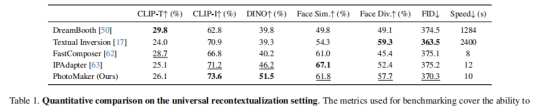
普遍性语境化背景的定量比较

应用在(a)艺术品和老照片,以及(b)更改年龄或性别
还能进行其他风格的生成,如草图、漫画、动画等。

不同人物身份也能进行混合,创造出一个全新的人物形象。赫本和爱莎公主的组合版兼顾了两者的特点:

03 | 使用
官方提供了很详细的使用步骤,首先我们需要下载模型权重
·
·
from huggingface_hub import hf_hub_download
photomaker_path = hf_hub_download(repo_id="TencentARC/PhotoMaker", filename="photomaker-v1.bin", repo_type="model")
其次构建Pipe
·
·
import torch
import os
from diffusers.utils import load_image
from diffusers import EulerDiscreteScheduler
from photomaker.pipeline import PhotoMakerStableDiffusionXLPipeline
### Load base model
pipe = PhotoMakerStableDiffusionXLPipeline.from_pretrained( base_model_path, # can change to any base model based on SDXL torch_dtype=torch.bfloat16, use_safetensors=True, variant="fp16").to(device)
### Load PhotoMaker checkpoint
pipe.load_photomaker_adapter( os.path.dirname(photomaker_path), subfolder="", weight_name=os.path.basename(photomaker_path), trigger_word="img" # define the trigger word)
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
### Also can cooperate with other LoRA modules
# pipe.load_lora_weights(os.path.dirname(lora_path), weight_name=lora_model_name, adapter_name="xl_more_art-full")
# pipe.set_adapters(["photomaker", "xl_more_art-full"], adapter_weights=[1.0, 0.5])
pipe.fuse_lora()
再者组织输入图像
·
### define the input ID images
input_folder_name = './examples/newton_man'
image_basename_list = os.listdir(input_folder_name)
image_path_list = sorted([os.path.join(input_folder_name, basename) for basename in image_basename_list])
input_id_images = []
for image_path in image_path_list: input_id_images.append(load_image(image_path))
最后运行生成
·
·
# Note that the trigger word `img` must follow the class word for personalization
prompt = "a half-body portrait of a man img wearing the sunglasses in Iron man suit, best quality"
negative_prompt = "(asymmetry, worst quality, low quality, illustration, 3d, 2d, painting, cartoons, sketch), open mouth, grayscale"
generator = torch.Generator(device=device).manual_seed(42)
images = pipe( prompt=prompt, input_id_images=input_id_images, negative_prompt=negative_prompt, num_images_per_prompt=1, num_inference_steps=num_steps, start_merge_step=10, generator=generator,).images[0]
gen_images.save('out_photomaker.png')
当然,我们也可以本地网页体验,直接python gradio_demo/app.py即可。
出自:https://mp.weixin.qq.com/s/lXT-8D0Qq_cWfTkAKSTINw