超越Animate Anyone! 南加大&字节提出MagicPose,不需任何微调就可生成逼真的人类视频
南加州大学&字节提出MagicPose,一种新颖有效的方法,提供逼真的人类视频生成,实现生动的运动和面部表情传输,以及不需要任何微调的一致的野外零镜头生成。
MagicPose可以精确地生成外观一致的结果,而原始的文本到图像模型(如Stable
Diffusion和ControlNet)很难准确地保持主体身份信息。
此外,MagicPose模块可以被视为原始文本到图像模型的扩展/插件,而无需修改其预训练的权重。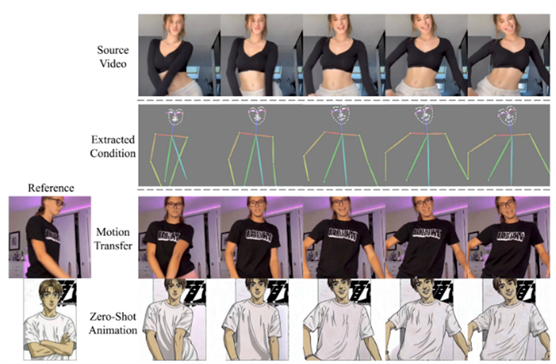
相关链接
论文链接:https://arxiv.org/pdf/2311.12052.pdf
项目链接:https://github.com/Boese0601/MagicDance
视频演示:https://www.youtube.com/watch?v=VPJe6TyrT-Y
论文阅读
 MagicPose:现实的人类姿势和面部表情重新定位与身份意识扩散
MagicPose:现实的人类姿势和面部表情重新定位与身份意识扩散
摘要
在这项工作中,我们提出了MagicPose,这是一种基于扩散的模型,用于在具有挑战性的人舞视频中进行2D人体动作和面部表情的转移。
具体来说,我们的目标是生成由新颖的姿势序列驱动的任何目标身份的人舞视频,同时保持身份不变。为此,我们提出了一种两阶段的训练策略,以分离人体动作和外观(例如面部表情、肤色和着装),包括对同一数据集的人舞姿势的外观控制块的预训练和对外观-姿势-联合控制块的精细调整。
我们的新颖设计使外观控制具有在时间上一致的上半身、面部属性甚至背景。该模型在未见过的人类身份和复杂的运动序列上也具有良好的泛化能力,无需在具有不同人类属性的数据上进行任何微调,并利用图像扩散模型的先验知识。
此外,所提模型易于使用,可被视为Stable Diffusion的插件模块/扩展。我们还展示了该模型在零样本2D动画生成方面的能力,不仅可以实现从一个身份到另一个身份的外观转换,还可以仅基于姿态输入实现卡通风格的渲染。大量的实验证明了我们在TikTok数据集上的优越性能。
方法
 提出的MagicPose流程概述。用于可控的人类舞蹈视频生成与运动和面部表情转移。外观控制模型是整个稳定扩散UNet的副本,初始化为相同的权值。稳定扩散UNet在整个训练过程中被冻结。
提出的MagicPose流程概述。用于可控的人类舞蹈视频生成与运动和面部表情转移。外观控制模型是整个稳定扩散UNet的副本,初始化为相同的权值。稳定扩散UNet在整个训练过程中被冻结。
·
在(a)外观控制预训练中,我们训练外观控制模型及其多源自注意模块。
·
在(b)外观解纠缠姿态控制过程中,我们联合微调外观控制模型(用a)中的权重初始化)和姿态控制网。在这些步骤之后,我们冻结了所有以前训练过的模块,并微调了用AnimateDiff初始化的运动模块。
结果展示
人类动作和面部表情传递
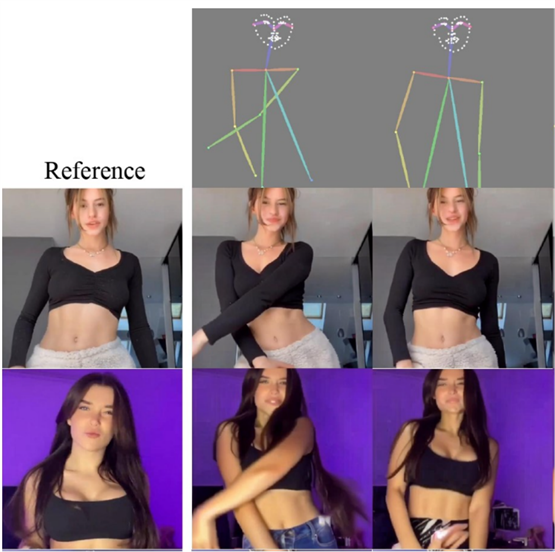
 人体运动和面部表情转移的可视化。MagicPose能够在多种姿态骨架和面部地标输入的情况下生成生动逼真的运动和表情,同时准确地保持参考图像输入的身份信息。
人体运动和面部表情转移的可视化。MagicPose能够在多种姿态骨架和面部地标输入的情况下生成生动逼真的运动和表情,同时准确地保持参考图像输入的身份信息。
Zero Shot动画
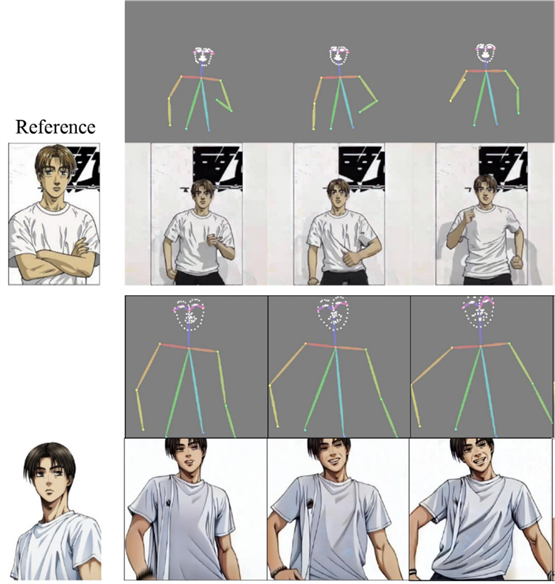
Zero Shot 2D动画生成的可视化。MagicPose可以从卡通风格的图像中精确生成身份信息,甚至在经过真人舞蹈视频训练后无需进一步微调。



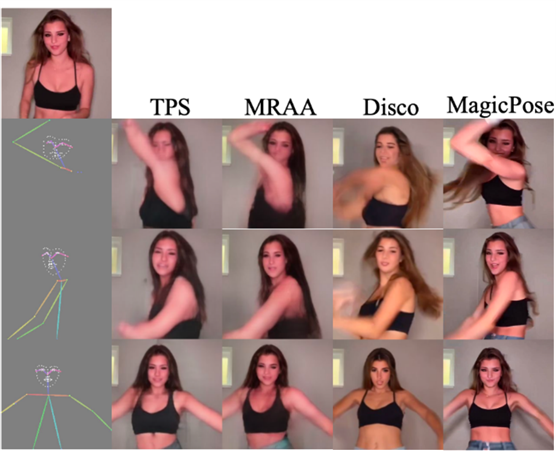
与近期作品比较
定性的比较

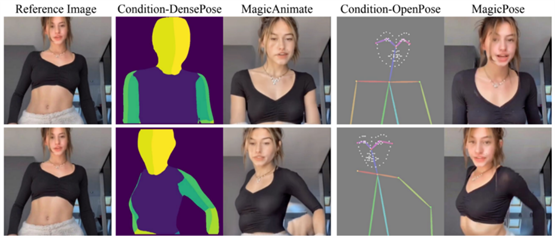
定量的比较
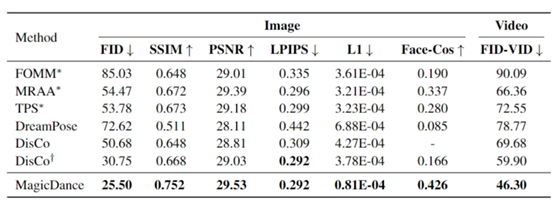 MagicPose与最近SOTA方法DreamPose和Disco的定量比较。↓表示越低越好,反之亦然。
MagicPose与最近SOTA方法DreamPose和Disco的定量比较。↓表示越低越好,反之亦然。
带有*的方法直接使用目标图像作为输入,比OpenPose包含更多的信息。†表示Disco比我们提出的MagicPose在其他数据集上进行了更多的预训练,MagicPose只使用TikTok数据集中的335个视频序列进行预训练和微调。face - cos表示生成图像与地面真图像之间的人脸区域的余弦相似度。
出自:https://mp.weixin.qq.com/s/Ff9c7edYOxExvnuonS8vDw