眼尖的我,昨天在腾讯git上发现了这一个新的项目,没开源但是现在有论文。
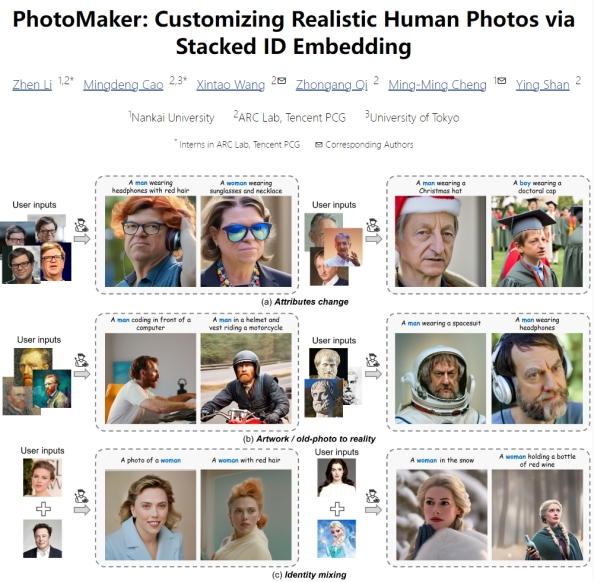
不仅能输入少量真人照片做写真,还能输入绘画类形象、雕塑形象,根据这个形象出图。
还能输入两个图片,融合他们的长相,即使是真人照片+漫画也完全ok。
项目主页:https://photo-maker.github.io/
不过,这个项目主要是为了生成写实人像的哈,虽然能处理非写实的数据,但是生成的图还是针对写实人像的。
大概讲了什么,说几条比较关键的。
输入图像的处理?用随机噪声填充了身体部分和背景,为了消除非脸部的图像区域影响。
训练clip图像编码部分。由于用于原始clip的数据大部分是自然图像,为了更好地提取脸部特征,对这部分模型参数进行了微调。
在文本输入上做文章,把man和woman这种单词与文本embedding结合,得到一个融合后的向量,这个向量会与图像embedding做融合。
会把同一个人脸的多个图像向量拼接起来训练,但是测试时可以拼接不同的人脸,所以可以有融合的效果,非常灵活。
为了原始的sd模型能够更好地感知这些人脸信息,训练了attention层的lora。
主要技术是这些,后面还讲了摄影师训练的工作流,包括如何处理图像数据之类的,感兴趣可以看看原文。
这工作看起来非常nice呀,期待一下,比facechain那些有更大的改进,目前看好photomaker。
出自:https://mp.weixin.qq.com/s/2g47AuKcNyLWqVstb5306Q