【AI绘图工具】太爆炸了,AI出图速度100fps(每秒100张图片),比LCM、SDXL Turbo更快,目前No.1
记得前面介绍的LCM、SDXL Turbo吗,出图够快了吧,还有更快的,目前世界上出图最快的产品。
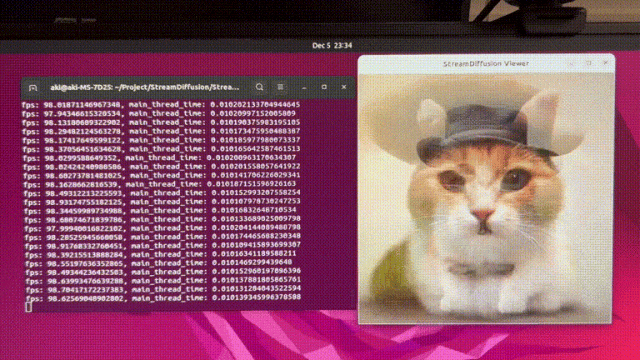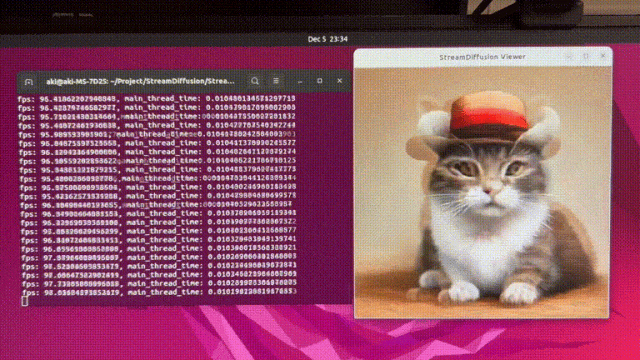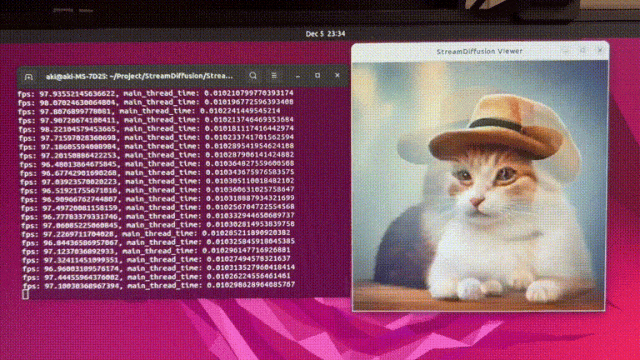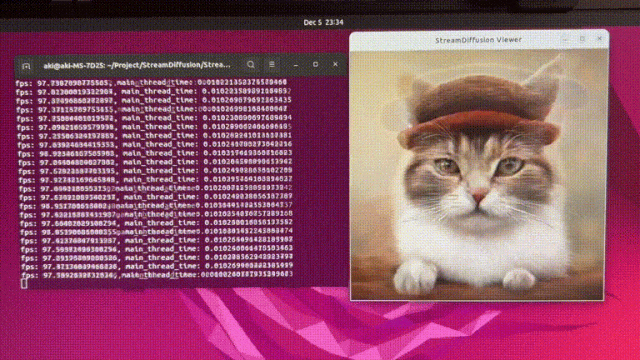
今天被一则消息惊到了

就是前段时间刷屏的基于LCM和SDXL Turbo每秒生成110张图像的项目,StreamDiffusion居然开源了。
项目地址:https://github.com/cumulo-autumn/StreamDiffusion
论文地址:https://arxiv.org/abs/2312.12491
想做相关实时图像生成产品的可以去用起来了,我们都喜欢开源的项目,我在colab上也建好了,感兴趣可以去体验一下,生成图片速度真的快
colab地址:
https://colab.research.google.com/github/hewis123/stream-d/blob/main/Untitled2.ipynb
今天我就来介绍一下这个产品工具吧,我都不知道该把它归类入视频工具还是图像工具,底层逻辑当然还是AI绘图工具了。
一、StreamDiffusion 产品介绍
项目研究团队来自美国和日本相关大学机构的成员
StreamDiffusion可以以几乎 100fps(每秒100张)
的速度生成图像!
使用 SD-Turbo,512x512,txt2img,可以在
10 毫秒内生成一张图像!
这肯定是目前AI生成图片速度最快的,毫无疑问!
二、现有扩散模型在解决实时性方面的策略
针对扩散模型在商业化中的应用趋势,主要集中在提高扩散模型的运行速度,以便在实时交互场景中更有效地生成图像方面开展工作,主要有以下一些关键点:
1、商业化扩散模型:扩散模型因其在商业领域的潜力而受到关注,特别是在元宇宙、在线视频流和广播等领域,这些领域需要高吞吐量和低延迟的扩散管道以确保高效的人际交互。
2、减少去噪迭代次数:为了提高吞吐量和实时交互能力,当前的研究主要集中在减少去噪迭代的次数。例如,将50次迭代减少到只有几次,或者甚至一次迭代。
3、使用神经常微分方程(ODE):通过使用ODE求解器,可以在不需要额外训练的情况下提高扩散模型的速度。这种方法通过将扩散过程重新框架化为ODE来实现。
4、自适应步长求解器:这种方法通过调整步长来加速扩散过程,同时保持图像质量。
5、预测-校正方法:这是一种通过预测中间步骤并进行校正来提高扩散模型效率的方法。
6、量化:通过量化扩散模型可以减少模型的计算复杂度,从而提高运行速度。
7、模型蒸馏:通过蒸馏技术,可以将大型的扩散模型压缩到更小的模型,同时保持图像生成的质量。
8、一致性模型:通过改进采样过程的效率来提高扩散模型的效率,而不会显著牺牲图像质量。
这些策略都是为了在不牺牲图像质量的前提下,提高扩散模型的运行速度,使其能够在实时交互环境中更有效地工作。
StreamDiffusion 与这些现有策略不同,它提供了一个全面的管道级解决方案,专门针对高吞吐量进行了优化。
三、StreamDiffusion工作原理
现有的扩散模型在从文本或图像提示创建图像方面表现出色,但在实时交互方面往往表现不佳。为了解决这个问题,项目团队提出了一种新的简单方法,将原始的顺序去噪过程转化为批量去噪过程。这种方法通过消除传统的等待和交互方法,实现了流畅和高吞吐量的流。为了处理数据输入频率和模型吞吐量之间的差异,他们设计了一种新的输入输出队列来并行化流处理过程。此外,现有的扩散管道使用无分类器指导来强制生成的结果与提示条件一致,但项目团队指出当前的实现由于负面条件去噪的固有冗余性而效率低下。为了缓解这种冗余计算,他们提出了一种新的残差无分类器指导(RCFG)算法,将负面条件去噪步骤减少到只有一步或者零步。
StreamDiffusion的关键组件,包括Stream Batch策略、RCFG、输入输出队列、随机相似性过滤器、预计算过程和模型加速工具。
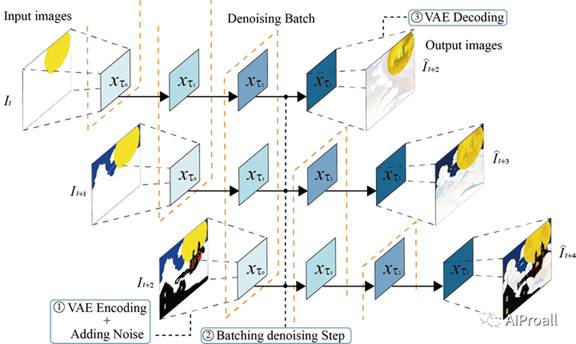
1、Stream Batch策略:
·
传统的扩散模型在生成图像时会顺序执行去噪步骤,这导致处理时间随着步骤数量的增加而线性增长。
·
Stream
Batch策略将顺序去噪操作重组为批量处理过程,每个批次包含一定数量的去噪步骤。
·
这种方法允许每个批次元素通过单个U-Net处理步骤进一步推进去噪序列,有效减少了对多个U-Net推理的需求。
·
通过迭代应用这种方法,可以将输入图像编码在时间步t转换为时间步t+n的图像到图像结果,从而简化去噪过程。
·
2、Residual Classifier-Free Guidance (RCFG):
·
现有的扩散模型使用无分类器指导(CFG)来强化生成图像与给定提示的一致性。
·
传统的CFG在每次推理时都需要计算负面条件去噪残差噪声,这增加了计算成本。
·
RCFG通过引入虚拟残差噪声和虚拟负面条件嵌入来减少额外的U-Net推理成本。
·
RCFG有两种形式:Self-Negative RCFG和Onetime-Negative RCFG,前者在整个过程中使用原始输入图像的潜在表示,后者只在第一步计算负面条件去噪残差噪声。
·
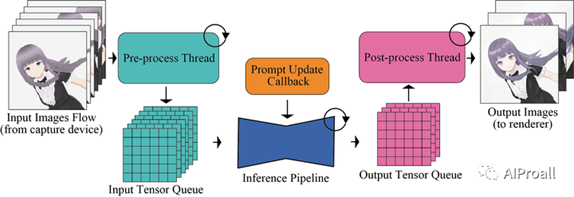
3、输入输出队列:
·
为了处理数据输入频率和模型吞吐量之间的差异,设计了一种新的输入输出队列来并行化流处理过程。
·
输入队列用于缓存输入,输出队列用于处理解码后的张量,从而实现与U-Net处理的并行。
·
这种设计允许在输入图像处理和输出图像处理之间进行有效的负载平衡,提高了整体系统的效率。
·
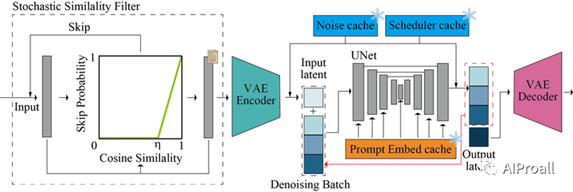
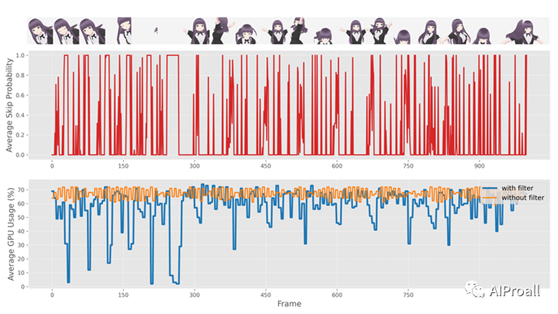
4、随机相似性过滤器(Stochastic Similarity Filter, SSF):
·
SSF用于在输入图像相似性较高时减少GPU的使用。
·
通过计算连续输入图像之间的相似性,确定是否需要处理图像,从而节省计算资源。
·
在静态场景中,SSF显著减少了GPU的功耗。
·
5、预计算过程:
·
为了提高效率,提出了一种预计算策略,包括预计算提示嵌入、去噪步骤的噪声强度系数以及噪声样本。
·
这种策略减少了在推理过程中的重复计算,提高了模型的运行速度。
·
6、模型加速工具:
·
使用TensorRT来优化U-Net和VAE引擎,以提高推理速度。
·
TensorRT是NVIDIA提供的一个优化工具包,用于提高深度学习应用的吞吐量和效率。
·
使用了Tiny AutoEncoder(TAESD)作为模型加速器,它是一个轻量级且高效的VAE,用于快速将潜在表示转换为全尺寸图像。
·
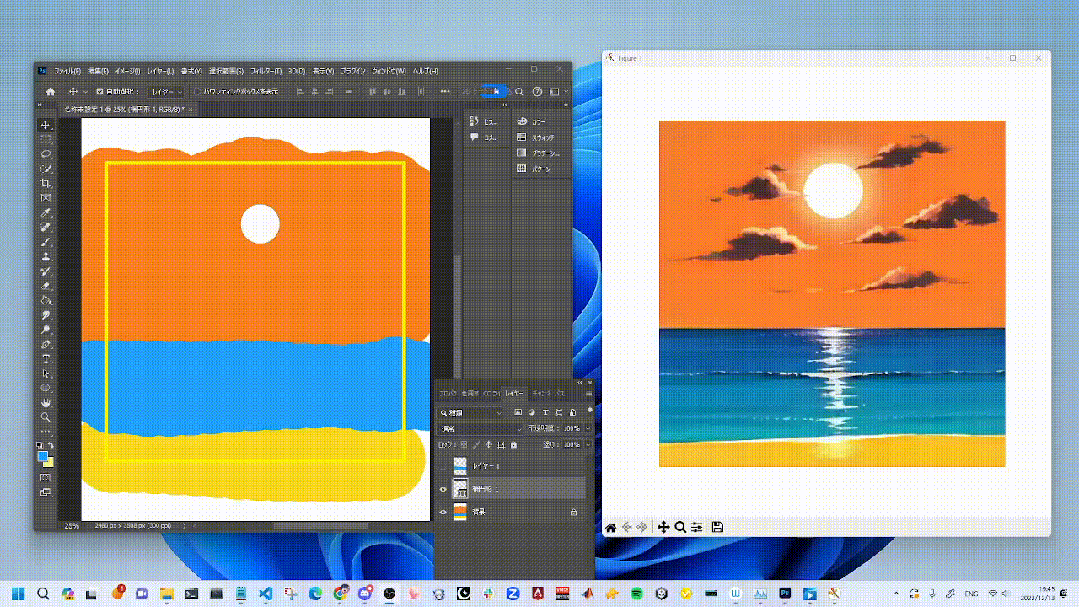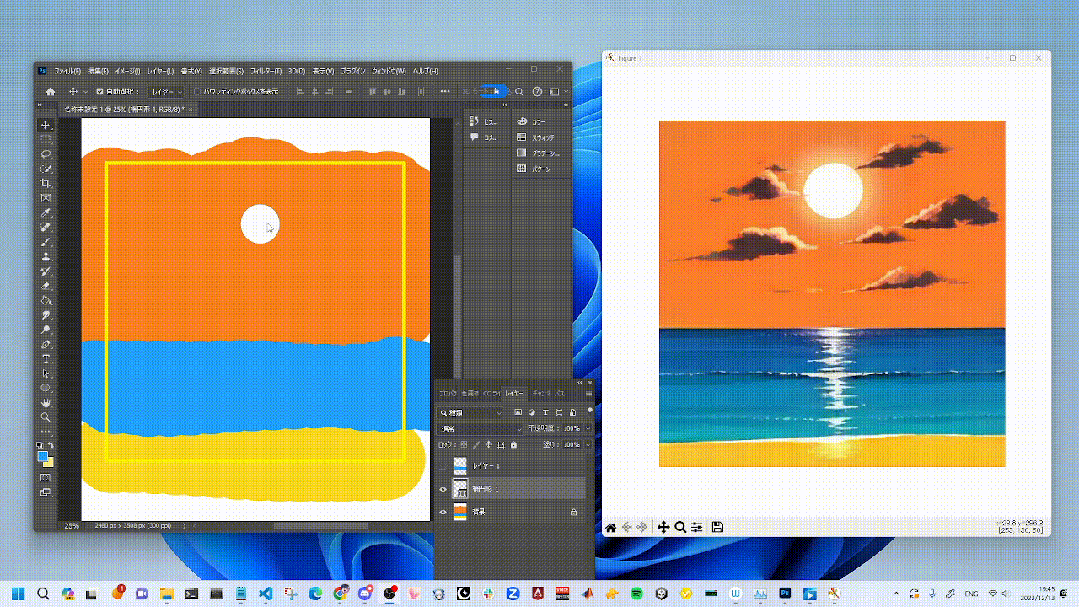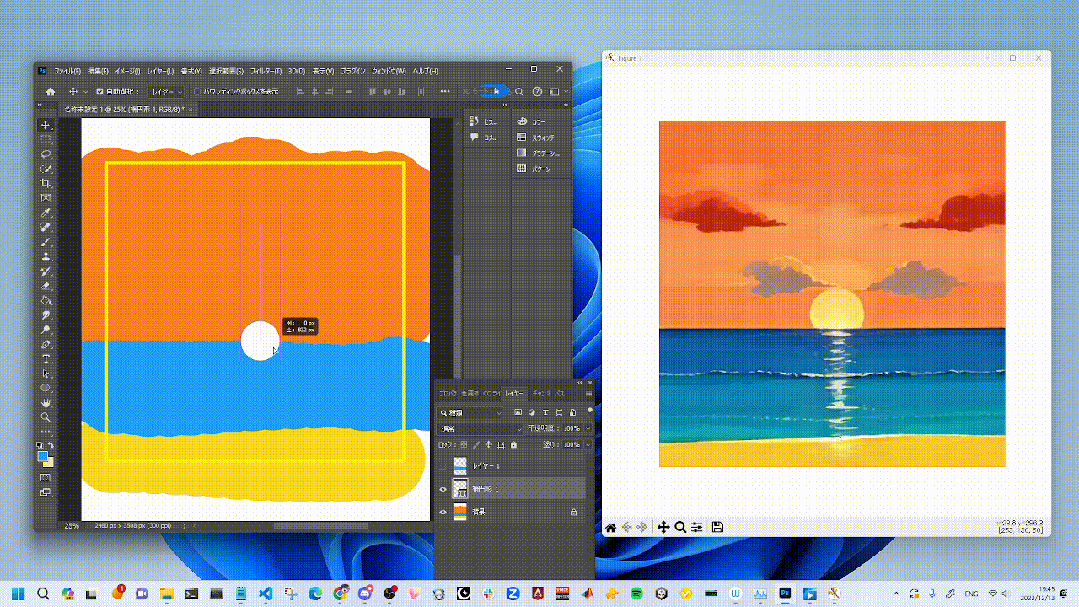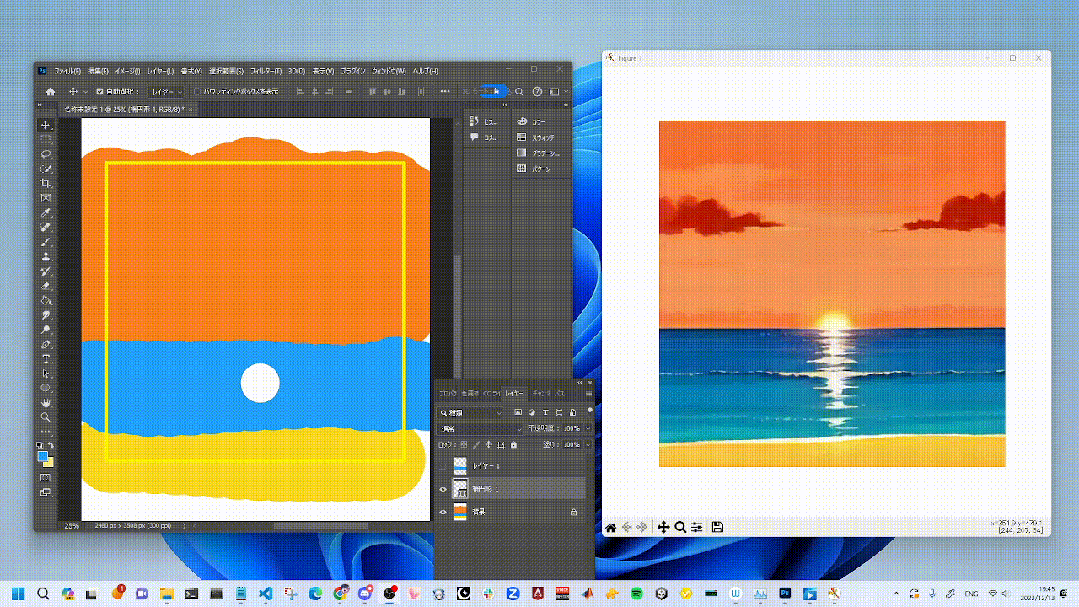
四、效果展示
(好多视频放不上来,后台私我发您)
五、评测情况
对 StreamDiffusion 的性能进行了定量评估,包括去噪批处理的效率比较、能量消耗评估以及消融研究。
1、去噪批处理的效率比较:
比较了StreamDiffusion的去噪批处理策略与传统的顺序U-Net循环在不同去噪步骤下的平均推理时间。
结果显示,即使在应用了TensorRT加速工具的情况下,StreamDiffusion在不同的去噪步骤上仍然显著提高了效率,与AutoPipeline-ForImage2Image相比,速度提升从1步去噪的29.7倍到10步去噪的13.0倍不等。
2、能量消耗评估:
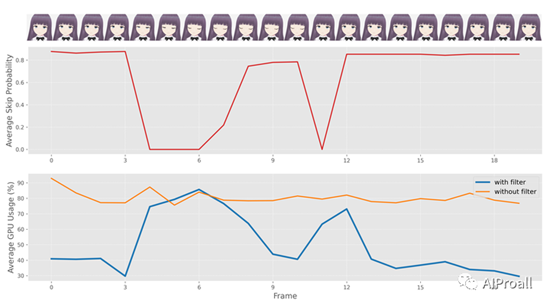
通过实验,评估了在静态场景和动态场景下,应用随机相似性过滤器(SSF)对GPU功耗的影响。
在静态场景下,SSF显著降低了GPU的平均功耗,例如在RTX3060 GPU上从85.96w降低到35.91w。
在动态场景下,尽管输入图像变化较大,SSF仍然能够有效地减少GPU功耗,如在RTX4090 GPU上从236.13w降低到199.38w。
3、消融研究:
进行了消融研究,以分析StreamDiffusion中各个组件对平均推理时间的影响。
实验结果表明,移除Stream Batch处理会导致显著的时间消耗增加,尤其是在多步去噪时。
移除TensorRT(TRT)和预计算(Pre-computation)也会导致时间成本的增加,但影响较小。
移除输入输出队列(IO queue)对平均推理时间也有影响,这主要是因为预处理和后处理的并行化问题。
即使在没有任何优化的情况下,StreamDiffusion的性能也显著优于AutoPipeline-ForImage2Image。
4、实时图像到图像转换的生成结果:
使用StreamDiffusion管道进行实时图像到图像转换的生成结果,展示了在低吞吐量下,从输入图像实时接收并生成高质量图像的能力,同时有效地与指定的提示条件对齐。
这些能力特别适用于实时游戏图形渲染、生成相机效果滤镜、实时面部转换和AI辅助绘图等应用。
出自:https://mp.weixin.qq.com/s/eVUN82JFShR1BdHmYfZe6Q