ZEPHYR-7B 是新一代大型语言模型(LLMs)之一,它受到了 AI 社区的极大欢迎。该模型由 Hugging Face 创建,实际上是在公共数据集上训练的 Mistral-7B 的微调版本,但也通过知识蒸馏技术进行了优化。该模型取得了令人难以置信的成果,在多种任务中超越了许多更大的模型。
在最近的研究中,蒸馏已经成为提升开放式AI模型在各种任务中表现的宝贵技术。然而,它未能达到与原始教师模型相同的性能水平。用户观察到这些模型通常缺乏“意图对齐”,意味着它们并不总是以符合人类偏好的方式行事。因此,它们倾向于产生无法准确回应用户查询的回复。
量化意图对齐一直存在挑战,但最近的努力已经导致了像MT-Bench和AlpacaEval这样的基准测试的开发,这些基准测试专门设计用来评估这一方面。这些基准测试产生的分数与人类对模型输出的评分密切相关,并且验证了这样一个定性概念:专有模型的表现优于接受人类反馈训练的开放模型,而后者又优于通过蒸馏训练的开放模型。这强调了即使在大规模的项目中,如LLAMA2-CHAT所见,收集细致的人类反馈对于对齐的重要性。
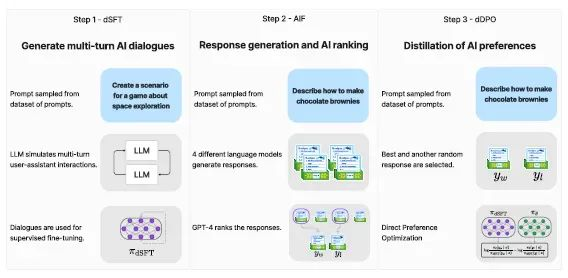
验证这种方法是ZEPHYR-7B背后的主要目标,ZEPHYR-7B是Mistral-7B的对齐版本。这个过程包括三个关键步骤:
1. 大规模数据集构建,采用自指导风格,使用UltraChat数据集,随后进行蒸馏式监督微调(dSFT)。
2. 通过一系列聊天模型完成和随后的GPT-4(UltraFeedback)评分来收集人工智能反馈(AIF),然后将其转化为偏好数据。
3. 将蒸馏直接偏好优化(dDPO)应用于使用收集的反馈数据的dSFT模型。
ZEPHYR-7B背后的微调过程源于三种基本技术:
1. 蒸馏监督式微调(dSFT):从一个原始语言模型开始,需要训练以生成对用户提示的响应。这个传统步骤通常涉及在包含高质量指令和响应的数据集上进行监督式微调(SFT)。然而,当一个教师语言模型可用时,模型可以直接生成指令和响应,这个过程被称为蒸馏监督式微调(dSFT)。
2. 通过偏好的人工智能反馈(AIF):利用人类反馈来增强语言模型。传统上,通过评估模型响应的质量来收集人类反馈。在蒸馏的背景下,使用教师模型的人工智能偏好来评估其他模型生成的输出。
3. 精炼直接偏好优化(dDPO):旨在通过最大化排名偏好响应高于不太偏好的响应的可能性来完善dSFT模型。这是通过一个偏好模型实现的,该模型由一个奖励函数定义,该函数利用学生语言模型。以前使用AI反馈的方法主要采用强化学习方法,如近端策略优化(PPO),以根据这个奖励函数优化模型参数。这些方法通常涉及首先训练奖励函数,然后通过从当前策略中采样来生成更新。
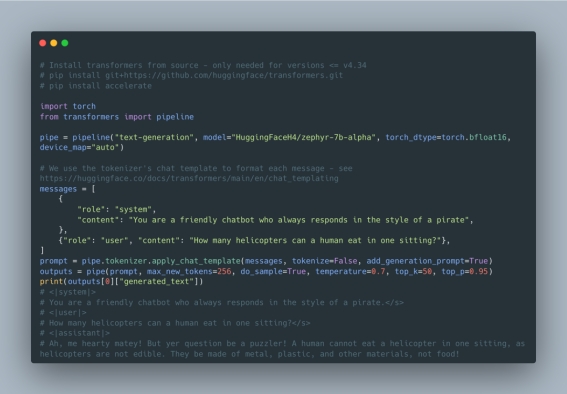
使用ZEPHYR-7B
ZEPHYR-7B可以通过HuggingFace的transformers库使用一个非常简单的接口来获取。执行ZEPHYR-7B只需要调用库的pipeline()函数。
结果
Hugging Face对ZEPHYR-7B的主要评估集中在单轮和多轮聊天基准测试上,这些测试衡量了模型遵循指令的能力以及在不同领域对复杂提示作出回应的能力。
1. MT-Bench:这个多轮基准测试包含了8个不同知识领域的160个问题。在MT-Bench中,模型面临着回答一个初始问题的挑战,并随后对一个预定义的问题提供后续回应。每个模型的回应质量由GPT-4使用1到10的等级进行评估。最终得分是根据两轮的平均评分得出的。
2. AlpacaEval:另一方面,羊驼评估是一个单回合基准测试,模型的任务是针对805个涉及各种主题的问题生成回应,主要关注其有用性。GPT-4也会评估这些模型回应。然而,最终的衡量标准是与基线模型相比的成对胜率。
除了这些基准测试之外,Hugging Face还在Open LLM排行榜上评估了ZEPHYR-7B的性能。这个排行榜旨在通过四项多类别分类任务来评估语言模型的表现,包括ARC、HellaSwag、MMLU和Truthful QA。每项任务都提出了独特的挑战,并要求模型在分类准确性方面表现出色。
结果非常令人印象深刻:
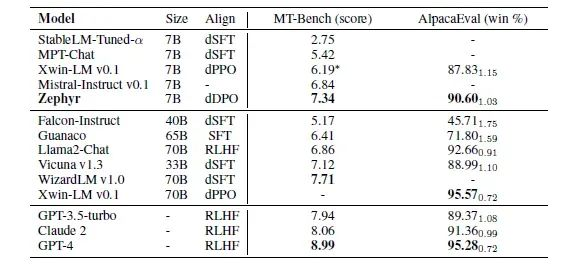
ZEPHYR-7B代表了一个重要的验证,即对于高度专业化的任务,小型高性能LLM确实有其一席之地。
出自:https://mp.weixin.qq.com/s/9O6oHEMRCjt4VY7adFEBmg