让AI记住你说的话、让AI给你生成几十万字的小说!StreamingLLM 让无限长token成为可能
如今全世界有很多公司都在研究AI大模型(LLM)。但是在我们使用ChatGPT这样AI时候,可能聊着聊着它就告诉你要重新开始对话了!这就好像七秒记忆的鱼一样,转身就忘记了刚才聊天内容。你不得不重新开始!
如果AI大模型能够像人一样长时间对话,还能记住之前的内容,我们岂不是可以让它做很多事情?
比如写一个几十万字的小说!比如AI可以像你的朋友一样,记住了你的喜好,你说的每句话!除此之外,你可以要求 AI 助手总结长达数千页的报告,分析你项目里的代码!

今天,我要给大家介绍一种高效的框架StreamingLLM!,它可以让任何基于Transformer的语言模型(LLM)处理无限长度的文本,而不需要任何微调或额外的训练。

MIT、Meta AI、CMU的论文
传统AI大模型鱼一样健忘的原因
LLM都是在一定长度的数据块(或者叫做序列)上进行预训练的,比如Llama 2就是在4000个单词(或者叫做token)的序列上进行预训练的。
这意味着,当一个用户输入的文本超过了这个长度限制时(即使是分成多个不同的输入),LLM就会开始降低性能,也就是说,输出的质量会变得更差。
这对于想要使用LLM来帮助客户或员工进行开放式对话的企业来说是不可接受的。因为用户希望LLM能够在整个对话中保持一致的响应速度、信息量和相关性,而不是在对话进行到一半或者快结束时突然变得冷淡、迟钝或者无关。
StreamingLLM是什么?怎么解决AI健忘的?
StreamingLLM是由麻省理工学院(MIT)的研究团队提出的,它基于一个简单而有效的观察:在Transformer中,注意力机制(Attention)对于前面的token有着很强的偏好,即使它们并不是语义上很重要的。
这种现象被称为注意力汇聚(Attention Sink),意味着只要保留前面的一些token作为Key和Value(KV)状态,就可以在很大程度上恢复窗口注意力(Window Attention)的性能。
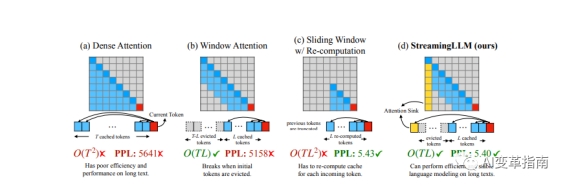
现有模型的长度外推能力有限
窗口注意力是一种只缓存最近的KV状态的方法,它可以节省大量的内存,但是当文本长度超过缓存大小时,它会失效。
StreamingLLM利用注意力汇聚的现象,提出了一种高效的框架,可以让任何基于Transformer的语言模型(LLM)处理无限长度的文本,而不需要任何微调或额外的训练。具体见文末论文。
StreamingLLM有两个主要的优点:
它可以让语言模型(LLM)处理比训练序列长度更长的文本,而不会出现性能下降或不稳定的问题。研究团队展示了StreamingLLM可以让Llama-2, MPT, Falcon和Pythia等流行的语言模型(LLM)稳定和高效地处理高达400万token2和更多 的文本。
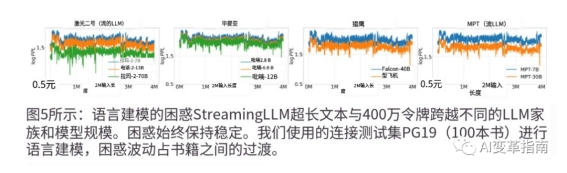
它可以显著提高语言模型(LLM)在串流应用中的效率,比如多轮对话、实时生成等。研究团队比较了StreamingLLM和滑动窗口重计算(Sliding Window Recomputation)这两种方法,在串流设置下,StreamingLLM比滑动窗口重计算快了22.2倍。
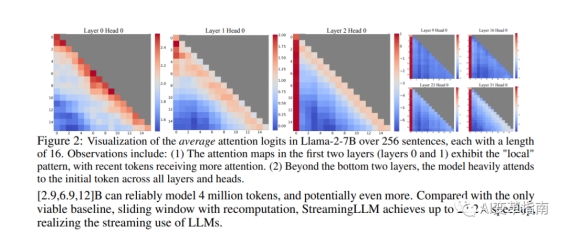
无限长对话的AI能带来哪些机会?
可以提高服务和营销的效率和质量,比如客服、咨询、推荐等。
可以创造出各种类型的文本,比如新闻、小说、诗歌、歌词、代码等。
可以记住个人喜好,记住几个月前的聊天内容,也就是说它能像人一样记住你!这就有很大的商机在里面!
论文地址:
https://browse.arxiv.org/pdf/2309.17453.pdf
代码地址:
https://github.com/mit-han-lab/streaming-llm
出自:https://mp.weixin.qq.com/s/tAE4ePfVFTjqlMbEnxh3dw