刚刚过去的 2023 年是大模型元年,在国产大模型数量狂飙突进的同时——已经超过 200 个,「套壳」一直是萦绕在大模型头上的舆论阴云。从年初到年末,从百度文心一言到零一万物,从字节跳动到谷歌 Gemini,各种「涉嫌套壳」的事件屡次冲上热搜,随后又被相关方解释澄清。非 AI 从业者,视套壳如洪水猛兽;真正的 AI 从业者,对套壳讳莫如深。但由于「套壳」本身并没有清晰、准确的定义,导致行业对套壳的理解也是一千个读者有一千个哈姆雷特。当我们在谈论套壳的时候,到底在谈论什么?抛开具体场景谈套壳都是在贴标签。为了厘清大模型套壳的逻辑,「甲子光年」访谈了一些AI从业者、投资人,结合 OpenAI、Meta 以及国内大模型相关技术论文,从一个大模型的「炼丹」过程入手,看看在哪些步骤、哪些环节,存在套壳的空间。2024 年或许是大模型大规模落地的元年,一些 AI Native 的应用将会陆续出现。在积极发展大模型应用生态之时,希望行业对于「套壳」的讨论能够抛开情绪,回归事实。大模型的统一「内核」为了更好地理解套壳,必须区别「外壳」与「内核」的区别。
今天,所有大模型的内核,都起源于 2017 年谷歌大脑团队(Google Brain,2023年 4 月与谷歌收购的 AI 公司 DeepMind 合并为 Google DeepMind )发布的Transformer 神经网络架构。Transformer 一经问世,逐步取代了过去的 RNN(循环神经网络)与 CNN(卷积神经网络),成为 NLP(自然语言处理)前沿研究的标准范式。在 Transformer 诞生的十年前,有一部好莱坞大片《变形金刚》在全球上映,这部电影的英文名字就叫「Transformers」。就像电影中能够灵活变身的变形金刚一样,作为神经网络架构的 Transformer 也可以通过改变架构组件与参数,衍生出不同的变体。Transformer 的原始架构包含两个核心组件——编码器(Encoder)与解码器(Decoder),编码器负责理解输入文本,解码器负责生成输出文本。在 Transformer 的原始架构上「魔改」衍生出三个变体架构——只采用编码器(Encoder-only),只采用解码器(Decoder-only),以及两者的混合体(Encoder-Decoder)。这三个变体架构分别有一个代表性模型——谷歌的 BERT ,OpenAI 的 GPT 系列模型,以及谷歌的 T5。今天,这三个模型名称通常也指代了其背后的模型架构名称(后文也以此指代)。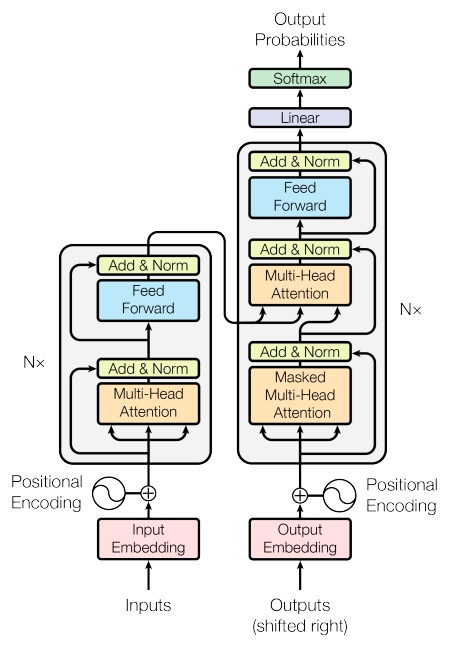 Transformer 的模型架构图,左侧为 Encoder,右侧为 Decoder。图片来自谷歌论文在 2020 年之前,NLP 的模型研究基本都是围绕算法展开,基于 BERT、T5 与 GPT 架构的模型百花齐放。这一时期模型参数较小,基本都在 10 亿以内量级。其中,谷歌 BERT 的表现独领风骚,基于 BERT 架构的模型一度在阅读理解的竞赛排行榜中屠榜。直到 2020 年,OpenAI 发布一篇论文,首次提出了 Scaling Laws(尺度定律),NLP 的研究才正式进入大模型时代——大模型基于「大算力、大参数、大数据」,模型性能就会像摩尔定律一样持续提升,直到「智能涌现」的时刻。在此期间,GPT 架构的性能表现逐渐超越 BERT 与 T5,成为大模型的主流选择。今天百亿参数以上的主流大模型中,除了谷歌最新发布的 Gemini 是基于 T5 架构,几乎清一色都是从 GPT 架构衍生而来。可以说,GPT 完成了一场大模型架构内核的大一统。
Transformer 的模型架构图,左侧为 Encoder,右侧为 Decoder。图片来自谷歌论文在 2020 年之前,NLP 的模型研究基本都是围绕算法展开,基于 BERT、T5 与 GPT 架构的模型百花齐放。这一时期模型参数较小,基本都在 10 亿以内量级。其中,谷歌 BERT 的表现独领风骚,基于 BERT 架构的模型一度在阅读理解的竞赛排行榜中屠榜。直到 2020 年,OpenAI 发布一篇论文,首次提出了 Scaling Laws(尺度定律),NLP 的研究才正式进入大模型时代——大模型基于「大算力、大参数、大数据」,模型性能就会像摩尔定律一样持续提升,直到「智能涌现」的时刻。在此期间,GPT 架构的性能表现逐渐超越 BERT 与 T5,成为大模型的主流选择。今天百亿参数以上的主流大模型中,除了谷歌最新发布的 Gemini 是基于 T5 架构,几乎清一色都是从 GPT 架构衍生而来。可以说,GPT 完成了一场大模型架构内核的大一统。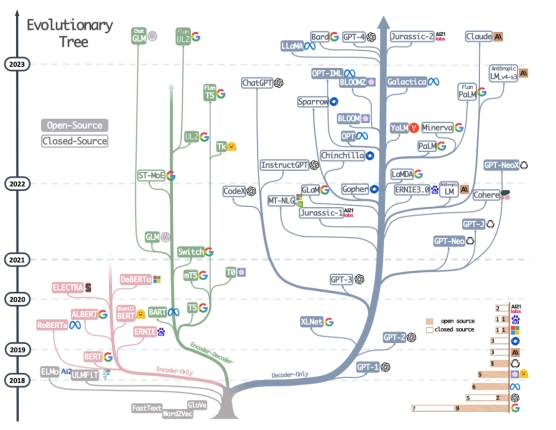 大模型进化树,其中 GPT 系列枝繁叶茂。图片来自Github,作者 Mooler0410从大模型的进化脉络来看,今天所有的模型都是在「套壳」 Transformer 以及其三个变体架构。当然,Transformer 也有「不愿套壳」的挑战者。比如,2023 年 12 月 5 日,两位分别来自卡内基梅隆大学与普林斯顿大学的教授,发布了一款名为「Mamba」(曼巴)的新架构,在语言建模性能媲美 Transformer 的同时,还解决了一些扩展性的局限。但这个新架构的具体表现,还需要时间的检验。模型架构选择只是第一步。百川智能创始人、CEO 王小川在一个月前的2023甲子引力年终盛典上将大模型训练比作「炒菜」,模型架构只是一个菜谱。要想得到一盘完整的菜,还需要烹饪,也就是大模型训练的过程;以及食材,也就是数据。大模型的烹饪过程可以粗略地分为预训练(Pre Train)与微调(Fine-Tune)两大阶段。预训练是大模型训练最核心的环节,通过把大量的文本信息压缩到模型中,就像一个学生寒窗苦读的过程,来让模型具备世界知识。OpenAI 创始人之一、特斯拉前 AI 总监安德烈·卡帕西(Andrej Karpathy)在 2023 年 5 月的微软 Build 大会上透露:「预训练就是在超级计算机中使数千个 GPU 以及可能进行数月时间来处理互联网规模数据集的地方,占据训练时间的99%。」在漫长的预训练之后会得到一个基座模型(Base Model),在基座模型的基础上加入特定行业的数据集做进一步的微调,就会得到一个微调模型(Fine-tuning Model),或者称为行业模型、垂直模型。微调通常分为两个步骤——SFT(有监督微调)+RLHF(人类反馈强化学习),其中 RLHF是 OpenAI 的创新设计,它决定了模型能够与人类意图与价值观对齐,是训练一个可靠的对话模型不可或缺的环节。预训练成本极高,因此每年或几个月才会做一次。OpenAI 训练 ChatGPT 大约花费了大约 1200 万美元,Meta 训练 Llama 65B 花费了 500 万美元。相比之下,微调成本较低,可能只需要短短几天甚至一天。正因如此,只有充足的算力、财力的大公司与资本支持的雄心勃勃的创业公司,才会涉足基座模型。「百模大战」中的国产大模型数量虽然多,但只有大约 10% 的模型是基座模型,90% 的模型是在开源模型基础上加入特定数据集做微调的行业模型、垂直模型。其中,应用最广的开源基座模型,目前就是 Meta 的 Llama 2。从大模型的训练过程来看,没有人会对架构选择——「套壳」 Transformer 有异议。但围绕架构之后的预训练,成为了一个套壳与否的隐秘角落。「原创派」与「模仿派」预训练是大模型最核心的环节,也是「套壳」与「自研」争议较多的环节。前面提到,模型架构只是大模型的菜谱——目前有 BERT、T5 与 GPT 三大菜谱,而每个菜谱上会有具体的菜名——预训练框架。按照预训练框架的菜谱炒菜,就是预训练的过程。一个可以肯定的事实是,所有的定位做基座模型的公司,都是从头开始投入真金白银做了完整的预训练,但菜谱的由来,却分成了两派。第一派,就是标准意义的「自研派」,从菜谱开始研究,自研了预训练框架。这一派的共同点就是布局较早,可以追溯到 2020 年之前,远远早于 ChatGPT 诞生而打响的大模型竞赛的发令枪。百度是其中一家。2019年,百度就发布了自研的预训练框架 ERNIE,也就是今天的文心大模型,今天已经更新到 ERNIE-4.0。值得一提的是,谷歌 BERT 与百度 ERNIE 名字取材于美国著名儿童节目《芝麻街》中的角色,两者是一对好友。
大模型进化树,其中 GPT 系列枝繁叶茂。图片来自Github,作者 Mooler0410从大模型的进化脉络来看,今天所有的模型都是在「套壳」 Transformer 以及其三个变体架构。当然,Transformer 也有「不愿套壳」的挑战者。比如,2023 年 12 月 5 日,两位分别来自卡内基梅隆大学与普林斯顿大学的教授,发布了一款名为「Mamba」(曼巴)的新架构,在语言建模性能媲美 Transformer 的同时,还解决了一些扩展性的局限。但这个新架构的具体表现,还需要时间的检验。模型架构选择只是第一步。百川智能创始人、CEO 王小川在一个月前的2023甲子引力年终盛典上将大模型训练比作「炒菜」,模型架构只是一个菜谱。要想得到一盘完整的菜,还需要烹饪,也就是大模型训练的过程;以及食材,也就是数据。大模型的烹饪过程可以粗略地分为预训练(Pre Train)与微调(Fine-Tune)两大阶段。预训练是大模型训练最核心的环节,通过把大量的文本信息压缩到模型中,就像一个学生寒窗苦读的过程,来让模型具备世界知识。OpenAI 创始人之一、特斯拉前 AI 总监安德烈·卡帕西(Andrej Karpathy)在 2023 年 5 月的微软 Build 大会上透露:「预训练就是在超级计算机中使数千个 GPU 以及可能进行数月时间来处理互联网规模数据集的地方,占据训练时间的99%。」在漫长的预训练之后会得到一个基座模型(Base Model),在基座模型的基础上加入特定行业的数据集做进一步的微调,就会得到一个微调模型(Fine-tuning Model),或者称为行业模型、垂直模型。微调通常分为两个步骤——SFT(有监督微调)+RLHF(人类反馈强化学习),其中 RLHF是 OpenAI 的创新设计,它决定了模型能够与人类意图与价值观对齐,是训练一个可靠的对话模型不可或缺的环节。预训练成本极高,因此每年或几个月才会做一次。OpenAI 训练 ChatGPT 大约花费了大约 1200 万美元,Meta 训练 Llama 65B 花费了 500 万美元。相比之下,微调成本较低,可能只需要短短几天甚至一天。正因如此,只有充足的算力、财力的大公司与资本支持的雄心勃勃的创业公司,才会涉足基座模型。「百模大战」中的国产大模型数量虽然多,但只有大约 10% 的模型是基座模型,90% 的模型是在开源模型基础上加入特定数据集做微调的行业模型、垂直模型。其中,应用最广的开源基座模型,目前就是 Meta 的 Llama 2。从大模型的训练过程来看,没有人会对架构选择——「套壳」 Transformer 有异议。但围绕架构之后的预训练,成为了一个套壳与否的隐秘角落。「原创派」与「模仿派」预训练是大模型最核心的环节,也是「套壳」与「自研」争议较多的环节。前面提到,模型架构只是大模型的菜谱——目前有 BERT、T5 与 GPT 三大菜谱,而每个菜谱上会有具体的菜名——预训练框架。按照预训练框架的菜谱炒菜,就是预训练的过程。一个可以肯定的事实是,所有的定位做基座模型的公司,都是从头开始投入真金白银做了完整的预训练,但菜谱的由来,却分成了两派。第一派,就是标准意义的「自研派」,从菜谱开始研究,自研了预训练框架。这一派的共同点就是布局较早,可以追溯到 2020 年之前,远远早于 ChatGPT 诞生而打响的大模型竞赛的发令枪。百度是其中一家。2019年,百度就发布了自研的预训练框架 ERNIE,也就是今天的文心大模型,今天已经更新到 ERNIE-4.0。值得一提的是,谷歌 BERT 与百度 ERNIE 名字取材于美国著名儿童节目《芝麻街》中的角色,两者是一对好友。 《芝麻街》中的 ERNIE 与 BERT,图片来自网络另一家早期自研预训练框架的大模型公司是智谱 AI 。智谱 AI 成立于 2019 年,并在 2020 年底开始自研预训练框架 GLM。GLM 与 谷歌 T5 相似,也是基于Encoder-Decoder 架构。2022 年 11 月,斯坦福大学大模型中心对全球 30 个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型。百度与智谱 AI 之外,还有一部分闭源大模型没有公开自己的技术细节,代表性公司为 Minimax、月之暗面等。有投资人对「甲子光年」表示,这几家也有自己的预训练框架,但无法准确核实。总的来说,国内基于自研预训练框架的大模型公司数量较少,大约只有 5 家左右。第二派大模型公司也从头开始做完整的预训练过程,但预训练框架是在开源框架——主要是 Llama 2 的基础上修改部分参数而来,可以称之为「模仿派」。对于开源社区而言,这是一套非常正常的做法,开源的意义就是公开自己的研究成果,促进技术的交流与共享,让开源社区内更多的研究者受益。Llama 2 也是站在过去开源模型的肩膀上一步步发展而来。比如,Llama 2 的模型架构中, Pre-normalization(预归一化)受 GPT-3 启发,SwiGLU(激活函数)受 PaLM 的启发,Rotary Embeddings(位置编码)受 GPT-Neo 的启发。其他模型也经常魔改这几个参数来做预训练。零一万物创始人李开复表示:「全球大模型架构一路从 GPT2 --> Gopher --> Chinchilla --> Llama 2-> Yi,行业逐渐形成大模型的通用标准,就像做一个手机 app 开发者不会去自创 iOS、Android 以外的全新基础架构。」值得强调的是,模仿 Llama 2 并非代表没有核心竞争力。零一万物在文章中提到,模型训练过程好比做一道菜,架构只是决定了做菜的原材料和大致步骤,要训练出好的模型,还需要更好的「原材料」(数据)和对每一个步骤细节的把控(训练方法和具体参数)。「原创派」与「模仿派」,到底孰优孰劣?对于这件事,需要分开讨论。一句话总结来说,原创派赌的是未来,模仿派赌的是现在。一位投资人对「甲子光年」表示:「Llama 2 并非一个完美架构,还有较大的局限性,有机会做到 GPT-3.5 的水平,但是如何做到 GPT-4 的水平,目前还没有看到办法。如果底层技术架构一直受制于 Llama 2,想要超越 GPT,怕是机会很小。」这位投资人所在的投资机构投资了多家大模型公司。在做投资决策时,自研预训练框架与否,也是他们的衡量标准之一。一位 AI 公司的研发人员告诉「甲子光年」,自研预训练模型的优势在于扩展能力比较强,「如果基于开源,都是有版本限制的,比如 Llama 2 只有 7B、13B、70B 三个版本,再多就没有了,想再搞大规模一点,搞不了」。不过,理想很丰满,但原创预训练架构的优势,目前还存在于理论阶段。短期来看,无论是自研还是模仿 Llama 2,两者都处在 GPT-3.5 的水平,性能差距不大。另一位 AI 投资人对「甲子光年」表示:「现阶段,开源框架基本已经达到了 GPT-3.5 的水平,所以,如果选择从头自研一个与开源框架水平一样的预训练框架,不如直接选择模仿 Llama 2 效率更高、稳定性更可靠,除非有能力自研一个达到GPT-4、甚至下一代 GPT-5 能力的模型。这里的能力指的是有技术能力,且有足够的资金持续投入,因为目前预期是 GPT-5 的训练可能需要 3-5 万张 H100,成本在 10-20 亿美金。」现阶段,大家比拼的并不是预训练框架的性能,而是工程化的能力,业内一般称为 AI Infra——AI 基础设施。昆仑万维 AI Infra 负责人成诚将大模型发展分为了三个阶段:2020 年之前的算法研究阶段,2020~2023 年的数据为王阶段,以及 2023 年的 AI Infra 阶段。他预测,未来大模型算法研究必然朝着 Infra 的方向去探索:稀疏化(Sparse Attention、 Sparse GEMM / MoE) 将会是 2024 年学术界与工业界的主战场。薅 GPT 的数据羊毛在预训练完成之后,来到了微调阶段。实际上,这一阶段才是大部分「套壳」大模型翻车的原因,它与数据集的质量有直接关系。数据的使用贯穿在大模型预训练、SFT、RLHF 的每个阶段。在预训练阶段,数据「在多而不在精」。由于预训练使用互联网公开数据,不同大模型最终所获得的知识储备是趋近的。明显的差异点发生在微调阶段,数据「在精而不在多」。比如,Llama 2 的研究人员在做微调时发现大部分第三方的 SFT 数据集多样性与质量都不足,因此他们自己构建了 27540 个高质量标注数据集,可以显著提高 SFT 的效果。但不是所有的公司都像 Meta 一样财大气粗。有没有更高效的获取高质量数据集的方式?有,通过「偷」 ChatGPT 等对话模型的数据。这里的偷并非指盗窃,而是直接利用 ChatGPT 或 GPT-4 等对话模型生成的数据来做微调。这些合成数据,既保证了数据的多样性,又是经过 OpenAI 对齐后的高质量数据。美国电商初创公司 Rebuy 的 AI 总监、深度学习博士 Cameron R. Wolfe 将这种大模型研究方式称为「模仿学习」(Imitation Learning),并表示模仿学习明显受到「知识蒸馏」(Knowledge Distillation)的启发。知识蒸馏是一种机器学习中标准的模型压缩方法,它将复杂的模型看做「教师模型」,把简单的模型看做「学生模型」,通过老师教学生的方式将知识迁移过去。
《芝麻街》中的 ERNIE 与 BERT,图片来自网络另一家早期自研预训练框架的大模型公司是智谱 AI 。智谱 AI 成立于 2019 年,并在 2020 年底开始自研预训练框架 GLM。GLM 与 谷歌 T5 相似,也是基于Encoder-Decoder 架构。2022 年 11 月,斯坦福大学大模型中心对全球 30 个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型。百度与智谱 AI 之外,还有一部分闭源大模型没有公开自己的技术细节,代表性公司为 Minimax、月之暗面等。有投资人对「甲子光年」表示,这几家也有自己的预训练框架,但无法准确核实。总的来说,国内基于自研预训练框架的大模型公司数量较少,大约只有 5 家左右。第二派大模型公司也从头开始做完整的预训练过程,但预训练框架是在开源框架——主要是 Llama 2 的基础上修改部分参数而来,可以称之为「模仿派」。对于开源社区而言,这是一套非常正常的做法,开源的意义就是公开自己的研究成果,促进技术的交流与共享,让开源社区内更多的研究者受益。Llama 2 也是站在过去开源模型的肩膀上一步步发展而来。比如,Llama 2 的模型架构中, Pre-normalization(预归一化)受 GPT-3 启发,SwiGLU(激活函数)受 PaLM 的启发,Rotary Embeddings(位置编码)受 GPT-Neo 的启发。其他模型也经常魔改这几个参数来做预训练。零一万物创始人李开复表示:「全球大模型架构一路从 GPT2 --> Gopher --> Chinchilla --> Llama 2-> Yi,行业逐渐形成大模型的通用标准,就像做一个手机 app 开发者不会去自创 iOS、Android 以外的全新基础架构。」值得强调的是,模仿 Llama 2 并非代表没有核心竞争力。零一万物在文章中提到,模型训练过程好比做一道菜,架构只是决定了做菜的原材料和大致步骤,要训练出好的模型,还需要更好的「原材料」(数据)和对每一个步骤细节的把控(训练方法和具体参数)。「原创派」与「模仿派」,到底孰优孰劣?对于这件事,需要分开讨论。一句话总结来说,原创派赌的是未来,模仿派赌的是现在。一位投资人对「甲子光年」表示:「Llama 2 并非一个完美架构,还有较大的局限性,有机会做到 GPT-3.5 的水平,但是如何做到 GPT-4 的水平,目前还没有看到办法。如果底层技术架构一直受制于 Llama 2,想要超越 GPT,怕是机会很小。」这位投资人所在的投资机构投资了多家大模型公司。在做投资决策时,自研预训练框架与否,也是他们的衡量标准之一。一位 AI 公司的研发人员告诉「甲子光年」,自研预训练模型的优势在于扩展能力比较强,「如果基于开源,都是有版本限制的,比如 Llama 2 只有 7B、13B、70B 三个版本,再多就没有了,想再搞大规模一点,搞不了」。不过,理想很丰满,但原创预训练架构的优势,目前还存在于理论阶段。短期来看,无论是自研还是模仿 Llama 2,两者都处在 GPT-3.5 的水平,性能差距不大。另一位 AI 投资人对「甲子光年」表示:「现阶段,开源框架基本已经达到了 GPT-3.5 的水平,所以,如果选择从头自研一个与开源框架水平一样的预训练框架,不如直接选择模仿 Llama 2 效率更高、稳定性更可靠,除非有能力自研一个达到GPT-4、甚至下一代 GPT-5 能力的模型。这里的能力指的是有技术能力,且有足够的资金持续投入,因为目前预期是 GPT-5 的训练可能需要 3-5 万张 H100,成本在 10-20 亿美金。」现阶段,大家比拼的并不是预训练框架的性能,而是工程化的能力,业内一般称为 AI Infra——AI 基础设施。昆仑万维 AI Infra 负责人成诚将大模型发展分为了三个阶段:2020 年之前的算法研究阶段,2020~2023 年的数据为王阶段,以及 2023 年的 AI Infra 阶段。他预测,未来大模型算法研究必然朝着 Infra 的方向去探索:稀疏化(Sparse Attention、 Sparse GEMM / MoE) 将会是 2024 年学术界与工业界的主战场。薅 GPT 的数据羊毛在预训练完成之后,来到了微调阶段。实际上,这一阶段才是大部分「套壳」大模型翻车的原因,它与数据集的质量有直接关系。数据的使用贯穿在大模型预训练、SFT、RLHF 的每个阶段。在预训练阶段,数据「在多而不在精」。由于预训练使用互联网公开数据,不同大模型最终所获得的知识储备是趋近的。明显的差异点发生在微调阶段,数据「在精而不在多」。比如,Llama 2 的研究人员在做微调时发现大部分第三方的 SFT 数据集多样性与质量都不足,因此他们自己构建了 27540 个高质量标注数据集,可以显著提高 SFT 的效果。但不是所有的公司都像 Meta 一样财大气粗。有没有更高效的获取高质量数据集的方式?有,通过「偷」 ChatGPT 等对话模型的数据。这里的偷并非指盗窃,而是直接利用 ChatGPT 或 GPT-4 等对话模型生成的数据来做微调。这些合成数据,既保证了数据的多样性,又是经过 OpenAI 对齐后的高质量数据。美国电商初创公司 Rebuy 的 AI 总监、深度学习博士 Cameron R. Wolfe 将这种大模型研究方式称为「模仿学习」(Imitation Learning),并表示模仿学习明显受到「知识蒸馏」(Knowledge Distillation)的启发。知识蒸馏是一种机器学习中标准的模型压缩方法,它将复杂的模型看做「教师模型」,把简单的模型看做「学生模型」,通过老师教学生的方式将知识迁移过去。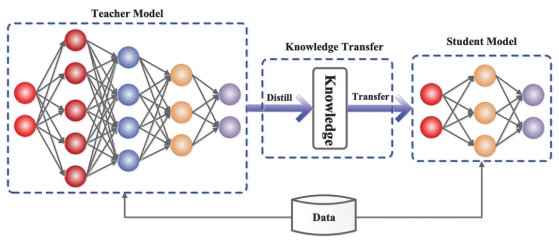 模仿学习的原理,图片来自 Cameron R. Wolfe的博客 在 Meta 发布了 Llama 1 系列模型后,迅速在开源社区催生了各类模仿模型的诞生,比较知名的包括由斯坦福大学、加州大学伯克利分校等高校机构推出的 Alpaca、Vicuna、Koala,以及 NomicAI 推出的 GPT4ALL,这些模型都用到了 ChatGPT 的对话数据来做微调。值得一提的是,OpenAI 在服务条款中明确禁止使用 ChatGPT 生成的数据开发与 OpenAI 竞争的模型。所以,上述模仿模型不能用于商业用途。但事实上,各类商业模型都在通过「偷」数据的方式来走微调的捷径,这已经是公开的秘密,并且不限国别。2023 年 12 月,字节跳动、谷歌 Gemini 的「疑似套壳」事件正是来源于此。根据字节跳动的回应,2023 年初部分工程师曾将 OpenAI 的 API 服务应用于实验性的模型研究,但并未上线,后来已经禁止该行为。从现实角度来说,字节跳动「只是犯了一个天下所有模型都会犯的错误」。一位做 NLP 研究的科学家告诉「甲子光年」:「OpenAI 可能预感到字节跳动可以花钱堆一个模型出来,所以提前打压一下。但实际上,这对于限制字节跳动训练大模型没有任何效果,纯粹就是想『辱骂』一下。」谷歌 Gemini 也是类似情况。由于缺乏高质量的中文数据集,谷歌极有可能通过文心一言获得大量的中文对话数据来做 Gemini 的「老师」。但是,或许因为追赶 OpenAI 心切,数据清洗、自我认知对齐等工作没有做到位,导致 Gemini 把老师文心一言当成了自己。一位国产大模型公司的算法工程师向「甲子光年」吐槽道:「大家相互薅羊毛,要用,但要小心用,一不小心就尴尬了。」把「壳」做厚才是竞争力在预训练阶段模仿 Llama 2、在微调阶段「偷」ChatGPT 的数据,是两类产生「套壳」争议的主要场景,也是大模型训练过程中决定模型能力的关键场景。如果把范围扩展到模型的推理与应用,「套壳」的场景还会更多。前语雀设计师,现 AI 助手 Monica 联合创始人 Suki 在即刻上分享了「套壳」的四重进阶:一阶:直接引用 OpenAI 接口,ChatGPT 回答什么,套壳产品回答什么。卷UI、形态、成本。
模仿学习的原理,图片来自 Cameron R. Wolfe的博客 在 Meta 发布了 Llama 1 系列模型后,迅速在开源社区催生了各类模仿模型的诞生,比较知名的包括由斯坦福大学、加州大学伯克利分校等高校机构推出的 Alpaca、Vicuna、Koala,以及 NomicAI 推出的 GPT4ALL,这些模型都用到了 ChatGPT 的对话数据来做微调。值得一提的是,OpenAI 在服务条款中明确禁止使用 ChatGPT 生成的数据开发与 OpenAI 竞争的模型。所以,上述模仿模型不能用于商业用途。但事实上,各类商业模型都在通过「偷」数据的方式来走微调的捷径,这已经是公开的秘密,并且不限国别。2023 年 12 月,字节跳动、谷歌 Gemini 的「疑似套壳」事件正是来源于此。根据字节跳动的回应,2023 年初部分工程师曾将 OpenAI 的 API 服务应用于实验性的模型研究,但并未上线,后来已经禁止该行为。从现实角度来说,字节跳动「只是犯了一个天下所有模型都会犯的错误」。一位做 NLP 研究的科学家告诉「甲子光年」:「OpenAI 可能预感到字节跳动可以花钱堆一个模型出来,所以提前打压一下。但实际上,这对于限制字节跳动训练大模型没有任何效果,纯粹就是想『辱骂』一下。」谷歌 Gemini 也是类似情况。由于缺乏高质量的中文数据集,谷歌极有可能通过文心一言获得大量的中文对话数据来做 Gemini 的「老师」。但是,或许因为追赶 OpenAI 心切,数据清洗、自我认知对齐等工作没有做到位,导致 Gemini 把老师文心一言当成了自己。一位国产大模型公司的算法工程师向「甲子光年」吐槽道:「大家相互薅羊毛,要用,但要小心用,一不小心就尴尬了。」把「壳」做厚才是竞争力在预训练阶段模仿 Llama 2、在微调阶段「偷」ChatGPT 的数据,是两类产生「套壳」争议的主要场景,也是大模型训练过程中决定模型能力的关键场景。如果把范围扩展到模型的推理与应用,「套壳」的场景还会更多。前语雀设计师,现 AI 助手 Monica 联合创始人 Suki 在即刻上分享了「套壳」的四重进阶:一阶:直接引用 OpenAI 接口,ChatGPT 回答什么,套壳产品回答什么。卷UI、形态、成本。
二阶:构建 Prompt。大模型可以类比为研发,Prompt 可以类比为需求文档,需求文档越清晰,研发实现得越精准。套壳产品可以积累自己的优质 Prompt,卷 Prompt 质量高,卷 Prompt 分发。
三阶:Embedding 特定数据集。把特定数据集进行向量化,在部分场景构建自己的向量数据库,以达到可以回答 ChatGPT 回答不出来的问题。比如垂直领域、私人数据等。Embedding 可以将段落文本编码成固定维度的向量,从而便于进行语义相似度的比较,相较于 Prompt 可以进行更精准的检索从而获得更专业的回答。
四阶:微调 Fine-Tuning。使用优质的问答数据进行二次训练,让模型更匹配对特定任务的理解。相较于 Embedding 和 Prompt 两者需要消耗大量的 Token,微调是训练大模型本身,消耗的 token 更少,响应速度也更快。
如果把模仿 Llama2 架构做预训练也算进去,可以看做第五阶。这五重进阶,基本囊括了大模型「套壳」的每一个场景。值得一提的是,上述行为能否被称为「套壳」,在业内也说法不一。算法工程师刘聪对「甲子光年」表示:「我觉得,只有一种情况算套壳——直接做 API 的买卖,比如说一些免费使用大模型的网站,用来收集数据、倒卖数据。其他情况其实都不算。在 to B 行业,要做行业化的解决方案,只会套壳不可能做到;就算是 to C,如果有自己对产品的理解,也不能说是套壳。难道做大模型应用的都是套壳吗?」「套壳这个词,贬义太严重。」刘聪说道。脱离具体的场景谈论「套壳」,都是贴标签的行为。当行业褪去了对套壳的污名化理解,把不同进阶的套壳行为看做一类正常的商业行为,才能更加理性客观地分析大模型的优劣。只是,大模型厂商在宣传的时候,应当更谨慎地使用「自研」,以及具体解释自研的内容。否则,只会加剧理解的困惑。「套壳」有竞争力吗?Suki 认为,一个 AI 应用产品如果停留在做一阶和二阶,注定是个门槛极低的产品,没有任何壁垒。而什么场景,何时以及如何使用三阶和四阶的能力,是个关键性的问题。一位算法工程师告诉「甲子光年」,大模型真正关键的问题在于业务的成本结构和护城河,而不是套壳与否。把成本降低、把「壳」做厚,自然就产生了竞争力。
出自:https://mp.weixin.qq.com/s/W74T0wfPDmKbRR3kkgLNkA