揭秘Baichuan 3超越GPT-4的中文实力!文心一言、GLM 4.0也甘拜下风?全方位对比测试大揭秘!
AI界的焦点再度聚集!1月29日,百川智能推出了超千亿参数的大语言模型Baichuan 3,瞬间在科技圈点燃了热情。不同于其他模型,Baichuan 3在各项评测中都有惊艳表现,甚至在中文任务上超越了GPT-4,成为了新的领头羊。
Baichuan 3不仅在CMMLU、GAOKAO和AGI-Eval等通用能力评测中脱颖而出,更在数学和代码专项评测中展现了强大的实力。MATH、HumanEval和MBPP的优异成绩,都证明了它在自然语言处理和代码生成上的高超水平。
更让人眼前一亮的是,Baichuan 3在逻辑推理和专业性极强的MCMLE、MedExam、CMExam等医疗评测中,也凭借出色的中文效果超越了GPT-4。这得益于它突破性的“迭代式强化学习”技术,让语义理解和生成能力更上一层楼。这也让Baichuan 3在诗词创作等创意领域领先其他大模型。
与此同时,通过逻辑推理、代码解释、工具调用、AI写诗、文件上传提炼大纲等一系列示例测试,我们可以直观感受到Baichuan 3与其他大模型如文心一言(4.0)、GLM 4.0、GPT-4和Claude-2的不同之处。Baichuan 3在中文任务上的卓越表现,让它在众多大模型中独树一帜。
那么,Baichuan 3究竟有何独特之处?它如何在AI竞争中脱颖而出?接下来的日子里,我们将深入挖掘Baichuan 3的技术细节和独特魅力,带大家一探究竟。而在未来的AI赛道上,Baichuan 3又能否持续领跑?让我们拭目以待!
Baichuan 3显威:中文任务全面超越GPT-4
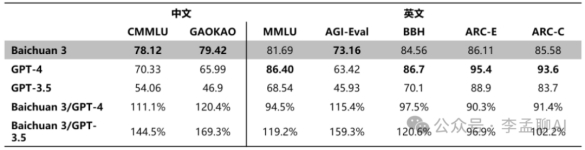
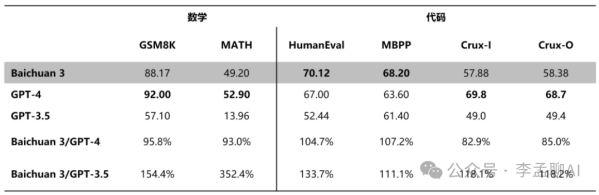
在CMMLU、GAOKAO等中文权威评测中,Baichuan 3不仅展现了出色的语言理解能力,还在生成任务上大放异彩,这得益于其针对中文语境的深度优化。与此同时,在MT-Bench、IFEval等对齐榜单评测中,它也超越了GPT-3.5、Claude等知名大模型,展现了全面的能力。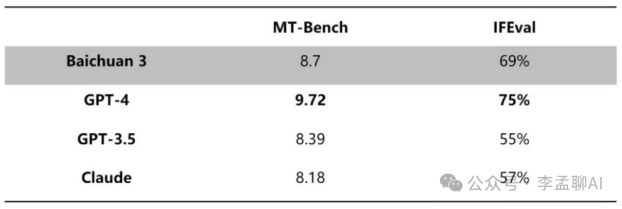
不同于百亿级别的模型,超千亿参数的Baichuan 3在训练过程中面临了更多挑战。但百川智能通过一系列技术创新,成功解决了高质量数据获取、训练稳定性和训练效率等关键问题。
在数据方面,百川智能采用了基于因果采样的动态训练数据选择方案,这意味着模型能够在训练过程中自我优化数据选择,而非依赖人工先验。这一创新极大提升了数据的质量和训练效果。
为了确保训练的稳定性,百川智能提出了“重要度保持”的渐进式初始化方法,有效避免了梯度爆炸和模型不收敛等问题。同时,他们还通过优化监控方案和引入“有效秩”方法,实现了对训练问题的快速定位和解决。
在训练效率上,百川智能同样不遗余力。他们针对超千亿参数模型的并行训练进行了深度优化,通过一系列技术手段降低了通信时间的比重,解决了显存占用不均的问题,并显著提升了训练框架的性能。
Baichuan 3的成功不仅仅是一个技术突破,更是中文大模型发展的一个重要里程碑。未来,我们期待看到更多如Baichuan 3般强大而智能的中文大模型在各个领域大放异彩。而这一切,都离不开百川智能团队在背后的辛勤付出和持续创新。
那么,Baichuan 3在中文任务上的优势得益于什么能力?
强化学习新突破:Baichuan 3大模型引领精准创作时代
在AI技术的长河中,每一次技术的革新都像是掀起一层新的浪潮。语义理解和文本生成,作为这浪潮中的两大支柱,正经历着一场由强化学习引领的变革。
业界巨头如OpenAI、Google等已率先尝试,通过RLHF和RLAIF技术强化模型的对齐能力。但百川智能在这基础上更进一步,他们自研的高效PPO训练框架和创新的数据生成方式,让强化学习在大模型上发挥出了前所未有的潜力。
而这其中最为引人注目的,当属Baichuan 3大模型。通过“迭代式强化学习”,它不仅在语义理解上达到了新高度,更在创作能力上实现了质的飞跃。
那么,这场由强化学习引领的变革,究竟能在实际应用中带来怎样的惊喜?接下来,我们将通过实测对比,一探文心一言(4.0)、GLM 4.0、GPT-4、Baichuan 3以及Claude-2这五大模型的能力差异。
在此之前,不妨先思考一个问题:在如此激烈的竞争中,Baichuan 3是否能凭借其强化学习的优势,脱颖而出,成为新的领头羊?悬念即将揭晓,让我们一同期待实测对比的结果吧!
实测对比:文心一言(4.0)、GLM 4.0、GPT-4、Baichuan 3、claude-2的能力大比拼
我亲自体验了几款大模型的默认功能,没有使用任何魔法提示词来修饰。为什么要这样做呢?因为我想看看,在没有任何额外帮助的情况下,这些大模型到底能展现出怎样的实力。
逻辑推理
Baichuan 3 GLM 4.0
GLM 4.0 文心一言 4.0
文心一言 4.0
GPT-4

claude-2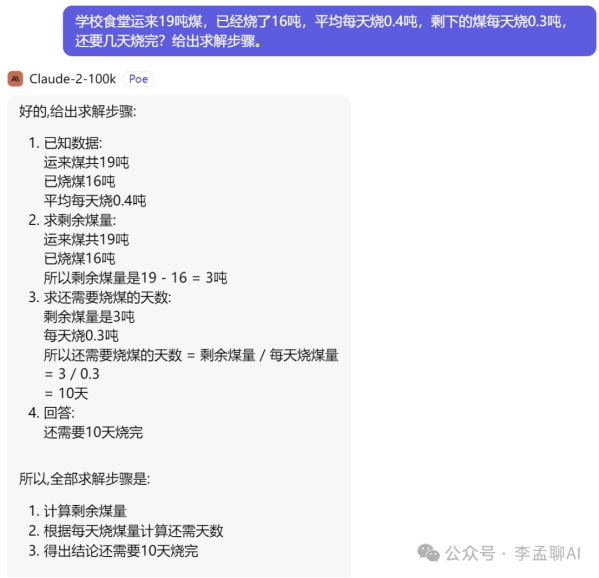
比对文心一言(4.0)、GLM 4.0、GPT-4、Baichuan 3、claude-2逻辑推理能力不相伯仲,没有求值错误。
代码解释
由于Baichuan 3和claude-2无法直接画图形,我是生成完代码本地执行。
Baichuan 3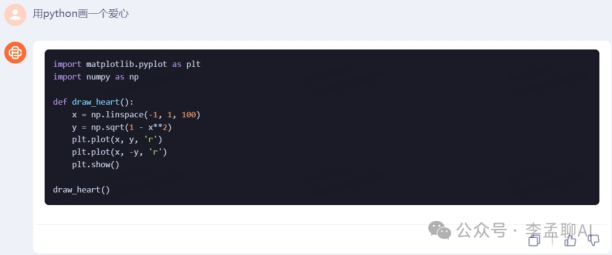
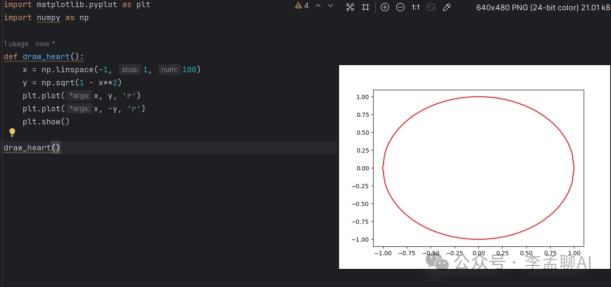
GLM 4.0
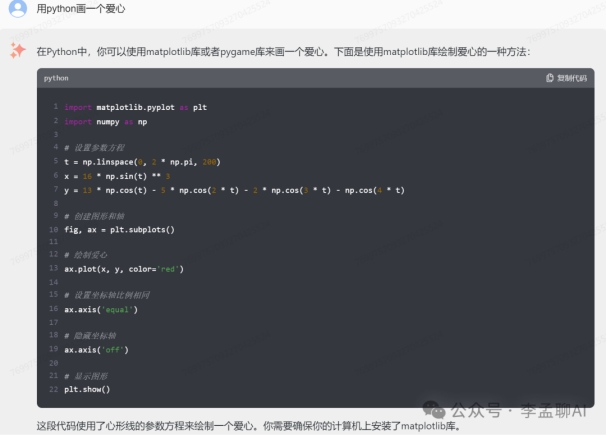

claude-2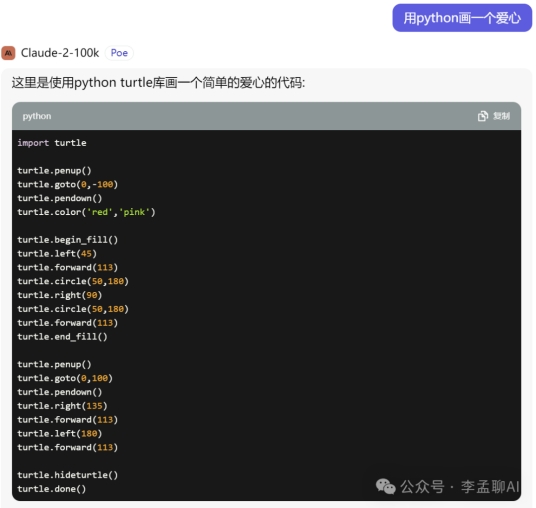

GPT-4

Baichuan 3和claude-2 生成代码效果不理想,GLM和GPT代码生成能力强。GPT效果最佳!
工具调用
claude-2 无法调用国内工具,自动放弃!
文心一言 4.0 GLM 4.0
GLM 4.0
 Baichuan 3
Baichuan 3
不支持外部工具调用。 GPT-4
GPT-4
除了Baichuan 3 和 claude-2 无法调用工具,其他大模型调用天气插件能力相近。
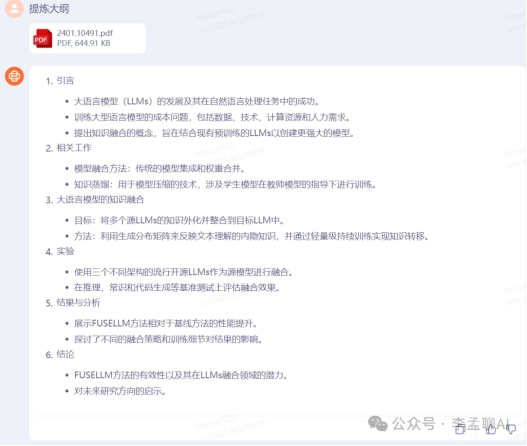
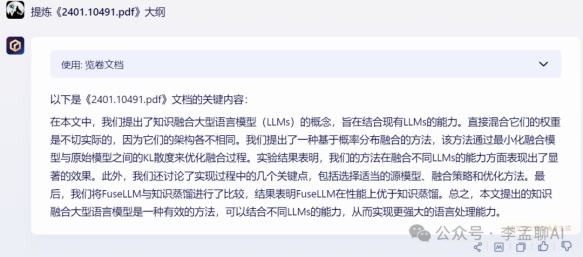
提炼上传文件大纲
我上传AI模型融合 FuseLLM 论文让大模型提炼大纲,对论文感兴趣,请看这篇文章。
claude-2 无法支持上传文件。
Baichuan3
GPT-4
文心一言 4.0
 GLM-4
GLM-4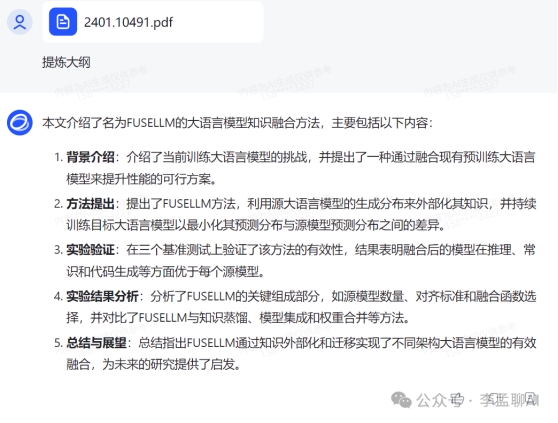
Baichuan 3 和 GLM-4 对于上传文件理解非常具体和全面,把大纲小标题都提炼出来,而文心一言 4.0 和GPT-4需要再次用提示词才能把信息更加具体化。claude-2 无法支持上传文件。
写诗
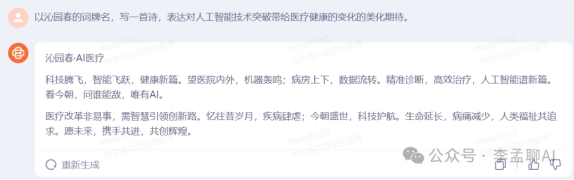
以沁园春的词牌名,写一首诗,表达对人工智能技术突破带给医疗健康的变化的美化期待。
文心一言 4.0
 以沁园春的词牌名,写一首诗,表达对人工智能技术突破带给医疗健康的变化的美化期待。
以沁园春的词牌名,写一首诗,表达对人工智能技术突破带给医疗健康的变化的美化期待。
GPT-4
Baichuan 3
 在这里插入图片描述
在这里插入图片描述
claude-2
 在这里插入图片描述
在这里插入图片描述
GLM-4
这五种大模型,GPT写的最雅俗共赏,有例证和情绪,把古代先贤搬出有很强对比。Baichuan 3写诗学术感太强。GLM-4 、文心一言 4.0、claude-2 写诗表达差不多现实例子然后输出情绪。
郭德纲说过“文无第一 ,武无第二” ,交给市场,谁的用户多,谁厉害 !
AI大模型谁领风骚?Baichuan 3、GPT-4、文心一言等实力对比
首先说说新晋选手Baichuan 3。这款模型在中文处理上表现出色,堪称国内一流水平。虽然不支持插件,但其中文理解能力绝对让人眼前一亮。
接着是大家熟知的GPT-4。这位老将依旧宝刀未老,在逻辑推理、代码解释、工具调用等方面都展现出了强大的综合实力。不仅如此,GPT-4还能写诗、上传文件提炼大纲,真是十八般武艺样样精通。
文心一言(4.0)也不甘示弱,其中文理解能力同样出色,还支持丰富插件。虽然提炼大纲能力稍逊于Baichuan 3和GLM 4.0,但其在其他方面的表现也足够亮眼。
GLM 4.0同样以中文理解能力见长,可惜也不支持插件。不过,在批量处理任务时,GLM 4.0的高效性还是让人印象深刻的。
最后要提的是Claude-2。这位选手可谓是量大管饱,支持高达100k个Token(约75,000个词)的生成。虽然生成内容有时细节不够完美,但在批量生产场景下绝对是一把好手。
这些大模型各有千秋,究竟谁能在AI技术的浪潮中脱颖而出?让我们拭目以待!同时,也期待未来有更多优秀的大模型问世,为我们的生活带来更多便利和惊喜。
出自:https://mp.weixin.qq.com/s/RbzcYJ8swcFhbP949XZMeA