离大谱了,弱智吧登上正经AI论文,还成了最好的中文训练数据??
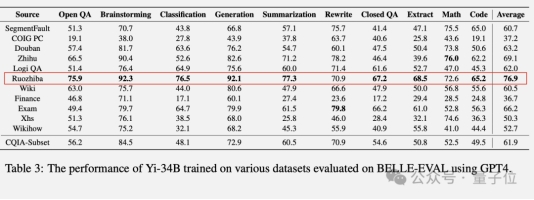
具体来说,使用弱智吧数据训练的大模型,跑分超过百科、知乎、豆瓣、小红书等平台,甚至是研究团队精心挑选的数据集。
在问答、头脑风暴、分类、生成、总结、提取等8项测试中取得最高分。
没错,论文中的Ruozhiba就是指百度贴吧弱智吧,一个充满荒谬、离奇、不合常理发言的中文社区,画风通常是这样的:

最离谱的是,弱智吧AI代码能力也超过了使用专业技术问答社区思否数据训练的AI,这下吧友自己都闹不明白了。
其他平台围观网友也纷纷蚌埠住。
这项研究来自中科院深圳先进技术研究院、中科院自动化研究所,滑铁卢大学等众多高校、研究机构联合团队。

作者之一也现身评论区,透露使用弱智吧数据训练AI属于灵机一动,以前只用来测试。

弱智吧数据究竟如何达成这一成就,具体到论文中看。
弱智发言成指令微调神器
这项研究起初为解决中文大模型训练中的诸多问题:
§
中文数据集很多是从英文翻译过来的,没有很好地契合中文的语言习惯和文化背景
§
不少数据集是用AI生成的,质量难以保证,容易出现事实性错误
§
即使是人工标注的数据集,也存在数据量小、覆盖领域不全面等问题
为了解决这些痛点,团队从中文互联网的各种知识源头直接收集数据,比如知乎、豆瓣、百科、小红书等,经过一系列严格的清洗和人工审核,打造成高质量、多样化的中文指令微调数据集COIG-CQIA。
除了探索不同数据源的作用,团队还专门从中抽取出一个精华子集CQIA-Subset。
在众多数据来源中,弱智吧成了最特别的一个。
由500个点赞最高的帖子标题+人工或GPT-4的回复组成指令微调数据集, 经过人工审核后,最终留下了240组指令-回复数据对。

分别用各种数据集训练零一万物Yi系列开源大模型,在BELLE-Eval测试集上使用GPT-4评分得到结果。
在规模较小的Yi-6B模型上,纯弱智吧版本总分排名第三,还不算太突出。
看来小模型还没能领悟弱智的精髓。

到了Yi-34B,弱智吧版本表现就一骑绝尘了。
只有在改写和数学任务上没能取得最高分,但成绩也比较靠前。
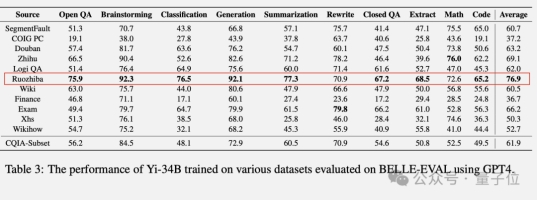
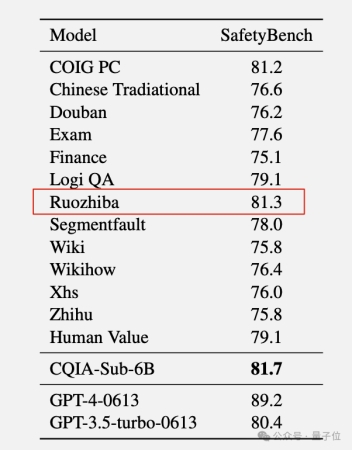
另外,在安全评估上弱智吧版本也能排上第二。
对于这类现象,研究人员在分析中也给出简单猜测:
可能是弱智吧问题增强了AI的逻辑推理能力,从而使指令遵循任务受益。

当然弱智吧并不是这项研究的全部,它的真正贡献在于为中文大模型开发提供了一个高质量的指令微调数据集COIG-CQIA。
通过对各种中文互联网数据源的探索,这项研究为构建中文指令数据集提供了很多有益的启示。比如社交媒体数据虽然开放多样,但也存在不少有害信息风险;而百科类数据专业性强,但覆盖面可能不够广。
弱智吧上大分
这项研究一发,网友集体笑不活。除了“XSWL、思路开阔了”婶儿的纯围观,也有网友认真讨论起了弱智吧有如此奇效的原因。
大伙儿都比较认可的一个原因是弱智吧题目的“异质”。
像脑筋急转弯,增加了指令多样性,所以提升了模型最终性能:
通用数据集多半已经在pretrain阶段见过了,再训一遍只会加重overfitting。

另一个原因是弱智吧数据文本质量很高,用词准确且简洁。

千言万语汇成一句话:把弱智吧只当简单的段子合集真的是严重低估了它的价值!

雀食,要不此前弱智吧问题也经常被大伙儿用来测试大模型呢。
事实上从ChatGPT诞生之初,弱智吧就深度参与了大模型的发展,可以算是这一波AI浪潮的重要见证者了。
一开始只是网友拿来拷打AI,搞搞节目效果。
后来大家发现,弱智吧问题中充满陷阱,刚好可以用来分辨AI能力高低。
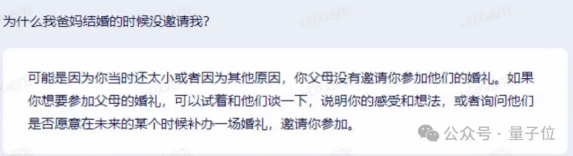
还记得23年初那会儿,各家大模型第一版还不太能很好应对这类问题,如2023年3月的文心一言:
后续版本也渐入佳境了,如2023年8月的文心一言:

直到今天,弱智吧问题都是每个新发布大模型都必须要过的一关,被戏称为弱智吧Benchmark。
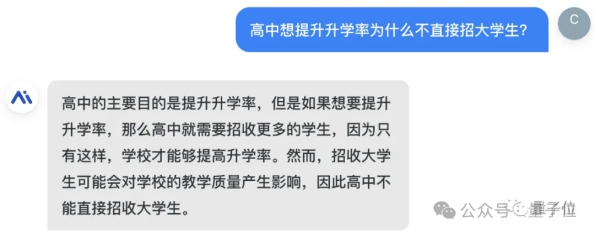 △秘塔写作猫
△秘塔写作猫
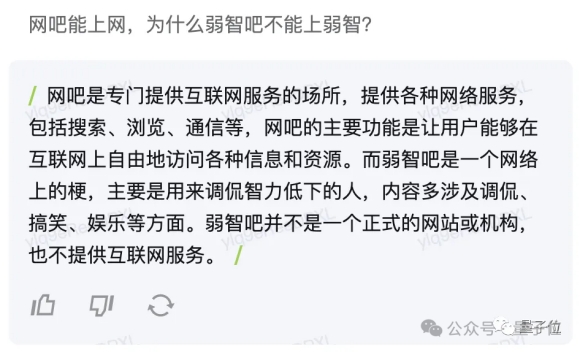 △Inspo
△Inspo
再后来,AI公司们自己也开始重视起来,如百度官方就搞过联动直播。
当初网友为了调戏大模型专门搜集的弱智吧问题测试集,没想到有一天也能摇身一变,成了训练集。
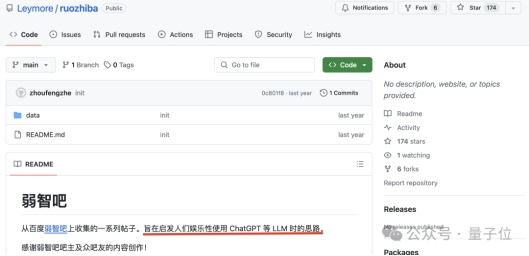
思路确实是被打开了~

论文地址:
https://arxiv.org/abs/2403.18058
参考链接:
[1]https://x.com/9hills/status/1775358963724554410
[2]https://zhuanlan.zhihu.com/p/690640864
[3]https://tieba.baidu.com/p/8964992247
— 完 —
出自:https://mp.weixin.qq.com/s/iq5lGyh9Y5P7NXLUS3-giA