从科技圈最新动态来看,最近AI代码生成概念实火。
可是,小伙伴们有没有感觉,AI刷程序题比较亮眼,到了企业真实开发场景中,总感觉欠点火候?
恰在此时,一位低调的资深大玩家aiXcoder出手了,放出大招:
它就是全新开源的代码大模型——aiXcoder-7B Base版,一个专门适合在企业软件开发场景中部署的代码大模型。
等等,一个“仅”70亿参数的代码大模型,能展现出什么样的AI编程水平?
先看看在HumanEval、MBPP和MultiPL-E三大主流评测集上的表现,它平均得分居然超过340亿参数的Codellama。
要知道,后者来自Meta、基于Llama2,可是开源界最先进的AI编程大模型之作。
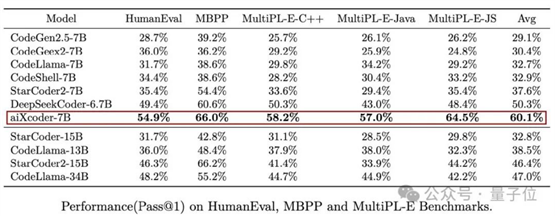
没完,这个模型不仅打败了一众开源大模型、成为百亿级代码大模型中最强,还有特别的优势:
一改传统的“刷题式”代码生成,它专门针对企业级软件项目,在真实开发场景下效果最好——代码生成补全能力、和跨文件能力经过测试,都是“杠杠滴”(No.1)。
言外之意,aiXcoder-7B不玩“虚”的,可以hold得住企业真实业务场景。
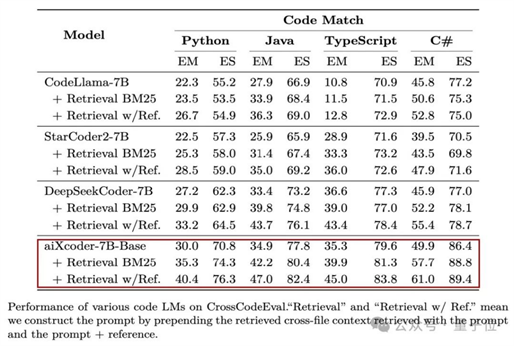
例如在贴近真实开发场景的评测集CrossCodeEval上,aiXcoder-7B一举拿下了同级别模型的最好效果:
百亿级参数最强代码大模型
先来看大模型。
此次发布并开源的是aiXcoder-7B Base版(相应Instruct版后续也将发布),它让人最感到惊喜的就是:
除了代码生成能力SOTA——不仅拿下主流测评集中的各种算法题,更重要的,在与企业真实开发场景一致的多文件复杂代码场景中,aiXcoder-7B在同量级参数模型中表现更加亮眼!
要知道,AI编程工具当前最实用的能力就是生成和补全,包括直接生成完整的方法块、条件判断块、循环处理块、异常捕捉块等多种情况。
而在真实开发场景中,我们特别需要它对整个开发项目中的各种关联文件进行理解,然后再生成。
测试显示,aiXcoder-7B Base版结合单文件上下文的代码补全能力超越StarCoder2、CodeLlama等一众模型,在Python、JS和Java语言上综合得分最高。
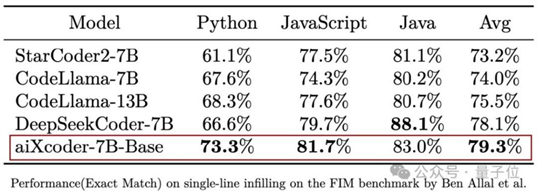
这是在SantaCoder测评集上的结果。还不过瘾,aiXcoder团队还提出了一个更大的测评代码生成补全数据集(16000多条来自真实开发场景的数据),做了进一步测评,效果更明显。
今天,该测评集也与模型一同开源,欢迎大家前来挑战~
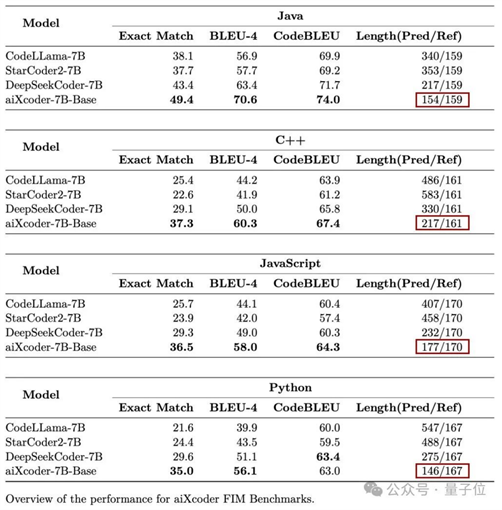
值得一提的是,团队还特别向我们开了一个“彩蛋”,那就是aiXcoder-7B Base版在补全时更倾向于用较短的代码来完成任务,有一种天生的“简洁美”。
其好处不言而喻:程序员更容易理解、Bug也更好检查。
易私有化部署、个性化定制
这么好的代码大模型,为什么要开源呢?
aiXcoder团队表示,帮助更多的开发者减轻工作负担,是他们的愿望!
这次,之所以开源7B的项目级代码大模型,主打就是“方便企业开发者使用”。
可以用三个“易”来总结它的特点:
首先, 易部署。
代码数据,都是企业私有的核心知识产权。因此,私有化部署和学习是不可避免的,而且,通常企业的部署资源是又是有限的。
aiXcoder-7B
Base版只有7B参数规模,十分轻便,易于部署,进而还有成本低、性能好的优点。
第二点,易定制。
很多企业都有自己的软件开发框架和API的库,与其关联的业务逻辑、代码架构规范都因地制宜,十分个性化。同时,这些内容又都有私密性。
必须得让大模型学会这些企业代码资产,通过进行有效个性化训练,才能真正为企业所用。
aiXcoder-7B
Base版就具有这样易定制的特性。
再者,易组合。
aiXcoder团队透露 ,未来提供企业服务时,可以让多个7B模型形成MoE架构,组合成为一套解决方案来完成企业定制化服务。
不同的企业,都可以得到符合自身个性化需求的MoE版代码大模型解决方案。
据了解,aiXcoder-7B Base版走开源路线,后续将聚焦B端市场,推出企业版本。
通过这种方式,aiXcoder通过持续为企业级用户提供精准、高效、连续的软件开发服务,帮助他们不断提高项目的开发效率和代码质量。

例如,正在进行数智化转型的某行业头部券商就采用了aiXcoder的大模型解决方案,在本地环境私有化部署代码大模型,且采用了模型的灵活调整方式,使智能开发系统与使用团队规模保持同步。
这种部署方式既确保了既有算力可支持,避免了因硬件门槛过高而带来的挑战;又能满足企业日常的编码需求。
现有落地数据反馈显示,结合该企业自身领域知识进行个性化训练后,在业务逻辑代码上,代码生成占比,较之前提升2倍。

看完了成绩,模型实际效果究竟怎么样?接下来就来几个demo给大家感受一下。
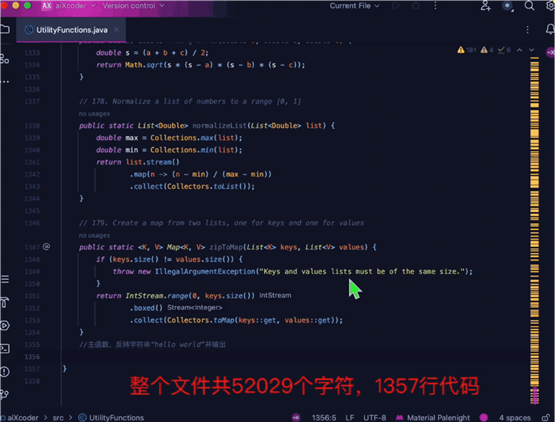
首先,aiXcoder-7B Base版能理解更多、更复杂的代码上下文信息,进行代码生成和补全:模型预训练支持的上下文长度为32k,推理阶段扩展则可达256k。
如下图所示,当我们用多个工具函数拼成了1500多行的代码,在文件末端注释要模型接入时,它可以准确识别到文件顶部的相关函数,结合该函数信息补全相关方法。
其次,在企业开发场景中,更重要的是跨文件分析的能力,它可以从多个代码文件中自动识别并提取所需。
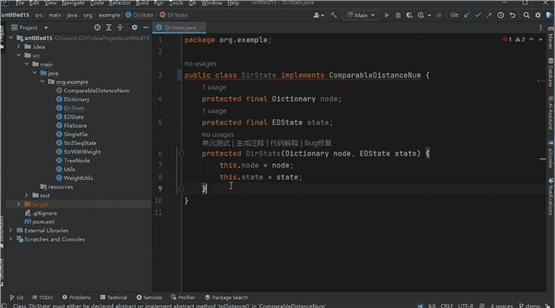
如下图所示,我们需要在树结构上应用动态规划来实现编辑距离搜索,让模型补全树结构上目录节点的动态规划状态类。
模型准确识别到了编辑距离的计算与另一个文件中滚动数组内部取最小值的计算之间的关系,从而结合非当前的两个文件给出了正确的预测结果。
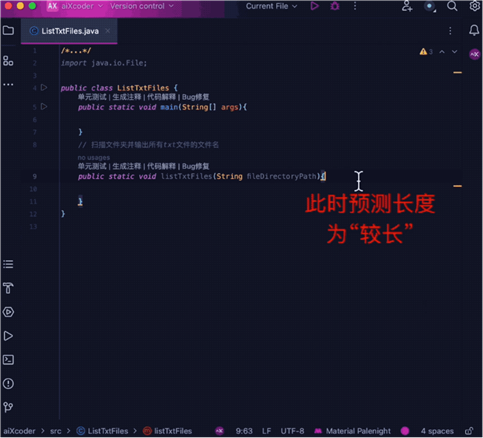
以上都还没完,aiXcoder-7B Base版的补全还是相当智能化的。
例如当用户的采纳情况发生调整时,它会根据当下的采纳情况自动调整补全长度。
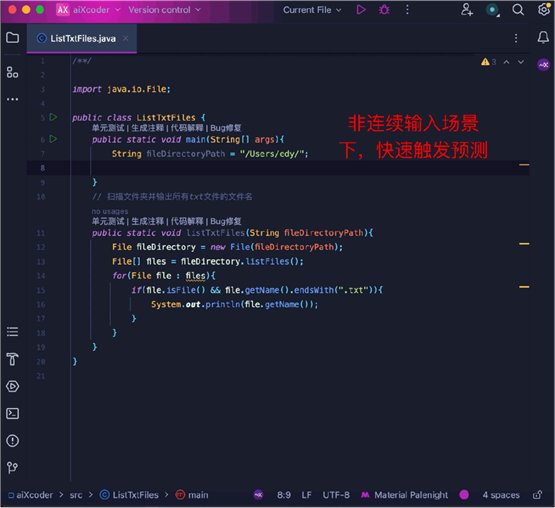
同时,作为一个补全代码专家,它还能根据用户输入的流畅性(即停顿时间)来判断用户当前是否需要补全,并不随意触发功能打断咱的工作状态。
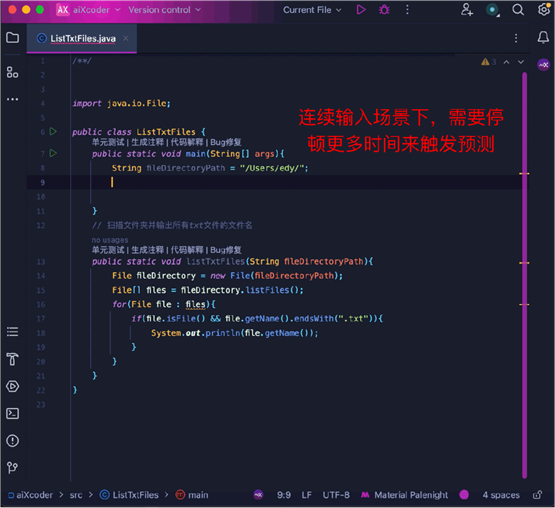
不得不说:真香啊。
而广大程序员们真正需要的,正是aiXcoder这样不仅懂通用代码,还能懂“我们企业”代码的AI编程工具。
那么,如此接地气的模型,究竟是如何炼成的?
团队介绍,该模型属于全自研,首先是训练数据:
一共包括1.2T Unique Tokens,在7B参数级模型中,训练数据量算是非常大的了。
不光“量胜”,团队也在这些数据上取得了“质胜”:他们耗费大量时间针对数十种主流语言做了语法分析过滤,以及静态分析排除掉了163种Bug和197种缺陷。
其次是针对性的训练方法,团队专门针对真实环境中的项目级代码进行了代码结构化语义训练,充分保证模型效果。
最后就是在训练过程中一开始就充分考虑了多文件的处理问题,通过结合聚类、代码Calling Graph等方式构建了多文件之间的相互注意力关系。
最终,更适用于真实开发场景的aiXcoder-7B Base版得以诞生。
aiXcoder背后的团队
再扒扒这个模型背后的玩家,我们发现来历也不简单:
首先,aiXcoder团队由北京大学软件工程研究所孵化,从2013年起开始搞代码生成,国际上最早的基于深度学习的代码生成论文就出自于他们;
其次,十年来,团队在NeurIPS、ACL、IJCAI、ICSE、FSE、ASE等顶会上发表相关论文100余篇,多篇论文被国际学者认为是“首创成果”并被广泛引用,多次获ACM杰出论文奖。
可谓要实力有实力,要成绩也有成绩。

2017年,aiXcoder最开始的雏形——aiXcoder1.0发布,提供代码自动补全与搜索功能。
2021年4月,团队推出完全自主知识产权的十亿级参数代码大模型aiXcoder L版,支持代码补全和自然语言推荐。这也是国内⾸个基于“⼤模型”的智能编程商⽤产品。
而后,团队持续攻坚,2022年6月再次推出了国内首个支持方法级代码生成的百亿级参数量模型aiXcoder XL版,同样具有完全自主知识产权。
2023年7月,aiXcoder团队推出聚焦企业适配的aiXcoder Europa,具有代码自动补全、代码自动生成、代码缺陷检测与修复、单元测试自动生成等功能。
据了解,aiXcoder Europa可根据企业数据安全和算力要求,为企业提供私有化部署和个性化训练服务,有效降低代码大模型的应用成本,提升研发效率。
直到今日,aiXcoder-7B Base版诞生。
在科技的璀璨星河中,每一次技术的突破都如同新星的诞生,照亮了未来的无限可能。
随着代码大模型的能力日益增强,它们在解决复杂编程问题上的卓越表现,不仅在提高软件开发的效率和质量上发挥着重要作用,在推动编程自动化的浪潮中扮演着关键角色,更激发了程序员们的创新潜能,让他们能够将更多的精力投入到探索和创造中。
换句话说,aiXcoder-7B这款前沿的代码大模型,不仅加速了软件开发自动化的进程,更在重塑技术行业的生态,引领着未来发展的趋势:
加快实现软件开发自动化。
这既是行业大势所趋,更是发展的必然选择。
荣幸的是,我们正站在这个转折点面前,见证着这一趋势的兴起和实现。
aiXcoder开源链接:
https://github.com/aixcoder-plugin/aiXcoder-7B
https://gitee.com/aixcoder-model/aixcoder-7b
https://www.gitlink.org.cn/aixcoder/aixcoder-7b-model
— 完 —
出自:https://mp.weixin.qq.com/s/YujpEG5XyAClLoxOH3yH4Q