最近想做一些中文大模型的微调实验,于是从祖国的文化瑰宝:中医入手,想让大模型学一下《本草纲目》,看下有没有什么火花出来。
说干就干,下载下来文本格式的《本草纲目》,然后做下预处理。
最近想做一些中文大模型的微调实验,于是从祖国的文化瑰宝:中医入手,想让大模型学一下《本草纲目》,看下有没有什么火花出来。

说干就干,下载下来文本格式的《本草纲目》,然后做下预处理。
比如,原文是李时珍的《本草纲目》,格式是这样的:

观察数据后,我们发现,本草纲目里都是一个症状对应一个药方,很容易找到规律。
因此,只要把其中以数字(1,2,3等)序号里的文本摘出来,处理成JSON格式,然后把它们变成一个问-答 对的形式,模仿病人和医生的对话,就可以放到大模型训练了。
第一步我们做数据清洗,功能很简单,就是找出数字开头的行,同时,数字1开头的行有可能有一些特殊的格式,可能要加“主治”这两个字。
代码逻辑这么简单,我就不写了,让大模型帮我写:)
一、三个大模型的生成代码体验
1、ChatGPT3.5:
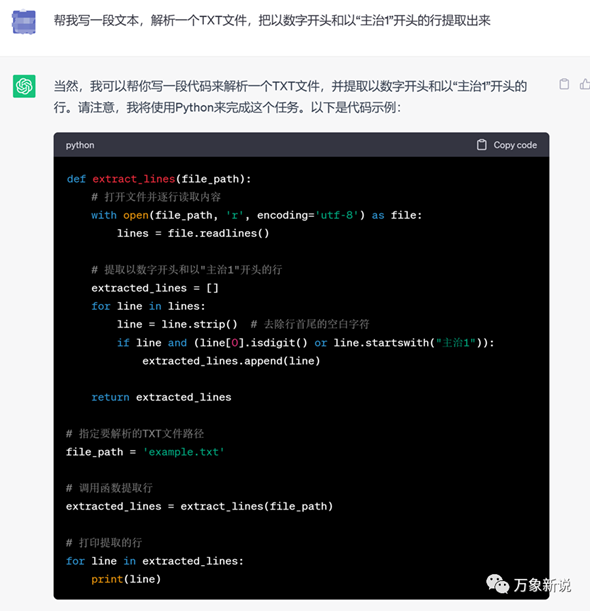
试了下,OK,运行成功,找到了关键的行。
二、文心一言
试了下,这个代码给的跟我的认知有点不符,它是用的中文名字做变量!!我不确定这个功能可不可以,于是测试了一下,可以!感谢文心一言!,学到了!

运行也成功了,赞!!
三、本地模型:百川-13B Chat
最后试下我们本地的大模型,百川-13B Chat,这里需要说明下,为了本地加载,我做了8-bit量化,可能会影响性能:
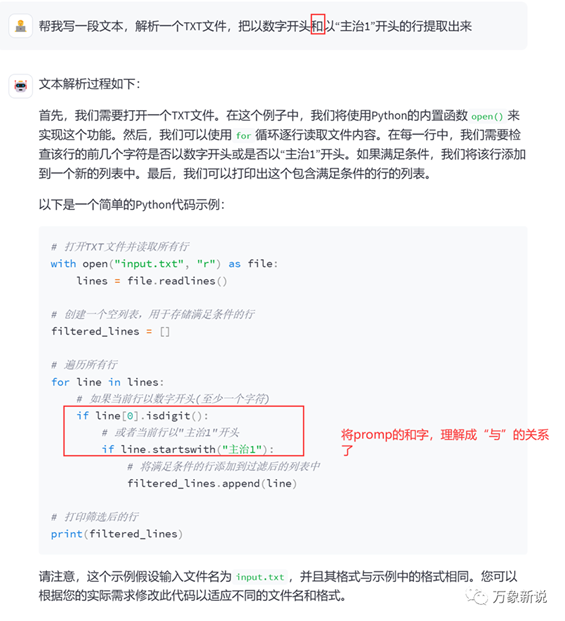
出现了一个问题,就是把prompt里的“和”字理解成了“与”的关系,经过进一步提示后,改对了,输出了正确的代码:

也成功了,赞!
小结一下:这三个模型都能帮我们完成一些简单的文本预处理工作,可能要把问题描述清楚后,效果会更好
二、生成最终的训练JSON数据体验
下面,用处理好的文本生成类似对话的JSON格式吧,先看下它们的one-shot learning能力怎么样:
直接看百川-13B chat的效果吧
没有问题!
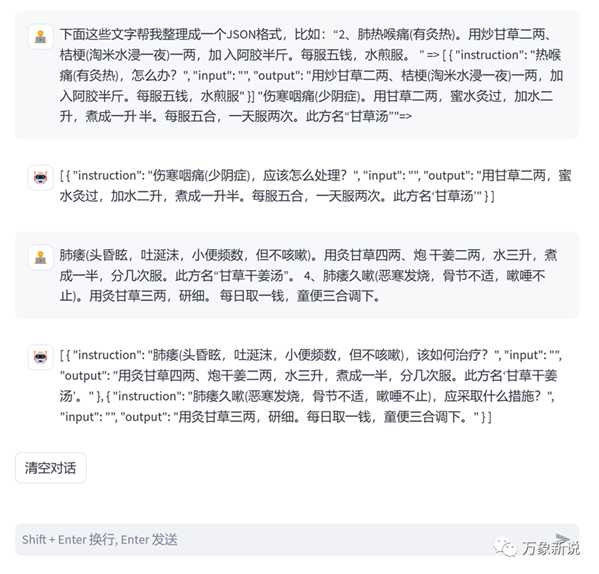
但这个用大模型有点杀鸡用牛刀了,直接生成一段代码处理就好了,我这回直接问了ChatGPT,不用说,经过一番调教,给出了可用的代码:
用它稍加改动,生成了本次训练所用的数据集合,总共2000条数据:
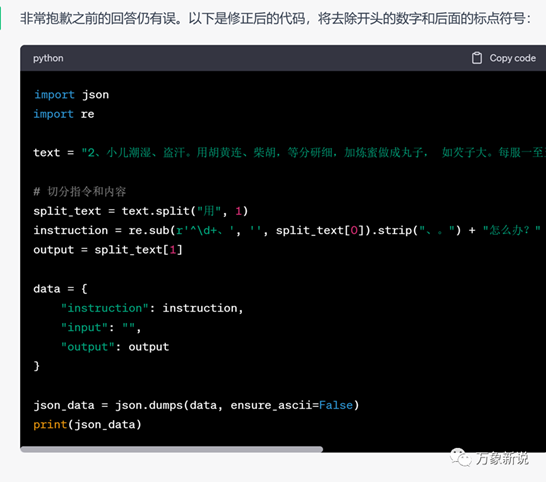
这里留一个彩蛋,看下红框框住的某种不足为人知的病,李时珍先生给的治疗方案是什么。

出自:https://mp.weixin.qq.com/s/ebVyKQAqqVVtwzU3dI3wVQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip