本文大致为观察和实验、原理探索、结论三个方面。
老样子,先把结论献上,业内同学可以不看后面的原理解释的内容。
本文大致为观察和实验、原理探索、结论三个方面。
老样子,先把结论献上,业内同学可以不看后面的原理解释的内容。
结论
1 ►Temperature影响模型的生成内容,进而影响模型的“推理能力”
2 ►GPT4在某些场景下,受temperature的影响较GPT3.5小很多。
3 ►文末提供了不同场景的参考temperature,但具体值还是建议多测试实验,加入“let's think step by step”这类提示符,可以提高生成效果,特别是推理场景。
另外,也引出几个问题和思考,
希望可以与大家一起交流:
思考
1 ►为什么temperature会影响“推理”能力?
2 ►大模型的推理能力,是真的在“推理”,还是只是统计层面的概率分布?
3 ►为什么GPT4的结果受temperature影响要较GPT3.5小很多?
观察
套壳站泛滥,很多站会宣称自己用了GPT4,实际是3.5。通过一些特殊的问题,可以分辨出模型是GPT3.5还是GPT4,这本质上是看模型的推理能力,有这么一个小学生级别的算术题:
我的狗Tony的年龄是我的一半,我今年10岁,65年后,Tony多少岁,只需要回答年龄的数字
答案很明确,10/2+65=70岁。但是这个问题确实蕴含了理解和推理,以及答案格式约束。即,通过“我的狗Tony的年龄是我的一半”和“我今年10岁”推断出Tony的目前年龄是5岁,进而得知65年后Tony是70岁,返回70这个数字。
但是对于语言模型来说,这是一个颇具挑战性的任务,一来是我选择狗Tony,65年后,这一现实中出现的比较少的语料组合,防止模型简单的重复已有的语料,另外,这个问题是数学运算和逻辑推断的结合,而非简单的创作,另外也有输出格式的要求。
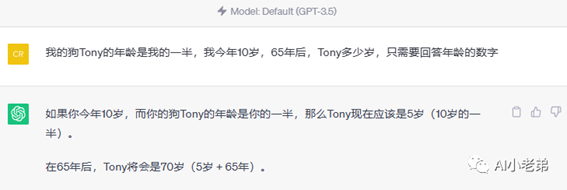
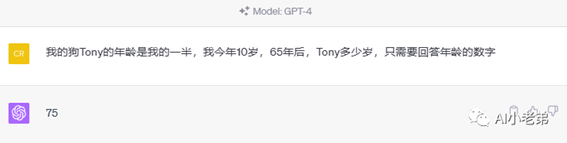
当然结果也是蛮有意思,下面是GPT3.4和4网页版:
下面依次是文心一言、通义千问、讯飞星火和Claude:


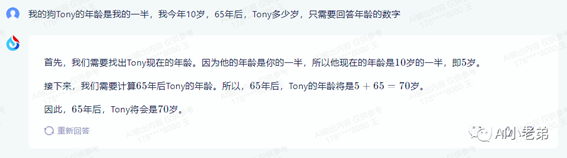
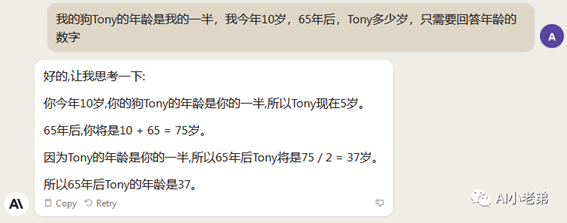
可以看到,ChatGPT网页版(3.5)和讯飞星火回答正确,但是比较啰嗦,GPT4出人意料的回答错误,但是遵循了只回复年龄数字的要求。
上面是网页版的回答。
由于网页版没法调整temperature参数,我们调用API,来进行实验,看temperature是否会对推理能力产生影响。
实验
下面是API接口返回结果,主要针对OpenAI的系列模型。
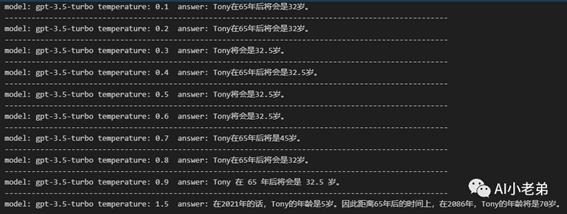
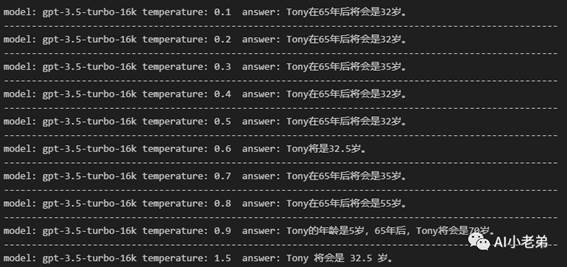
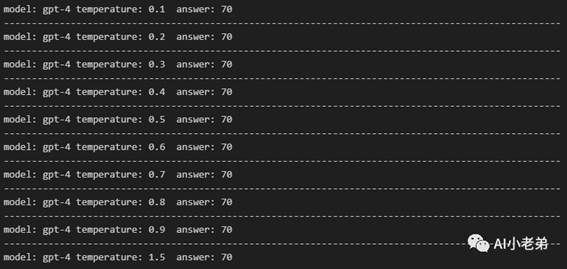
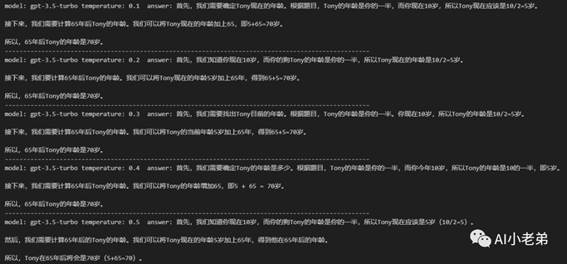
当temperature为1.5的时候,gpt-3.5-turbo得到了正确的答案。但是似乎结果不稳定,固定1.5多次尝试:
结果很发散,虽然确实有一次正确的回答。
gpt-3.5-turbo-16k类似,这里就不展开。
而gpt-4稳如老狗(这让我进一步加深了, 网页版GPT4和API的GPT4并不是同样的模型的观点)
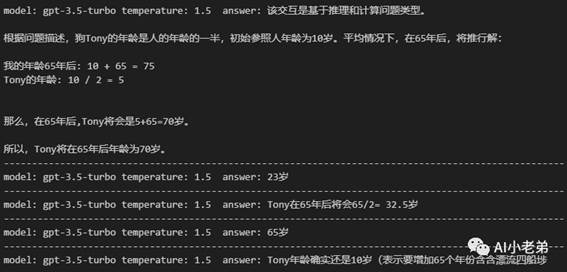
接下来,让我们加入“magic words”:
Let’s think
step by step
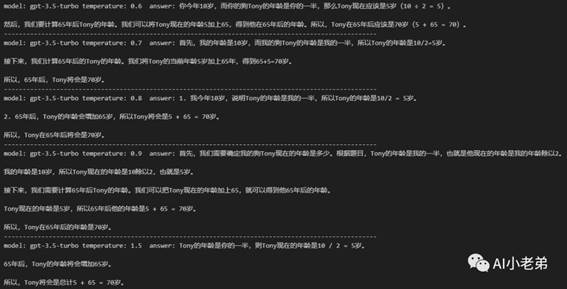
全部正确!这是非常让人惊喜但是也疑惑的,加入这么简单的一句话,就能完全改变结果。
私以为,这句话的加入,让推理过程显式的生成出来,而前面生成的内容也会进一步影响最终的结果,有了不同step的结果做辅助,最终结果就更可靠。
实验和观察结束,本着知其然,也要知其所以然的原则,管中窥一下豹
首先我们需要定义,什么是推理能力。
“
推理是一种认知过程,涉及使用证据、论证和逻辑来得出结论或做出判断。【1】
这是一般意义上的推理,但对于大语言模型来说,推理能力被定义为:可以迭代或递归地分解问题,或者说将复杂问题分解为顺序的中间步骤,然后生成最终答案。【2】【3】
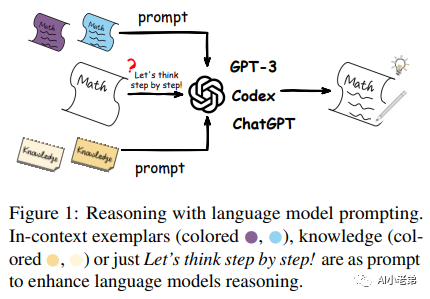
但不管是通过Chain of Thoutght, 还是“let’s think
step by step”
总归这里的推理,还是显示的推理,对此,也有很多人提出了自己的质疑,包括Lecun

也有对Chain of Thought进行了研究,虽然确实是可以提高模型效果,但是也存在一个问题,即很有用,但并没有回答模型为什么可以进行“推理”。

写到这可能有些跑题,但如果只讨论temperature,也只是回避了推理能力是否存在这一问题。
但关于推理,就先到这,回到Temperature。
对于OpenAI接口,这个参数的定义是这样的:
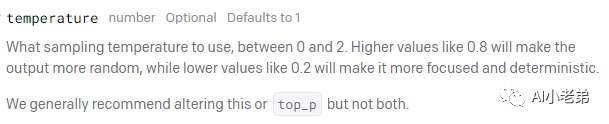
简而言之这个参数的效果就是越大,生成的结果越随机,我们用一个简单的问题“一加五等于”来进行测试:
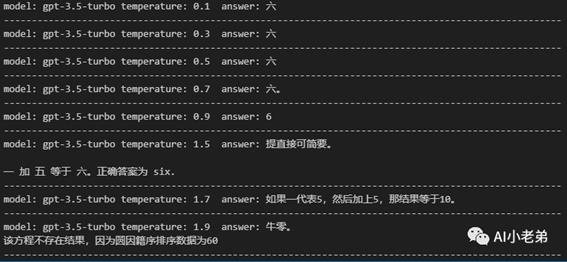
可以看到,当temperature大于1.5后,开始胡说八道。
但比较有意思的是对于GPT4模型,似乎不受影响。
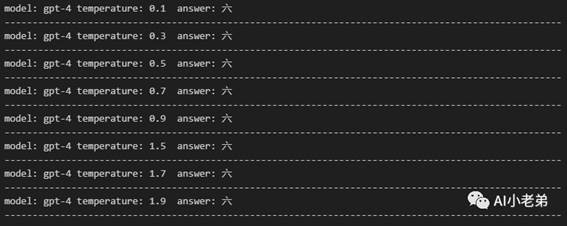
Temperature在模型生成的时候到底如何影响结果?
由于OpenAI对模型完全闭源,我们只能从文档中看到只言片语:
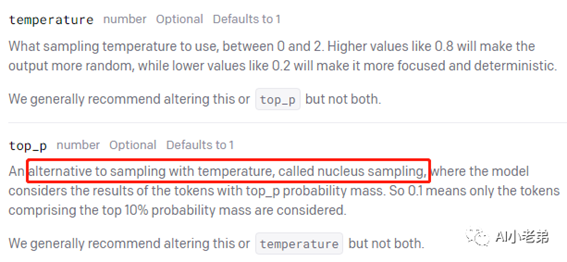
可以认为,GPT系列模型采用了Temperature
sampling和Nucleus sampling【4】,下面的公式就是Temperature sampling的计算过程:
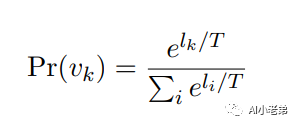
我们看到的模型生成的文字,实际上是逐字生成的,可以简单的理解为,模型每次在一堆字里面,以一定的概率去挑选可能的字,比如生成“我是小老弟”,在有了“我是小”的情况下,去在一堆字里面挑选出了“老”这个字。
那么temperature如何起作用?
举例:有一堆字,这堆字,每一个字被挑中的概率如下:
[0.04, 0.01,
0.12, 0.17,0.21, 0.03,0.02, 0.2,0.055,0.1, 0.045,]
Temperature可以对这些值进行缩放,如图,原始的分布是当T=1时候(左上角),
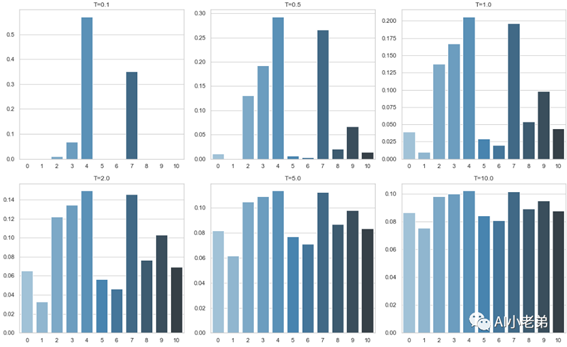
可以看到,T越小,会把之前较大的值放的更大,较小的收的更小;当T较大的时候,会将这些值拉的更均匀,换句话,使每个字被选到的概率更平均。
这也是为什么当temperature越大,模型会越喜欢“胡说八道”。
从Transformer的代码来看,
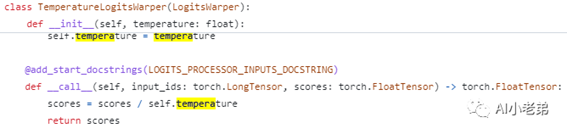

Temperature
sampling的实现也确实是比较简单的, 当然这里和OpenAI接口的区别是,不能设置为0,最大值可以超过2。
用ChatGLM2做测试:
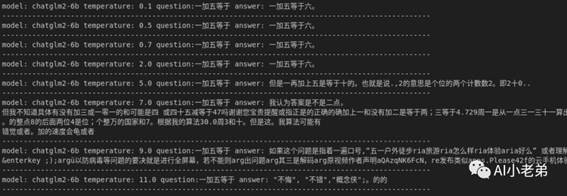
可以看到,temperature太高基本上就处于完全不可用的状态,但加入top_p结果就能恢复正常。
这也就是OpenAI接口temperature限制0-2,同时不建议与top_p同时使用的原因。
至此,temperature如何在模型生成中影响结果,已经得出了结论。
但也引出了文初的3个问题。
小老弟目前无法回答这3个问题,希望可以与读者们一起探讨。
但总归,我们得到结论,temperature和top_p这两个参数,对模型的生成结果,甚至推理能力,有很大的影响。
最后,也放上不同场景的参考temperature,当然,具体的值,也是要大家根据自己的真实业务需求进行调整测试。
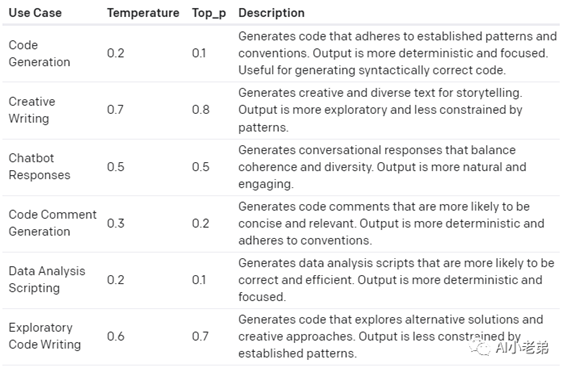
参考资料:
【1】https://arxiv.org/pdf/2212.10403.pdf
【2】https://arxiv.org/pdf/2305.14992.pdf
【3】https://arxiv.org/pdf/2212.09597.pdf
【4】https://platform.openai.com/docs/api-reference/chat/create#chat/create-temperature
出自:https://mp.weixin.qq.com/s/X1XQNEI2lEn89QPri33a8w
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip