这个东西很难说到底有没有一种简单、通俗地理解方式。
你看这个问题下面现在有60多个回答,我大概翻看了一下,几乎都是长篇大论,原因很简单,Transformer就不是简单几句话就能讲得清楚的。
这个东西很难说到底有没有一种简单、通俗地理解方式。
你看这个问题下面现在有60多个回答,我大概翻看了一下,几乎都是长篇大论,原因很简单,Transformer就不是简单几句话就能讲得清楚的。
我个人的观点是要想系统而又透彻地理解 Transformer,至少要遵循下面这样一个思路(步骤):
- 首先,了解一些NLP领域的基本知识,比如文本是如何被表征的,序列文本信息的处理,基于(深度神经网络)的语言模型是如何处理自然语言的;
- Transformer主要解决了什么问题。重点关注的方面有(自)注意力机制,多头注意力,Transformer的内部结构;
- 动手实现一个Transformer应用。
第一点属于要求掌握一些背景知识,而第三点是有意向深入学习,甚至想在实践中用Transformer做点什么的人去关注。
考虑到看这个问题的知友应该多多少少都了解一些NLP领域的知识,所以默认以及满足第一个条件。
下面进入正题。
什么是 Transformer?
一切源于2017年谷歌Brain团队那篇鼎鼎大名的文章“Attention Is All You Need”(注意力就是你所需要的一切),就是这篇文章提出了Transformer网络结构。
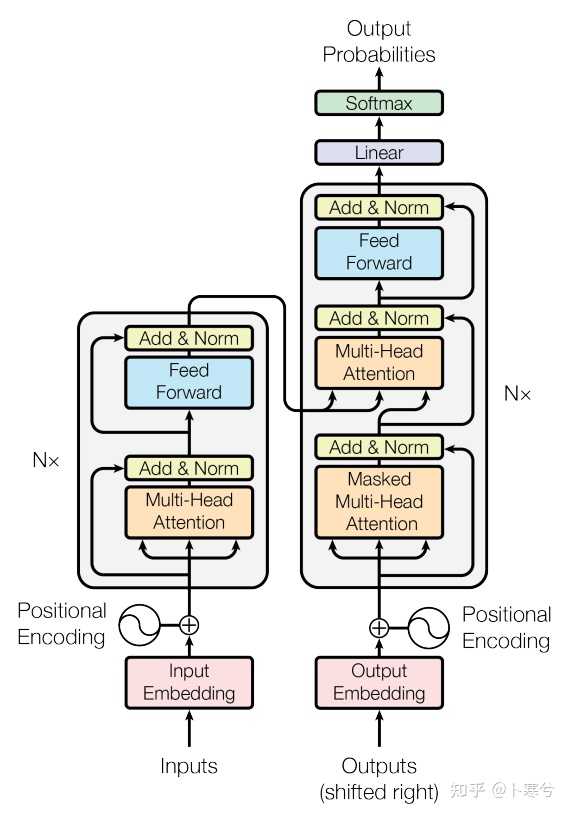

Transformer的意义体现在它的长距离依赖关系处理和并行计算,而这两点都离不开其提出的自注意力机制。
首先,Transformer引入的自注意力机制能够有效捕捉序列信息中长距离依赖关系,相比于以往的RNNs,它在处理长序列时的表现更好。
而自注意力机制的另一个特点时允许模型并行计算,无需RNN一样t步骤的计算必须依赖t-1步骤的结果,因此Transformer结构让模型的计算效率更高,加速训练和推理速度。
Transformer最开始应用于NLP领域的机器翻译任务,但是它的通用性很好,除了NLP领域的其他任务,经过变体,还可以用于视觉领域,如ViT(Vision Transformer)。
这些特点让Transformer自2017年发布以来,持续受到关注,基于Transformer的工作和应用层出不穷。包括当下最热门的AI大语言模型/聊天机器人,比如ChatGPT、文心一言、Bard等等。
这些AI大模型能生成“真假难辨”的新闻、专业论文等等,跟人类进行对话,生成代码等一系列复杂的任务。
比如,就拿这个题目的问题去问ChatGPT。我想让它给一个没有深度学习、nlp领域知识的人介绍Transformer,看他如何作答。
如果觉得还是有不少专业词汇不理解,重新让它更通俗的解释Transformer。


既然提到ChatGPT,就多说几句。大家要学会利用好ChatGPT这个“老师”。对于很多领域,ChatGPT所掌握的知识深度都超过了一个本科生(甚至更高)的水平。
像我上面这个例子只是最简单的使用ChatGPT的方法,其实ChatGPT的能力远不止这些。
就像同样一个工具,在老师傅手里和在刚入门的新手手里,其能发挥出来的功用是天壤之别的,ChatGPT等AI工具也是一样。
对于想深入学习ChatGPT和AI大语言模型(LLM)工具的知友,推荐去了解一下由知乎知学堂和AGI课堂共同推出的程序员的AI大模型进阶之旅公开课。学习使用聊天机器人的同时,还能学习更多AI大模型的知识。可以添加助教微信领取大模型资料包和好用的AI工具。有需要去下方免费领取。
2023超🔥的AI大模型公开课👉大模型资料包免费领!
¥0.00立即体验
说回到问题,上面提到,Transformer中最重要的一个方面是自注意力机制,那么到底应该如何理解这个概念呢。
首先来看注意力机制(Attention)用来干嘛?
我们人类在感知环境的时候(比如看一张图像或者一个句子),大脑能够让我们分清那部分是重要的,哪部分是次要的,从而聚焦更重要的方面以获得对应的信息。
而我们在设计神经网络模型的时候,希望模型也能具有这样的能力。例如,预测一个句子中的单词时,使用一个注意力向量来估计它在多大程度上与其他元素相关。
简单的说,注意力机制描述了(序列)元素的加权平均值,其权重是根据输入的query和元素的键值进行动态计算的。具体地,在注意力机制中,有4个概念需要明确。
- Query:Query(查询)是一个特征向量,描述我们在序列中寻找什么,即我们可能想要注意什么。
- Keys:每个输入元素有一个键,它也是一个特征向量。该特征向量粗略地描述了该元素“提供”什么,或者它何时可能很重要。键的设计应该使得我们可以根据Query来识别我们想要关注的元素。
- Values:每个输入元素,我们还有一个值向量。这个向量就是我们想要平均的向量。
- Score function:评分函数,为了对想要关注的元素进行评分,我们需要指定一个评分函数
f该函数将查询和键作为输入,并输出查询-键对的得分/注意力权重。它通常通过简单的相似性度量来实现,例如点积或MLP。
由此,权重通过softmax函数计算得出:


下图直观描述注意力如何作用在一系列单词上。对于每个单词,都有一个键和一个值向量。使用评分函数(在本例中为点积)将query与所有键进行比较以确定权重。最后,使用注意力权重对所有单词的值向量进行平均。(为了简单起见,softmax 没有可视化。)
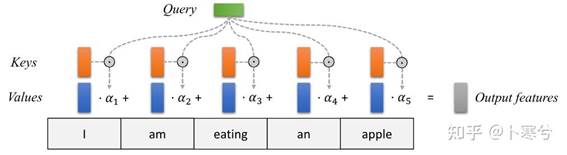
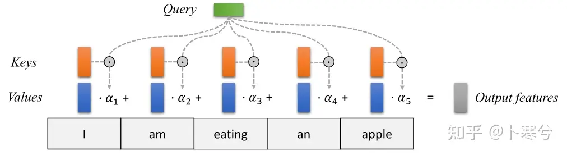
大多数注意力机制在使用哪些query、如何定义键、值向量,以及使用什么评分函数方面有所不同。
Transformer 架构内部应用的注意力称为自注意力(self-attention)。在自注意力中,每个序列元素提供一个键、值和query。对于每个元素,根据其query作用一个注意力神经层,检查所有序列元素键的相似性,并为每个元素返回一个不同的平均值向量。
自注意力机制
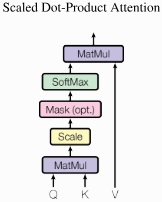
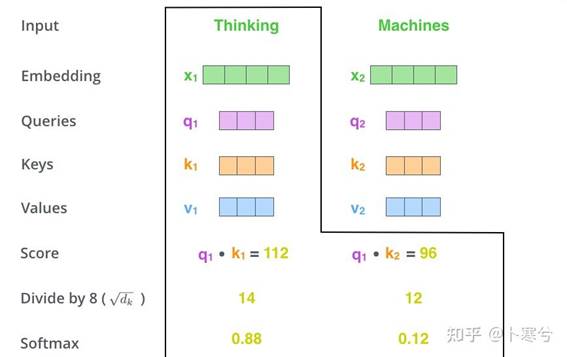
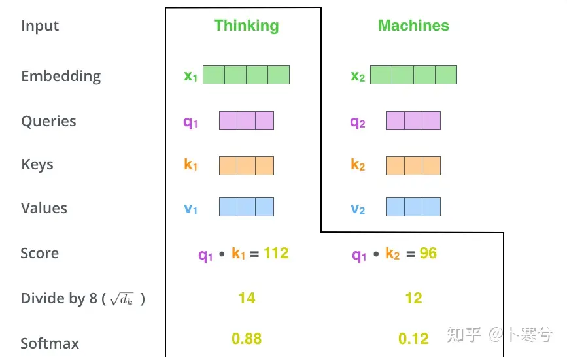
自注意力背后的核心概念是缩放点积注意力(Scaled Dot Product Attention)。目标是建立一种注意力机制,序列中的任何元素都可以关注任何其他元素,同时仍能高效计算。
点积注意力将一组查询Q,键K和值V(三者矩阵尺寸为T*d,T为序列长度,d为查询、键或值的维度)。点积注意力的计算方法如下:
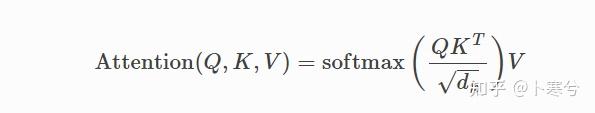
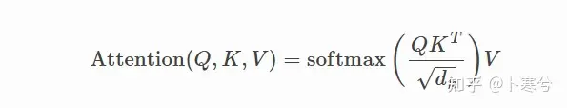
多头注意力
缩放点积注意力让模型对一个序列进行“关注”。然而,序列元素通常需要关注多个不同方面,并且单个加权平均值并不是最佳选择。这就是提出多头注意力机制(Multi-Head Attention)的根源,即相同特征上的多个不同的(查询,键,值)三元组。
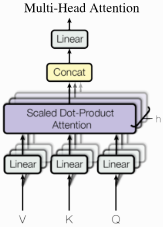
具体来说,给定一个查询、键和值矩阵,我们将它们转换为h个子查询、子键和子值,然后分别输入给点击注意力模型,最后连接头部并将它们与最终的权重矩阵组合起来。


多头注意力的一个关键特征是它相对于输入具有置换同变性(permutation-equivariant)。因此,多头注意力实际上不是将输入视为序列,而是视为一组元素。这一特性使得多头注意力模块和 Transformer 架构适用广泛。
然而,可能很多人也想到了,如果输入的顺序对于解决任务(例如语言建模)实际上很重要怎么办?答案是对输入特征中的位置进行编码。
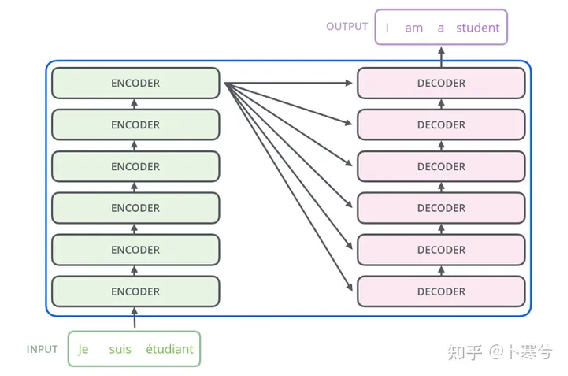
Transformer编码器
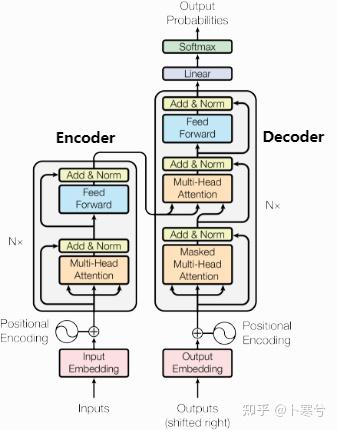
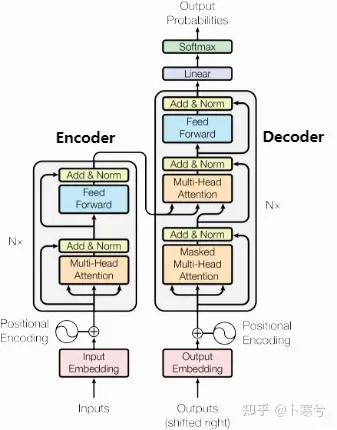
最初,Transformer 模型是为机器翻译而设计的。它是一个编码器-解码器结构,其中编码器将原始语言的句子作为输入并生成基于注意力的表征。而解码器关注编码信息并以自回归方式生成翻译的句子,就像 RNN 一样。
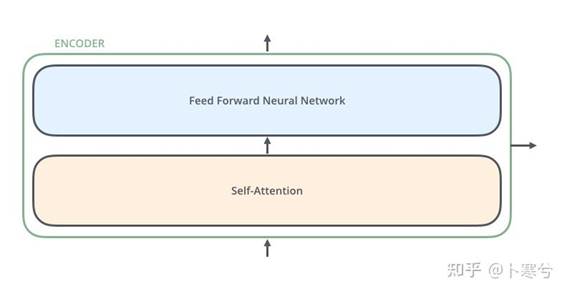
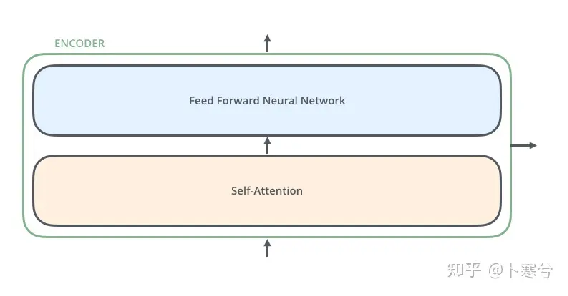
编码器由N个相同的模块组成,输入x首先通过上面提到的多头注意力块。使用残差连接将输出添加到原始输入,每一次都有归一化操作。
残差连接在
Transformer 架构中至关重要。
1、首先,与 ResNet 类似,Transformers 层级很深。某些模型的编码器中包含超过 24 个blocks。因此,残差连接对于模型梯度的平滑流动至关重要。
2、如果没有残余连接,原始序列的信息就会丢失。多头注意力层忽略序列中元素的位置,并且只能根据输入特征来学习它。删除残余连接意味着该信息在第一个注意层之后(初始化之后)丢失,并且使用随机初始化的查询和键向量,位置i的输出向量与其原始输入无关。注意力的所有输出都可能表示相似/相同的信息,并且模型没有机会区分哪些信息来自哪个输入元素。
归一化层在
Transformer 架构中也发挥着重要作用,它可以实现更快的训练速度。
除了多头注意力之外,模型中还包括一个小型全连接前馈网络,应用于每一个block。它增加了模型的复杂度,并允许单独对每个序列元素进行转换。
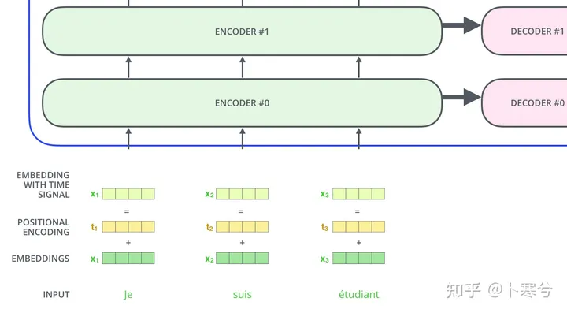
位置编码
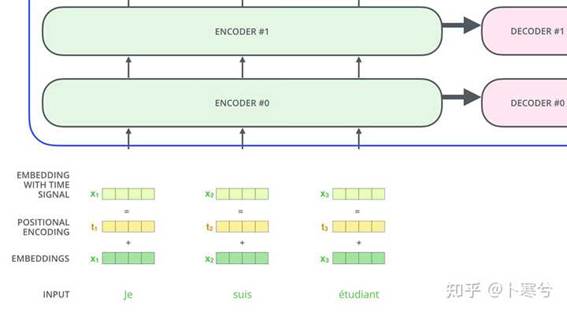
上面已经提到过,多头注意力模块是置换同变性的,并且无法区分一个输入是否出现在序列中的另一个输入之前。然而,在语言理解等任务中,位置对于解释输入单词非常重要。因此可以通过输入特征添加位置信息。Transformer通过向输入的每个嵌入(embedding)中添加一个向量完成位置编码(position encoding)。
学习资源
最后,介绍几个比较优秀的Transformer的论文解读和教程,供大家参考。
1、Transformer: A Novel Neural Network Architecture for Language
Understanding
谷歌官方团队在Transformer刚出来时的一篇博客,重点关注Transformer在机器翻译领域的应用。
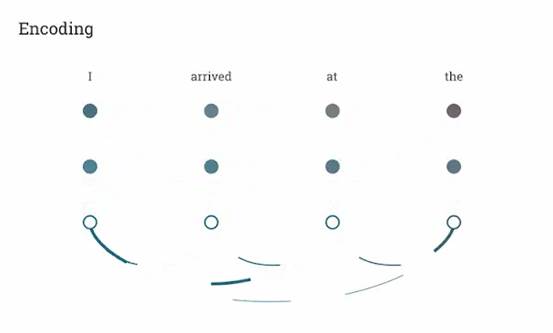
下面的动画展示了如何将 Transformer 应用到机器翻译中。用于机器翻译的神经网络通常包含一个编码器,读取输入句子并生成它的表示。然后,解码器逐字生成输出句子,同时参考编码器生成的表示。 Transformer 首先为每个单词生成初始表示或嵌入。这些由未填充的圆圈表示。然后,使用自注意力机制,它聚合来自所有其他单词的信息,根据整个上下文生成每个单词的新表征,由实心球表示。然后对所有单词并行重复此步骤多次,连续生成新的表征。
2、The Illustrated Transformer,用很直观的可视化的方式剖解Transformer结构和工作原理。
3、Attention? Attention! 和 The Transformer Family,同益位作者的博文,第一篇系统的介绍了注意力机制,包括视觉领域的方法。第二篇梳理了Transformer的各种变体。


4、Illustrated: Self-Attention,对自注意力机制的可视化,对于直观理解其原理和dataflow很有帮助。
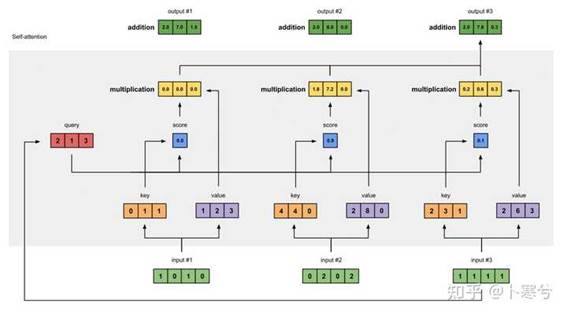
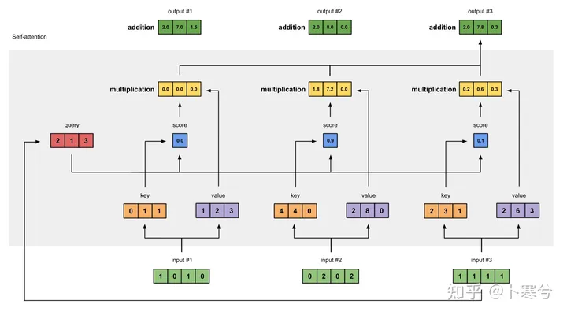
5、超详细图解Self-Attention。知乎上的一篇文章,参考一些解读后深入浅出的讲解自注意力机制。
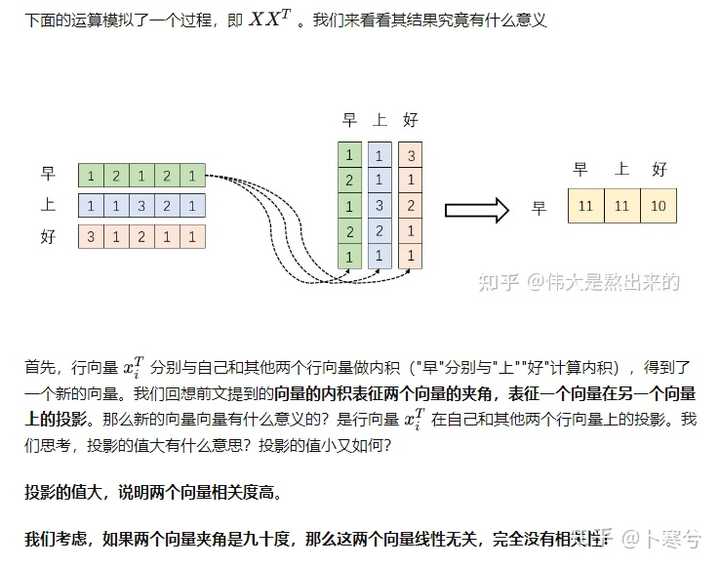
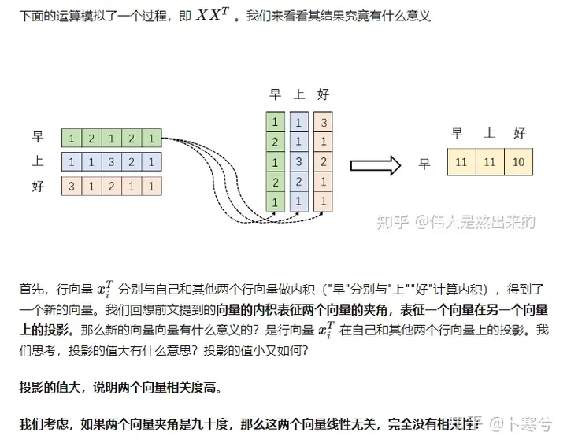
出自:https://www.zhihu.com/question/445556653
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip