顶尖学者合作推出交互式代理基础模型,具备处理文本、图像、动作输入的多模态能力,可应用于机器人、游戏、医疗等多领域。模型具有实时判断和多模态处理能力,利用预训练子模块和游戏数据集提升性能,实现精准预测和强适应性。该模型为通用、行动导向的AI应用提供了有希望的途径,作者将开源项目代码。
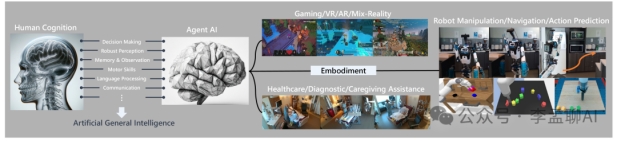
斯坦福、微软、UCLA的顶尖学者联手,推出了一个全新交互式基础代理模型!
这个模型能处理文本、图像、动作输入,轻松应对多任务挑战,甚至跨界在机器人、游戏、医疗等领域展现强大实力。
 在这里插入图片描述
在这里插入图片描述
注意:LangChain Agent主要增强基于语言的互动能力,而交互式代理基础模型寻求统一多模态输入,以实现更广泛的通用AI应用。
2.77亿参数、1340万帧视频训练数据,背后蕴含着怎样的技术秘密?
模型介绍
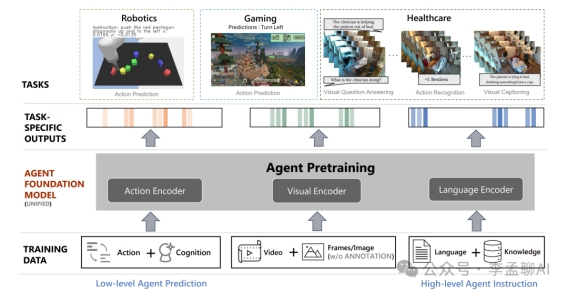 交互式代理基础模型就像个全能学霸,看图、听话、预测动作样样精通。
交互式代理基础模型就像个全能学霸,看图、听话、预测动作样样精通。
最酷的是,它能实时做出判断,无需等待环境反馈。
这个框架利用深度学习和多模态输入(如文本、图像和动作)来训练一个智能体,使其能够在不同的环境中执行任务。
接下来我们看下这种模型优势在哪里?
方法优势
 在这里插入图片描述
在这里插入图片描述
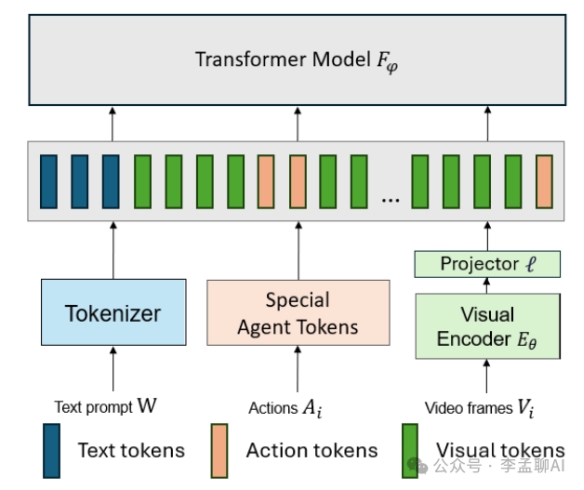
多模态处理能力:该模型能够同时处理文本、视觉数据和行动指令,这种跨模态的特性使其能够适应更广泛的实际场景,而不仅仅是单一的数据类型。
强大的预训练子模块:通过利用CLIP ViT-B16和OPT-125M这两个预训练模型,该架构在视觉编码、动作理解和语言处理方面都具有出色的性能基础。
游戏任务中的精准学习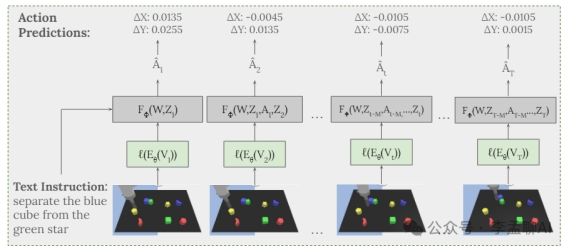
在Minecraft和Bleeding Edge等游戏数据集上进行预训练,模型能够学习到精确的行为预测。
GPT-4V的应用进一步强化了指令的具体性,使模型能够更准确地响应复杂的游戏任务。
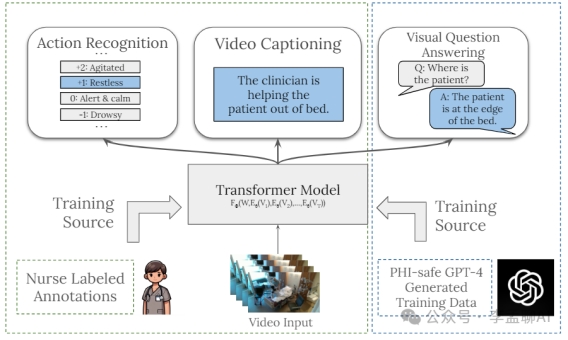
医疗任务的实时应用
 在这里插入图片描述
在这里插入图片描述
通过ICU房间的实时视频记录,模型能够接触到真实的医疗环境数据。
结合经验丰富的护士提供的视频字幕和临床文档,模型在医疗任务中的表现得到了显著提升,特别是在视频字幕生成、视觉问答和RASS评分预测等方面。
实验结果
模型预测的动作示例 处理复杂场景
处理复杂场景
GPT-4V在处理如Bleeding Edge等具有第三人称视点和视觉复杂场景的游戏时,展现出了强大的能力。
大量帧输入
我们成功地将48帧的大量视觉数据以网格形式输入给GPT-4V,并在每帧上叠加了帧号,确保了数据的准确性和完整性。
精确预测
GPT-4V能够根据输入的文本指令和先前动作序列,准确地预测出游戏中的下一个动作。
这在游戏开发和玩家体验优化方面具有巨大的应用潜力。
强大的适应性
通过在不同的游戏任务上进行测试,我们发现GPT-4V具有很强的适应性。
无论是面对何种类型的游戏场景和指令,它都能够迅速适应并给出准确的预测结果。
论文:https://arxiv.org/pdf/2402.05929.pdf
后续作者表示会开源项目代码!
结语
交互式代理基础模型为实现通用、行动导向的AI提供了一条有希望的途径。
出自:https://mp.weixin.qq.com/s/RAdVo3UmDafBlmIuDicjvw
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip