Deepseek发布了v2版本模型,沿用Deepseek-MoE技术,采用小专家建模与多优化策略。该模型完全开源并支持商用,提供了低成本的API调用方案。v2模型在MMLU上取得第二名,超越V1版本,并显著提升成本效率与推理速度。其核心优化在于多头隐式注意力(MLA),旨在减少显存占用,同时保持模型效果。模型架构包含60层,采用RMSNorm和SiLU激活函数,并通过对话数据进行对齐训练。工程上,v2通过流水线并行和专家并行策略,结合资源感知专家负载均衡方法,实现了训练效率的最优。模型在基座能力和指令遵循能力上表现强劲,得益于数据优化和训练策略的深度整合。
深度求索Deepseek近日发布了v2版本的模型,沿袭了1月发布的 Deepseek-MoE(混合专家模型)的技术路线,采用大量的小参数专家进行建模,同时在训练和推理上加入了更多的优化。沿袭了一贯的作风,Deepseek对模型(基座和对话对齐版本)进行了完全的mit协议开源,可以商用。对于算力不是那么充足的开发者,官方提供了API调用的方案,费用更是达到了全场最低!
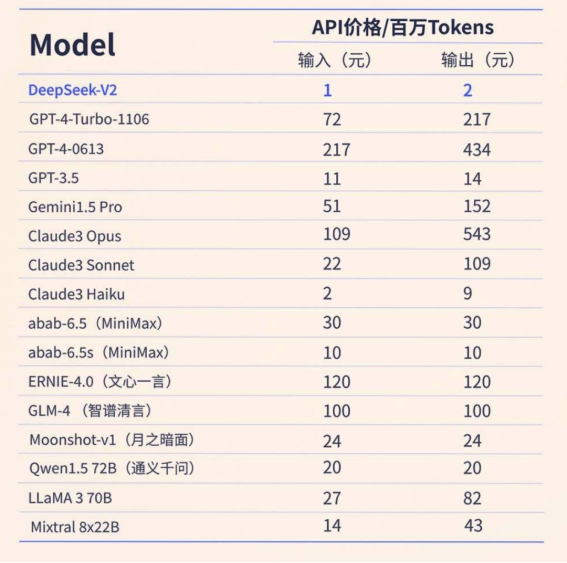
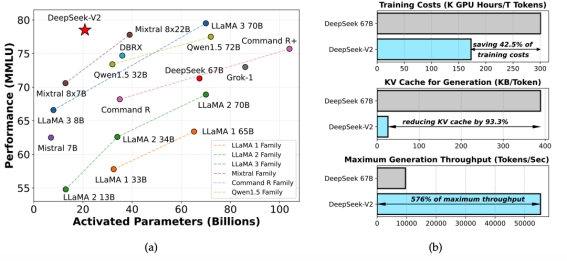
在技术报告的开始,Deepseek团队用多个数字和两张图直观地概括了目前模型取得的效果。模型参数量方面达到236B ,同时由于模型小专家混合的特性,模型在推理时的激活参数很少,可以实现高推理速度。在通用能力的表现上,模型在MMLU多选题benchmark上拿到 分,取得了第二名,Deepseek-V2在众多开源模型中表现仅次于70B 的 LLaMA3,超过了他们此前发布的V1代67B的非MoE模型。在成本效率方面,相比V1的稠密模型,V2模型节约了的训练成本,减少了推理时的 KV-cache 显存占用,将生成的吞吐量也提升到了原来的倍。借助YaRN优化的长度外推训练方法,模型的上下文能力得以扩展到了128k大小。下面我们结合代码和技术报告,对Deepseek-V2模型进行详细的解读。
核心优化解析
在这里我们结合官方技术报告中的模型架构图辅助说明,介绍模型的核心优化点——多头隐式注意力(Multi-head Latent Attention,MLA):
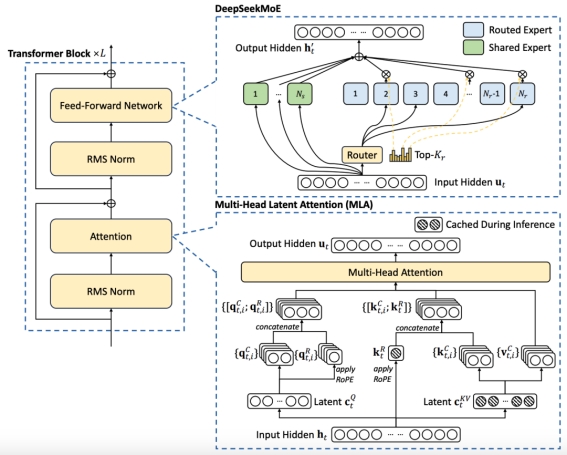
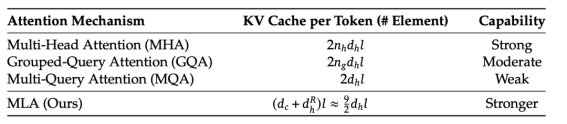
如上图右下所示,大模型使用kv-cache进行模型的解码加速,但是当序列较长的情况下很容易出现显存不足的问题,MLA从这一角度出发,致力于减少kv缓存的占用。
MLA从LoRA的成功借鉴经验,实现了比GQA这种通过复制参数压缩矩阵尺度的方法更为节省的低秩推理,同时对模型的效果损耗不大。我们首先结合配置文件中的这几行了解下每个部分的作用:
"hidden_size": 5120,
"kv_lora_rank": 512,
"moe_intermediate_size": 1536,
"q_lora_rank": 1536,
"qk_nope_head_dim": 128,
"qk_rope_head_dim": 64
模型处理上一层计算出的隐藏状态(hidden_size=5120)时,首先会将模型的q压缩到 q_lora_rank这一维度(设定为1536),再扩展到 q_b_proj 的输出维度(num_heads * q_head_dim),最后切分成 q_pe 和 q_nope 两个部分,在训练部分中我们将看到这样设计的作用。
##### __init__ #####
self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim # =192
self.q_a_proj = nn.Linear(
self.hidden_size, config.q_lora_rank, bias=config.attention_bias
)
self.q_a_layernorm = DeepseekV2RMSNorm(config.q_lora_rank)
self.q_b_proj = nn.Linear(
config.q_lora_rank, self.num_heads * self.q_head_dim, bias=False
)
##### forward #####
bsz, q_len, _ = hidden_states.size()
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
# q (bsz, q_len, 24576)
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
# q (bsz, q_len, 128, 192)
q_nope, q_pe = torch.split(
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
)
# 将最后一层 192 的hidden_states切分为 128 (qk_nope_head_dim) + 64 (qk_rope_head_dim)
对于kv矩阵的设计,模型使用了kv压缩矩阵设计(只有576维),在训练时进行先降维再升维。在模型推理的时候,需要缓存的量变成 compressed_kv,经过 kv_b_proj 升高维度得到 k,v 的计算结果。
##### __init__ #####
self.kv_a_proj_with_mqa = nn.Linear(
self.hidden_size,
config.kv_lora_rank + config.qk_rope_head_dim,
bias=config.attention_bias,
)
self.kv_a_layernorm = DeepseekV2RMSNorm(config.kv_lora_rank)
self.kv_b_proj = nn.Linear(
config.kv_lora_rank,
self.num_heads
* (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim),
bias=False,
)
##### forward #####
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
compressed_kv, k_pe = torch.split(
compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1
)
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
kv = (
self.kv_b_proj(self.kv_a_layernorm(compressed_kv))
.view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim)
.transpose(1, 2)
)
那么,为什么Deepseek-V2要把整个计算流程拆成 q_nope, k_nope, k_pe, k_nope 这四个部分呢?在RoPE的实现中,如果想要直接让模型的 q, k 具有位置性质,通常是这样做的,m,n 代表特定位置的token,R的含义可以查阅RoPE:
计算输出的attention得分时,整个过程变成了:
为了节约KV cache的内存,Deepseek-V2将kv cache压缩到了同一个小矩阵中,后面再解压缩出来:
这个时候注意力得分的计算可以写成:
这个时候我们变得清楚了,我们apply旋转位置编码的时候,标准的不带解压缩的实现是会将原始的K状态直接更新到拼到K前面的,而上面的矩阵运算是使用先左乘,后解压缩的方式,由于矩阵乘法是没有交换律的,因此这种矩阵压缩设定下使用C作为cache直接拼接在数学上是不等价的。为了解决这个问题,Deepseek-V2设计了两个pe结尾的变量用于储存旋转位置编码的信息,将信息存储和旋转编码解耦合开。

之后,将q,k中负责储存信息的部分,负责旋转编码的部分拼接起来,进行标准的attention计算:
k_nope, value_states = torch.split(
kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1
)
kv_seq_len = value_states.shape[-2]
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe
if past_key_value is not None:
cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
key_states, value_states = past_key_value.update(
key_states, value_states, self.layer_idx, cache_kwargs
)
attn_weights = (
torch.matmul(query_states, key_states.transpose(2, 3)) * self.softmax_scale
)
attn_output = torch.matmul(attn_weights, value_states)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, self.num_heads * self.v_head_dim)
attn_output = self.o_proj(attn_output)
最后将 num_head 维度拉平,经过输出矩阵得到模型这一层的输出隐藏状态,仍为 5120 维。
架构解读
我们通过模型的架构图和配置文件对模型设计有一个大致的认知,Deepseek的模型习惯采用 remote_code导入的格式,下载模型后,我们通过官方示例导入模型权重,打印出模型的架构。
DeepseekForCausalLM(
(model): DeepseekModel(
(embed_tokens): Embedding(102400, 5120)
(layers): ModuleList(
(0): DeepseekDecoderLayer(
(self_attn): DeepseekAttention(
(q_a_proj): Linear(in_features=5120, out_features=1536, bias=False)
(q_a_layernorm): DeepseekRMSNorm()
(q_b_proj): Linear(in_features=1536, out_features=24576, bias=False)
(kv_a_proj_with_mqa): Linear(in_features=5120, out_features=576, bias=False)
(kv_a_layernorm): DeepseekRMSNorm()
(kv_b_proj): Linear(in_features=5120, out_features=32768, bias=False)
(o_proj): Linear(in_features=163840, out_features=5120, bias=False)
(rotary_emb): DeepseekYarnRotaryEmbedding()
)
(mlp): DeepseekMLP(
(gate_proj): Linear(in_features=5120, out_features=12288, bias=False)
(up_proj): Linear(in_features=5120, out_features=12288, bias=False)
(down_proj): Linear(in_features=12288, out_features=5120, bias=False)
(act_fn): SiLU()
)
(input_layernorm): DeepseekRMSNorm()
(post_attention_layernorm): DeepseekRMSNorm()
)
(1-59): 59 x DeepseekDecoderLayer(
(self_attn): DeepseekAttention(
(q_a_proj): Linear(in_features=5120, out_features=1536, bias=False)
(q_a_layernorm): DeepseekRMSNorm()
(q_b_proj): Linear(in_features=1536, out_features=24576, bias=False)
(kv_a_proj_with_mqa): Linear(in_features=5120, out_features=576, bias=False)
(kv_a_layernorm): DeepseekRMSNorm()
(kv_b_proj): Linear(in_features=5120, out_features=32768, bias=False)
(o_proj): Linear(in_features=163840, out_features=5120, bias=False)
(rotary_emb): DeepseekYarnRotaryEmbedding()
)
(mlp): DeepseekMoE(
(experts): ModuleList(
(0-159): 160 x DeepseekMLP(
(gate_proj): Linear(in_features=5120, out_features=1536, bias=False)
(up_proj): Linear(in_features=5120, out_features=1536, bias=False)
(down_proj): Linear(in_features=1536, out_features=5120, bias=False)
(act_fn): SiLU()
)
)
(gate): MoEGate()
(shared_experts): DeepseekMLP(
(gate_proj): Linear(in_features=5120, out_features=3072, bias=False)
(up_proj): Linear(in_features=5120, out_features=3072, bias=False)
(down_proj): Linear(in_features=3072, out_features=5120, bias=False)
(act_fn): SiLU()
)
)
(input_layernorm): DeepseekRMSNorm()
(post_attention_layernorm): DeepseekRMSNorm()
)
)
(norm): DeepseekRMSNorm()
)
(lm_head): Linear(in_features=5120, out_features=102400, bias=False)
)
我们从上往下,从embedding层的维度来看,与Gemma, LLaMA和Qwen的经验一致,Deepseek也选取了较大的输入词表作为模型的输入(数据充足且多样的情况下当然可以这么干),这样做的好处是词表的多样性强,解码的一个token内有多个字,压缩效率很高。
"num_hidden_layers": 60,
"num_key_value_heads": 128,
"num_experts_per_tok": 6,
"n_shared_experts": 2,
"n_routed_experts": 160
通过以上配置分析,模型共有60个层,注意力头数为128,总的门控专家个数为160,每个token计算有6个门控专家被激活,同时还有2个共享专家保持激活状态,共计8个被激活的专家。在经过embedding层后,与Deepseek-MoE保持一致,首先会经过一个共享的大Decoder层进行第一层计算,这层模型的attention计算设定与后续59层基本一致,唯一区别是这一层的mlp层固定为8个专家的宽度,没有门控额外参数激活的设定,这一设置与每层共享专家的设定一样,研究者希望语言生成的公共知识(包含流畅性、逻辑性等)被存储在这里。
而当我们从模型的整体架构选取上来看,层数足够深的时候使用pre-norm方便模型训练,归一化使用RMSNorm,非线性激活函数使用SiLU,attention矩阵不加bias(对flash-attention有好处),这些似乎是如今大厂在训练大模型时候会采用的标配了。
训练
1. MLA设定下的解耦长度外推:模型使用基于进制转换的YaRN进行长度外推训练,在大海捞针测试中表现不错。
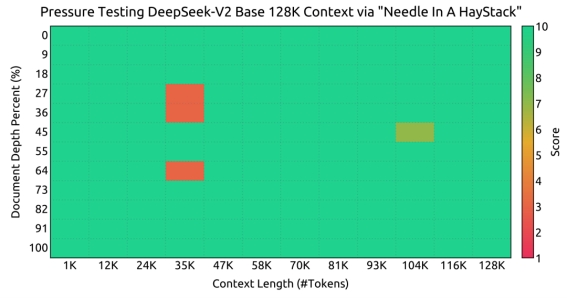
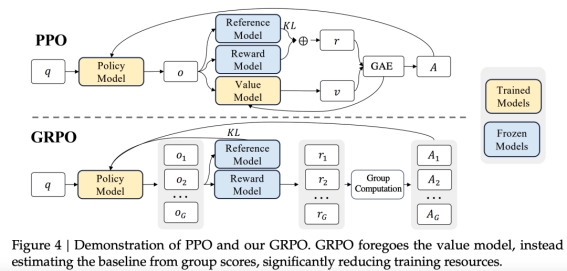
1. 模型对齐训练:模型使用对话数据进行SFT,同时评估时重点关注指令遵循能力。在强化对齐阶段也下了很大的功夫,最早出现在Deepseek-Math中的GRPO算法被用来进行偏好对齐训练,这是一种无需在训练中更新通常与Policy Model(被对齐模型)同样大小的 Critic Model 的参数的训练方法,是一种资源优化的 PPO。(注意:还是需要训 Reward Model 的,只是不会在对齐的时候进行参数更新)

GRPO和PPO的对比
Infra
模型训练的工程优化方面(infra)仍有很多给人启示的点。模型使用了pp=16的流水线并行(pipeline parallel),160个专家分ep=8个节点并行(expert parallel),而并未采取任何形式的张量并行(tensor parallel),降低了通信成本,使用了ZeRO-1的数据并行来减少优化器状态的显存占用。训练设施在卡间使用NVLink和NVSwitch,节点间使用InfiniBand交换机,通信优化已经全部拉满。并行策略全部使用自研的HAI-LLM实现。
另外,Deepseek-V2结合算法和工程,提出了资源感知专家负载均衡的方法,保证了专家并行的几个机器雨露均沾,不会出现有些机器空转,有些机器过度占用的情况。在训练时,结合模型本身的专家ensemble特性,各个专家在训练开始的过程中是完全对称的,这种设计如果不做额外的限制,容易出现压力过多分担到某些门控专家的现象,造成这些专家所在的机器节点参数更新频繁,而未发挥作用的专家所在的机器空转。提出了三个维度的均衡优化,把不同机器上专家的协作属性融入到loss计算中:
1. 专家维度的均衡,避免有些专家过度劳累,把知识学杂了:

1. 机器维度的均衡,希望处理每个token的6个专家,尽可能分散到不同的机器上:

1. 通信维度的均衡:虽然前面已经做了机器维度的均衡保证,但我们举一个例子(ep_size=8):
[tok_0, tok_1, tok_2, ..., tok_n]
算 tok_0 专家所在的机器: 0,1,2,3,5,6
算 tok_1 专家所在的机器: 0,4,2,1,3,7
算 tok_2 专家所在的机器: 0,1,2,3,5,6
这样仍然不行,虽然满足了每个token的专家都很分散,但是机器0,1,2,3的使用过于频繁,4,5,6,7的使用过少。简单来说,目标2,3联合起来,理想状态下是模型参数更新时,专家所在的机器在上方矩阵的行维度最好出现0次或1次,而综合起来看整个矩阵每个机器出现的次数是整体机器使用量的 ,这样才能实现资源利用均衡。

融合算法和工程!这也是另一个Deepseek的亮点,目标1实现了算法上的最优,充分利用了模型ensemble的结构设计,目标2,3避免机器空转,实现了模型训练效率的最优。
模型效果
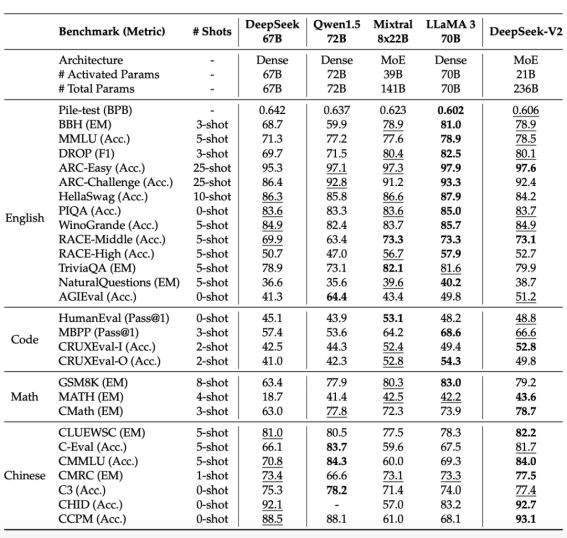
基座能力很强,很有可能来自模型训练的数据优化,中文数据占比是英文数据占比的1.12倍。
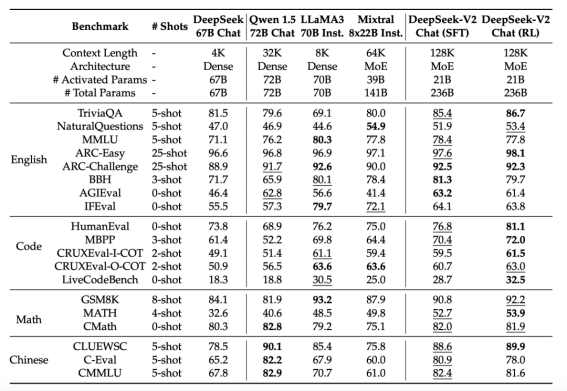
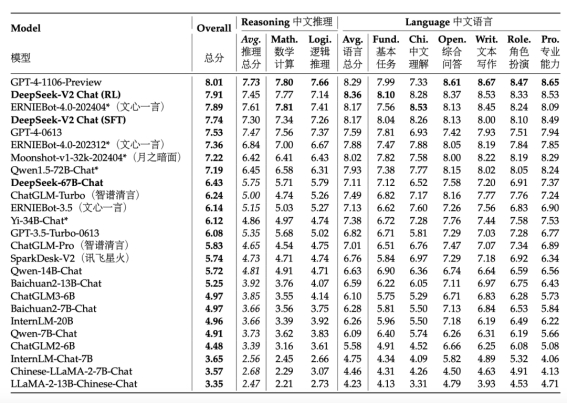
指令遵循能力很好。
讨论
本部分我们直接从报告中看Deepseek官方给的结论,
指令微调数据规模
DeepSeek-V2经过实验表明,进行SFT的实验数据如果太少,例如少于10000条,模型的IFEval指标下降明显。另外,数据量的减少不是增加模型的规模可以弥补的缺陷,模型必须通过大的数据量才能学习到指令遵循所需的关键知识。
强化学习对齐税
Deepseek-V2的研究者们发现人类偏好对齐有利于开放的问题回答,也就是说一个大模型是不是真正好很有可能来自这部分。
但是这部分会造成对齐税,具体来说就是对齐了人类偏好,成为一个好用的模型,不利于模型刷榜。为了减轻影响,Deepseek-V2进行更为精细的数据处理和训练策略改进,最终实现了权衡。
在线而不是离线偏好对齐
DeepSeek-V2发现在强化学习偏好对齐方面,在线方法显著优于离线方法。
总结
得力于出色的研究人员和工程团队,Deepseek-V2将大语言模型训练中广泛被验证有用的训练策略深度整合,集合了长度外推训练的YaRN,高效对齐的GRPO,MLA与混合专家分配等方法进行模型训练。做到了算法、工程和数据的极致优化。
出自:https://mp.weixin.qq.com/s/R278GyZnsLH-LFNGJ0tz4Q
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip