

1.
内容简介
2.
该研究目标是创建一个与用户意图更符合的小型语言模型。通过应用蒸馏监督微调(distilled supervised fine-tuning, dSFT)和蒸馏直接偏好优化(distilled direct preference optimization, dDPO)以及利用AI反馈(AI Feedback, AIF)的偏好数据,研究者成功提升了模型的任务准确性和意图对齐度。ZEPHYR-7B模型以7B参数在聊天基准测试中创立了新标准,无需人工注释,且在MT-Bench测试中超过了之前的模型。此方法的优势包括较短的训练时间和无需额外采样,为开放大型语言模型(LLMs)的发展和微调提供了新方向。同时,研究未考虑模型安全性如可能产生有害输出等问题。
2. 核心算法
这个方法的目标是使一个开源的大型语言模型与用户的意图对齐。在这项工作中,研究者们假设可以访问一个更大的教师模型(Teacher Model),该模型可以通过提示生成来查询。他们的目标是产生一个学生模型(Student Model),并且他们的方法遵循与InstructGPT 类似的阶段,如图2所示。
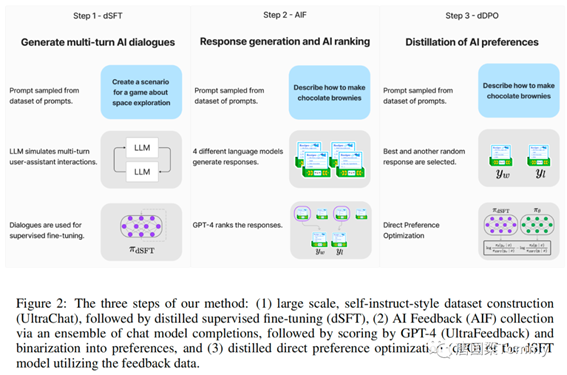
这幅图描述了一个三步骤的方法来进一步训练和优化AI模型。以下是对每个步骤的详细解释:
这幅图描述了一个三步骤的方法来进一步训练和优化AI模型,以下是对每个步骤的详细解释:
1. dSFT (distilled
supervised fine-tuning) 步骤:
① 生成多轮AI对话: 开始于从一个数据集中随机选择一个提示。
② 创建场景: 作为示例,AI被要求为一个关于太空探索的游戏创建一个场景。
③ LLM (Language Learning Model) 模拟多轮用户-助理交互: LLM对该场景进行多轮的对话生成,模拟真实的用户与助理之间的互动。
这些对话随后被用于监督式微调。
2. AIF (AI Feedback) 步骤:
① 响应生成和AI排序:
- 从数据集中抽样得到一个提示,例如,“描述如何制作巧克力布朗尼”。
- 有4个不同的语言模型生成对此提示的响应。
- GPT-4(一个先进的语言模型)对这些响应进行评分和排序。
3. dDPO (distilled Direct
Preference Optimization) 步骤:
① AI偏好的提炼:
- 对于同一个提示,例如,“描述如何制作巧克力布朗尼”,选择最佳响应和另一个随机响应。
- 这两个响应被用于直接偏好优化,其中模型会学习根据反馈数据优化其偏好。
- 在此步骤中,模型尝试理解哪一个响应更受偏好,并对其进行相应的调整。
这三个步骤结合起来形成了一个复杂的AI训练和优化方法。首先通过dSFT进行基础的模型训练,然后通过AIF收集反馈并对模型进行评分和排序,最后通过dDPO根据这些反馈优化模型的偏好。
2.1 蒸馏的有监督微调 Distilled
Supervised Fine-Tuning (dSFT)
2.1.1
传统方法
通过对一个高质量instructions和responses的数据集进行有监督的微调 (SFT) 来完成的。
2.1.2 新的方法
给定可以访问一个教师语言模型的能力,让模型生成instructions和responses,我们可以直接在这些数据集上进行训练。
① dSFT的方法遵循self-instruct协议,该协议要求构建一组种子提示(seed prompts),这些提示代表了多种主题领域。
② 数据集是通过iterative
self-prompting(迭代自我提示)来构建的,其中教师模型用于响应一个instruction并根据response优化这个instruction。
③ 对于每一个种子提示,首先从教师模型中抽样得到一个response,然后使用一个提示来进行精炼,并再次从教师模型中抽样得到一个新的instruction。
④ 最终的目标是得到一个数据集,该数据集包含instructions和responses的配对,例如:C = {(x1, y1), ...,
(xj, yj)}
⑤ 最后,通过SFT方法进行蒸馏。
重点公式-1 :偏好模型
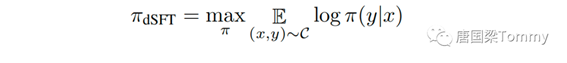
公式的目的是在训练过程中最大化模型对给定数据集C中的instruction-response pair的对数似然。这有助于模型更好地学习如何回应用户的提示,从而提高其输出质量。
公式说明:(截图来自我准备的思维导图,微信公众号不支持LaTex语法)

2.1.3 举例说明(辅助理解dSFT的执行流程)
(1)背景
假设我们正在训练一个简化的语言模型,该模型的任务是对天气相关的问题给出回答。我们想使用 dSFT 方法来进一步优化它。
(2)种子提示(seed prompt)
我们从以下三个种子提示开始:1. 描述今天的天气。2. 明天会下雨吗?3. 本周的气温范围是多少?
(3)迭代自我提示
第1步:我们使用已有的教师模型(假设是GPT-4)来响应这些种子提示,假设回答如下:
1. 对于 "描述今天的天气。",教师模型可能回应 "今天是晴天,温度约为25°C。"
2. 对于 "明天会下雨吗?",教师模型可能回应 "明天有60%的机会下雨。"
3. 对于 "本周的气温范围是多少?",教师模型可能回应 "本周的气温范围是20°C到30°C。"
第2步:接下来,基于每一个种子提示和对应的回应,我们生成新的提示。
1. 基于 "今天是晴天,温度约为25°C。",新的提示可能是 "今天的最高和最低温度是多少?"
2. 基于 "明天有60%的机会下雨。",新的提示可能是 "明天的降雨量预测是多少?"
3. 基于 "本周的气温范围是20°C到30°C。",新的提示可能是
"本周哪一天最冷?"
第3步:这些新提示再次被提供给教师模型,并生成对应的回应。这一过程可以反复进行,直到达到所需的数据集大小。
(4)最终数据集
在几轮迭代后,我们可能得到以下数据集:
1. "描述今天的天气。", "今天是晴天,温度约为25°C。"
2. "明天会下雨吗?",
"明天有60%的机会下雨。"
3. "本周的气温范围是多少?",
"本周的气温范围是20°C到30°C。"
4. "今天的最高和最低温度是多少?",
"最高温度为28°C,最低温度为22°C。"
5. "明天的降雨量预测是多少?",
"预计明天的降雨量为5mm。"
6. "本周哪一天最冷?", "本周五最冷,预计最低温度为20°C。"
这就是 dSFT 数据集构建过程的一个简化示例。在实际应用中,种子提示、回应和新提示会更加多样化,而且可能涉及到更复杂的主题和领域。
2.2 基于偏好的AI反馈 AI Feedback through Preferences (AIF)
2.2.1
传统方法
人类反馈 (Human feedback,
HF) 可以为对LLM的对齐提供额外的信号,人们通常通过对LLM响应的偏好来给出反馈。
2.2.2
新的方法
对于蒸馏,我们使用教师模型(假设GPT-4)生成的输出的AI偏好。UltraFeedback方法,它使用教师模型为模型输出提供偏好。
2.2.3 AIF
具体步骤
(截图来自我准备的思维导图,微信公众号不支持LaTex语法)

这种方法基本上是为了通过模型的响应获取更好的教师模型反馈。通过对比多个模型的响应,并利用教师模型为这些响应评分,系统可以更好地理解哪些响应更受偏好。这样,模型可以更准确地学习人类的偏好,并据此进行训练和优化。
2.3 蒸馏的直接偏好优化 Distilled
Direct Preference Optimization (dDPO)
2.3.1
目标
dDPO的目标是优化一个特定的模型πdSFT,使其能够在一个称为"preference model 偏好模型"中更好地排名预期输出yw相对于其他输出yl。这其实是一个排序问题,我们希望模型能更频繁地选择yw而不是yl。
2.3.2
奖励函数
奖励函数定义为 r(x,y),其决定了在给定输入x和输出y的情况下,模型的预测有多好。这个函数利用了一个称为"student language model"的模型。
2.3.3
Direct Preference Optimization (DPO)
传统的技术使用了一种RL方法,先训练奖励,然后采样来计算更新。但DPO采取了一个直接的方法:它直接从所谓的"静态数据"中优化偏好模型。静态数据 (Static Data)是指用户的历史行为数据、购买记录或其他信息,它们不随时间变化。
2.3.4
关键的观察与数学公式
DPO方法的核心是派生两种策略之间的关系:
策略-1: 最优LLM策略π∗
即在给定的条件下最可能导致用户满意的策略。
策略-2: 原始LLM策略πdSFT
这是一个基准策略,可能基于以前的数据或经验来制定。
给定上述策略,奖励函数:

2.3.5
目标函数
当我们将奖励函数插入到偏好模型中,我们可以得到以下的目标函数:
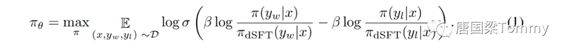
这个公式基本上表示:我们希望最大化在给定输入x时选择yw而不是yl的可能性。
2.3.6
训练过程
这部分描述了如何使用上述目标函数进行模型训练:
对于每一个 AIF三元组 (x, yw, yl),计算过程如下:
① 在 dSFT 模型中计算 (x, yw) 和 (x, yl) 的概率;
② 在 dDPO 模型中计算 (x, yw) 和 (x, yl) 的概率;
根据上述的 目标函数(公式-1) 计算损失,并进行反向传播更新模型。
2.3.7 举例说明:(辅助理解PPO与DPO的区别)
假设我们正在训练一个电子游戏中的代理(Agent),代理的任务是在迷宫中寻找宝藏。
(1)传统方法:PPO (Proximal Policy Optimization)
策略:
PPO
通过迭代地优化代理的策略来使其更好地在迷宫中寻找宝藏
工作流程:
① 代理根据当前的策略在迷宫中行动,收集一系列的经验数据。
② 使用这些经验数据来更新策略,使得新策略不会偏离原策略太多(这就是“proximal”的意思)。
③ 重复以上步骤,直到代理能够有效地找到宝藏。
(2)新的方法:DPO (Direct
Preference Optimization)
策略:
DPO
直接从已有的静态数据中优化代理的偏好模型。
工作流程:
① 假设我们已经有了一堆代理在迷宫中寻找宝藏的历史数据。这些数据包含了在给定状态下,代理的不同行动及其结果。
② DPO 不直接更新策略,而是更新一个偏好模型,这个模型会预测在给定状态下哪个行动更受代理的偏好(或者说哪个行动更有可能找到宝藏)。
③
根据偏好模型,代理可以选择其认为最佳的行动。这种方法的优点是可以直接从静态数据中学习,不需要像 PPO 那样反复地与环境交互。
出自:https://mp.weixin.qq.com/s/RyfEC7u8O0wO6YyLr1lLlA
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip