Qwen2系列模型开源,包含五个尺寸,支持27种语言,性能优异。模型使用GQA,实现推理加速和显存降低。在基准测试中超越当前领先模型。支持多种框架,可微调、量化、部署和二次开发。Qwen团队将继续探索更大模型和多模态模型。无资源部署者可体验大模型竞技场中的Qwen2-72B-instruct。
一觉醒来,Qwen2终于开源了。

Qwen2 系列模型包括五个尺寸的模型(Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B 和 Qwen2-72B),这些模型在中文和英文基础上增加了 27 种语言的高质量数据,并在多个评测基准上展现了优异的性能。Qwen2 系列模型在代码和数学能力上有显著提升,尤其是在长文本处理方面,其中
Qwen2-72B-Instruct 模型能够完美处理 128k 上下文长度内的信息抽取任务。此外,Qwen2 系列模型在安全性方面也进行了改进,通过测试显示其在生成有害响应的比例上优于或与其他模型相当。
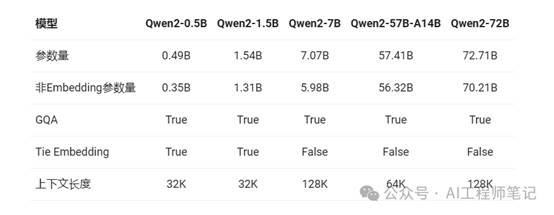
Qwen2系列所有尺寸的模型都使用了GQA,以便让大家体验到GQA带来的推理加速和显存占用降低的优势。针对小模型,由于embedding参数量较大,使用了tie embedding的方法让输入和输出层共享参数,增加非embedding参数的占比。
并且在上下文长度方面,所有的预训练模型均在32K tokens的数据上进行训练。而在使用YARN这类方法时,Qwen2-7B-Instruct和Qwen2-72B-Instruct均实现了长达128K tokens上下文长度的支持。

相比Qwen1.5,Qwen2在大规模模型实现了非常大幅度的效果提升。在针对预训练语言模型的评估中,对比当前最优的开源模型,Qwen2-72B在包括自然语言理解、知识、代码、数学及多语言等多项能力上均显著超越当前领先的模型,如Llama-3-70B以及Qwen1.5最大的模型Qwen1.5-110B。
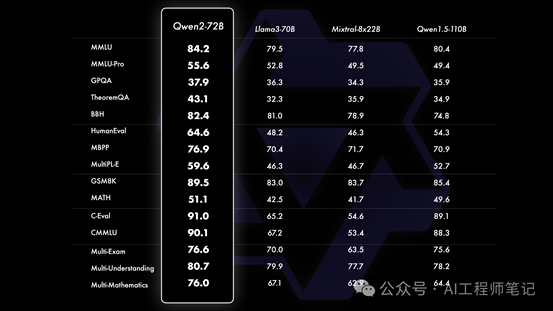
Qwen2-72B-Instruct在16个基准测试中的表现出色,相比Qwen1.5的72B模型,Qwen2-72B-Instruct在所有评测中均大幅超越,并且了取得了匹敌Llama-3-70B-Instruct的表现。
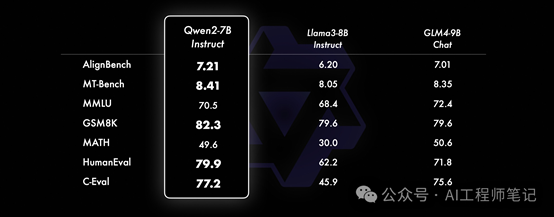
而在小模型方面,Qwen2系列模型基本能够超越同等规模的最优开源模型甚至更大规模的模型。相比近期推出的最好的模型,Qwen2-7B-Instruct依然能在多个评测上取得显著的优势,尤其是代码及中文理解上。
微调(Axolotl、Llama-Factory、Firefly、Swift、XTuner)
量化(AutoGPTQ、AutoAWQ、Neural Compressor)
部署(vLLM、SGL、SkyPilot、TensorRT-LLM、OpenVino、TGI)
本地运行(MLX、Llama.cpp、Ollama、LM Studio)
Agent及RAG(检索增强生成)框架(LlamaIndex, CrewAI, OpenDevin)评测(LMSys, OpenCompass, Open LLM Leaderboard)
模型二次开发(Dolphin, Openbuddy)

ollama run qwen2
Qwen团队还在训练更大的模型,继续探索模型及数据的Scaling Law。此外,还将把Qwen2扩展成多模态模型,融入视觉及语音的理解。敬请期待吧。
https://qwenlm.github.io/zh/blog/qwen2/
另外如果大家没有相关资源部署,不妨试试以下的大模型竞技场。
此前,知名的lmsys大模型竞技场和司南评测竞技场就已经先后上架了Qwen2-72b-instruct模型。
1、6月3日,CompassArena
司南大模型竞技场上架了Qwen2-72b-instruct,供大家体验试用!
https://opencompass.org.cn/arena
2、早在6月1日,Qwen2-72B-instruct就已经上线lmsys竞技场
https://arena.lmsys.org/
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip