MuseTaIk是腾讯团队开发的音频驱动唇部同步模型,能实时调整数字人物面部图像以匹配音频内容,支持多语言。然而,其实时性和高质量受质疑,实测推理速度较慢且效果不理想。尽管存在不足,该团队致力于推动数字人技术发展,值得肯定。用户可根据需求选择是否使用,同时作者提供了改进建议及替代服务选项。
MuseTaIk是由腾讯团队开发的先进技术,它是一个实时高质量的音频驱动唇部同步模型。该模型能够根据输入的音频信号,自动调整数字人物的面部图像,使其唇形与音频内容高度同步。这样,观众就能看到数字人物口型与声音完美匹配的效果。MuseTaIk特别适用于256x256像素的面部区域,且支持中文、英文和日文等多种语言输入。
这里面有两个点值得商榷:
1、 实时:每秒30帧能算实时吗?
2、高质量:如果腾讯某团队的标准就这么高,那我们就姑且当观众吧。
话说速度方面,经测试,在RTX4060 服务器上,10秒钟音频推理,耗时接近3分钟,耗时时长比差不多1:20。慢就慢点儿吧,有些场景还是能接受的,关键是质量。
先放两个官方案例吧,这两个案例经过测试,跟官方结果一致。。。都是不太理想:
,时长00:22
,时长00:08
还有其他的案例,我就不浪费笔墨上传了,大家感兴趣可以去这里看:
https://github.com/TMElyralab/MuseTalk
对了,多说一下,这个网站上放的有趣案例,这么模糊的视频怎么好意思往上放呢?是为了掩饰推理视频口型模糊的问题吗?还是习惯灯下玩耍?我们不得而知,主要是这会影响大公司的形象啊。
很多时候,大家都会用这些来评价一个公司的形象,比如看这个技术的效果,很容易让人联想到:哦,原来大公司的技术也不过如此!其实,更准确地说,那个赛马小分队的技术不过如此。
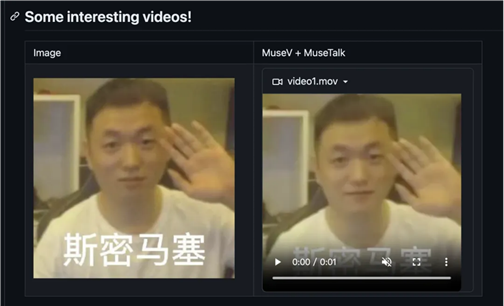
也不能就这么否认这个团队的贡献,尤其是当大家对其他技术失去信心的时候,这个崭新的技术怎么说也是给人一种希望,哪怕现在还有很多问题,不是吗?
就像这个团队的愿景那样,要引领数字人的发展,让数字人的技术普惠大众,就这个,还是应该为他们点赞,总比国内另一家公司要好吧,说是搞了很牛逼的就是,说开源,结果呢,只是营销上宣传了一波,吸引了人家的眼球,然后开源了一个ppt。腾讯这个团队还是很实在的,论文未出,代码先行。
对了,话说刚才那家准备开源的公司,明天要上线商用服务,看来开源没希望了。。。
继续说说MuseTalk吧,看看怎么把它用好,虽然不是很令人满意,但是总比wav2lip好那么点儿吧。
请看我的测试案例1:
,时长00:31
结果:
,时长00:29
测试案例2:
,时长00:37
结果:
,时长00:09
测试案例4:
,时长00:21
结果:
,时长00:09
测试案例5:
,时长00:41
结果:
,时长00:22
结语案例发完了,技术人比较追求完美,都是站在客观中立的角度评价技术质量,最后还是希望腾讯继续完善,多出好技术。至于用户嘛,根据自己的需要自己抉择。
如果腾讯的技术能满足使用,可以直接使用,它有时候也有类似的抽签效果,大部分运气还是可以的。如果希望更高质量的效果,我这里有两个办法:
1.
做高清处理。视频后期处理,我网站上提供了一条龙服务,直接生成效果更好的视频。
2. 使用更贵的服务,我网站上有标准版的服务,基于高清wav2lip模型生成。
在线使用:
https://www.mindtechassist.com/
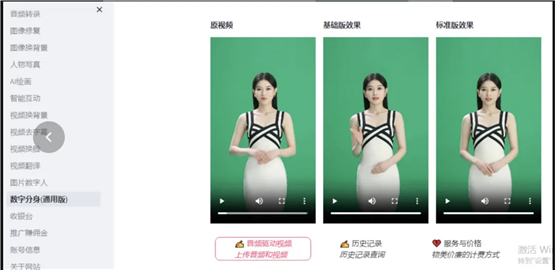
出自:https://mp.weixin.qq.com/s/M4AEOR2xBMHtrojZrvmkow
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip