文章总结了Transformer模型的整体架构及关键组件,包括词嵌入层、位置编码、编码器堆栈(含多头注意力和前馈层)、解码器堆栈(含两个多头注意力和前馈层)、输出层(线性层和Softmax层)。深入解释了注意力机制(自注意力和编码器-解码器注意力)及多头注意力的重要性,并介绍了注意力掩码在编码器和解码器中的应用。最后,描述了模型如何生成输出,包括通过线性层和Softmax层将解码器输出转换为概率分布,并使用交叉熵损失函数进行训练。
一、overview
在第一部分,已经介绍过 Transformer
的整体架构:
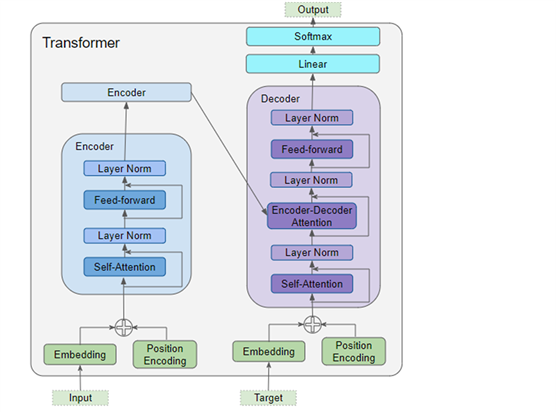
1.
数据在输入编码器和解码器之前,都要经过:
词嵌入层
位置编码层
2、
编码器堆栈包含若干个编码器。每个编码器都包含:
多头注意层
前馈层
3、
解码器堆栈包含若干个解码器。每个解码器都包含:
两个多头注意层
前馈层
4、
输出产生最终输出:
线性层
Softmax层。
·
为了深入理解每个组件的作用,在翻译任务中
step-by-step 地训练 Transformer。使用只有一个样本的训练数据,其中包括一个输入序列(英语的 "You are welcome")和一个目标序列(西班牙语的
"De nada")。
二、词嵌入层与位置编码
Transformer 的输入需要关注每个词的两个信息:该词的含义和它在序列中的位置。
1.
第一个信息,可通过嵌入层对词的含义进行编码。
第二个信息,可通过位置编码层表示该词的位置。
Transformer 通过添加两个层来完成两种不同的信息编码。
1. 嵌入层(Embedding)
Transformer 的编码器和解码器各有一个嵌入层(Embedding
)。
在编码器中,输入序列被送入编码器的嵌入层,被称为输入嵌入( Input Embedding)。
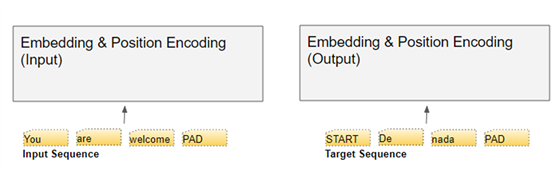
在解码器中,目标序列右移一个位置,然后在第一个位置插入一个Start token 后被送入解码器的嵌入层。注意,在推理过程中,我们没有目标序列,而是循环地将输出序列送入解码器的嵌入层,正如第一篇文章所言。这个过程被称为 "输出嵌入"( Output Embedding)。
每个文本序列在输入嵌入层之前,都已被映射成词汇表中单词 ID 的数字序列。嵌入层再将每个数字序列射成一个嵌入向量,这是该词含义一个更丰富的表示。
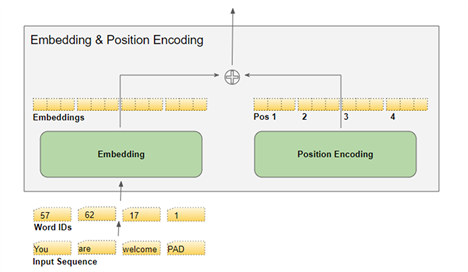
2. 位置编码(Position Encoding)
RNN 在循环过程中,每个词按顺序输入,因此隐含地知道每个词的位置。
然而,Transformer一个序列中的所有词都是并行输入的。这是其相对于RNN 架构的主要优势;但同时也意味着位置信息会丢失,必须单独添加回来。
解码器堆栈和编码器堆栈各有一个位置编码层。位置编码的计算是独立于输入序列的,是固定值,只取决于序列的最大长度。
1.
第一项是一个常数代码,表示第一个位置。
2.
第二项是一个表示第二位置的常量代码。
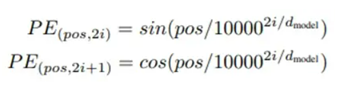
pos 是该词在序列中的位置,d_model 是编码向量的长度(与嵌入向量相同)和 i 是这个向量的索引值。公式表示的是矩阵第 pos 行、第 2i 列和 (2i+ 1) 列上的元素。
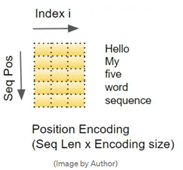
换句话说,位置编码交织了一系列正弦曲线和一系列余弦曲线,对于每个位置 pos,当 i 为偶数时,使用正弦函数计算;当 i 为奇数时,使用余弦函数计算。
三、矩阵维度(Matrix Dimensions)
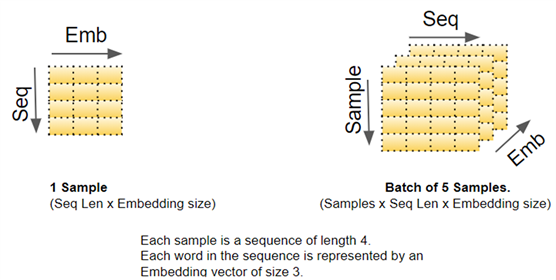
深度学习模型一次处理一批训练样本。嵌入层和位置编码层对一批序列样本的矩阵进行操作。嵌入层接受一个 (samples, sequence_length) 形状的二维单词ID矩阵,将每个单词ID编码成一个单词向量,其大小为 embedding_size,从而得到一个(samples,
sequence_length, embedding_size) 形状的三维输出矩阵。位置编码使用的编码尺寸等于嵌入尺寸。所以它产生一个类似形状的矩阵,可以添加到嵌入矩阵中。
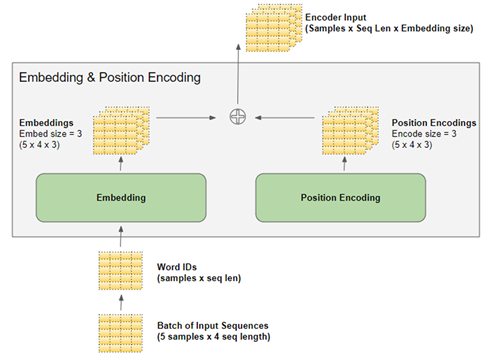
由嵌入层和位置编码层产生的(samples,
sequence_length, embedding_size) 形状在模型中被保留下来,随数据在编码器和解码器堆栈中流动,直到它被最终的输出层改变形状。[实际上变成了(samples, sequence_length,
vocab_size)] 。
以上对 Transformer 中的矩阵维度有了一个形象的认识。为了简化可视化,从这里开始,暂时放弃第一个维度(samples 维度),并使用单个样本的二维表示。
四、Encoder
编码器和解码器堆栈分别由几个(通常是 6 个)编码器和解码器组成,按顺序连接。
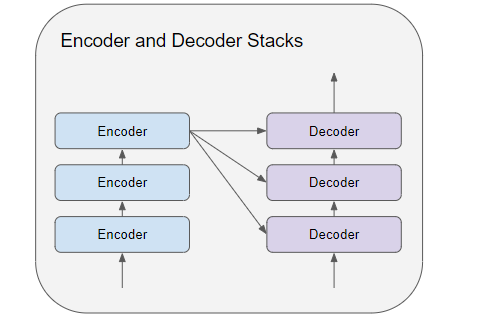
1.
堆栈中的第一个编码器从嵌入和位置编码中接收其输入。堆栈中的其他编码器从前一个编码器接收它们的输入。
2.
当前编码器接受上一个编码器的输入,并将其传入当前编码器的自注意力层。当前自注意力层的输出被传入前馈层,然后将其输出至下一个编码器。
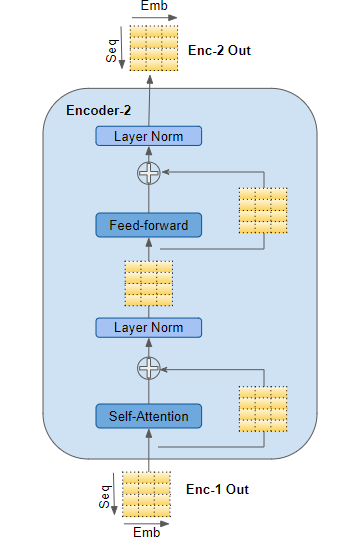
3、
自注意力层和前馈网络都会接入一个残差连接,之后再送入正则化层。注意,上一个解码器的输入进入当前解码器时,也有一个残差连接。
4、
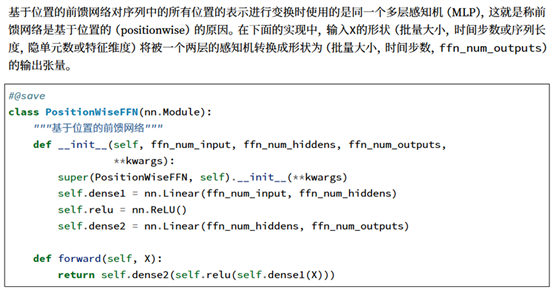
参考:在李沐老师的书,《动手学深度学习》中,P416页有对“基于位置的前馈网络”的详细解释。具体来说,该前馈网络由一个线性层,一个激活函数和另外一个线性层组成。并且这个前馈网络同样不会改变输入的形状。
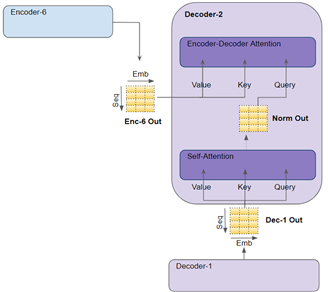
5. 编码器堆栈中的最后一个编码器的输出,会送入解码器堆栈中的每一个解码器中。
五、Decoder
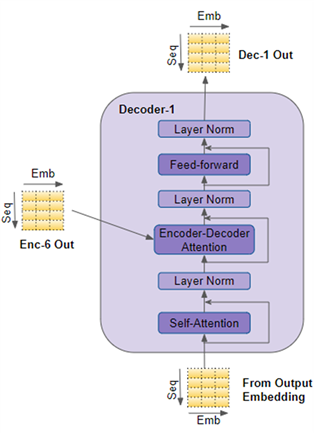
解码器的结构与编码器的结构非常类似,但有一些区别。
1.
与编码器一样,解码器堆栈中的第一个解码器从嵌入层(词嵌入+位置编码)中接受输入;堆栈中的其他解码器从上一个解码器接受输入。
2.
在一个解码器内部,输入首先进入自注意力层,这一层的运行方式与编码器自注意力层的区别在于:
·
训练过程中,解码器的自注意力层接收整个输出序列。但为了避免在生成每个输出时看到未来的数据(即避免信息泄露),使用所谓的“掩码”技术,确保在生成第 i 个词时,模型只能看到第 1 个到 第 i 个词。
·
推理过程中,每个时间步的输入,是直到当前时间步所产生的整个输出序列。
3、
解码器与编码器的另一个不同在于,解码器有第二个注意层层,即编码器-解码器注意力层 (Encoder-Decoder-attention) 层。其工作方式与自注意力层类似,只是其输入来源有两处:位于其前的自注意力层及解码器堆栈的输出。
4、
编码器-解码器注意力层的输出被传入前馈层,然后将其输送至下一个解码器。
5、
解码器中的每一个子层,包括自注意力层、编码器-解码器注意力层、前馈层,均由一个残差连接,并进行层规范化。
六、注意力-Attention
在第一部分中,我们谈到了为什么在注意力机制是如此重要。Transformer 中,注意力被用在三个地方:
1.
Encoder 中的 Self-attention:输入序列对自身的注意力计算;
2.
Decoder 中的 Self-attention:目标序列对自身的注意力计算;
3.
Decoder 中的Encoder-Decoder-attention:目标序列对输入序列的注意力计算。
注意力层通过三个参数进行计算,这三个参数称为查询(Query)、键(Key)和值(Value):
1.
在 Encoder 中的
Self-attention,编码器的输入与相应的参数矩阵相乘,得到Query、Key 和 Value三个参数。
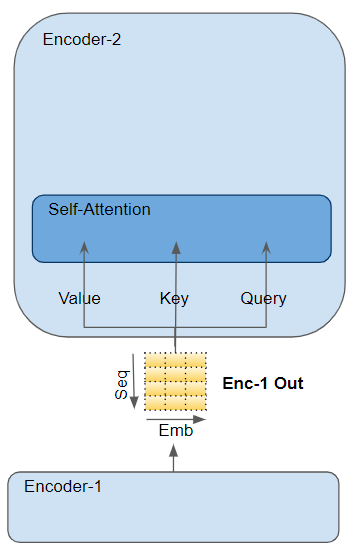
2、
在 Decoder 中的 Self-attention,解码器的输入通过相同的方式得到 Query、Key 和 Value。
3、
在解码器的
Encoder-Decoder-attention中,编码器堆栈中最后一个编码器的输出被传递给 Value 和 Key参数。位于 Encoder-Decoder-attention的 Self-attention 和 Layer Norm 模块的输出被传递给 Query 参数。
七、多头注意力(Multi-head Attention)
Transformer 将每个注意力计算单元称为注意力头(Attention Head )。多个注意力头并行运算,即所谓的多头注意力:Multi-head Attention。它通过融合几个相同的注意力计算,使注意力计算具有更强大的分辨能力。
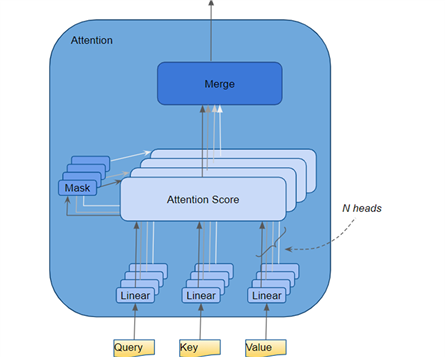
通过每个独立线性层自己的权重参数,即
Query, Key 和 Value,与输入进行矩阵乘法运算,得到 Q、K、V。这些结果通过如下所示的注意力公式组合在一起,产生注意力分数(Attention Score)。
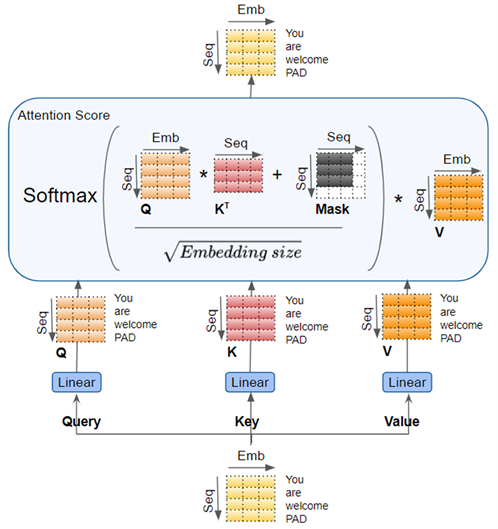
需要注意的重要一点是,Q、K、V 的值是对序列中每个词的编码表示。注意力计算将每个词与序列中的其他词联系起来,这样注意力分数就为序列中的每个词编码了一个分数。
八、注意力掩码(Attention Masks)
在计算 Attention Score 的同时,Attention 模块应用了一个掩码操作。掩码操作有两个目的:
1.
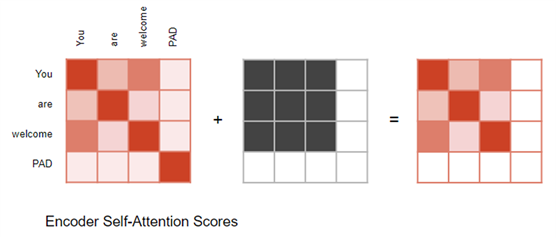
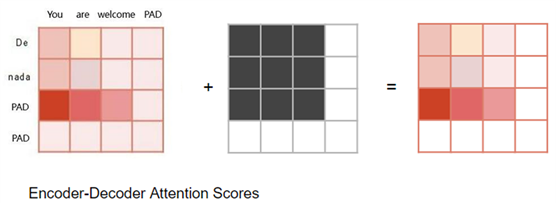
在 Encoder Self-attention 和 Encoder-Decoder-attention 中:掩码的作用是,在输入序列 padding对应的位置,将输出的注意力分数(Attention Score)归零,以确保
padding 对 Self-attention 的计算没有贡献。
·
padding 的作用:由于输入序列可能有不同的长度,因此会像大多数 NLP 方法一样,使用 padding 作为填充标记,以得到固定长度的向量,从而可以将一个样本的序列作为矩阵被输入到 Transform 中。
·
当计算注意力分数(Attention Score)时,在 Softmax 计算之前的分子上进行了掩码。被屏蔽的元素(白色方块)设置为负无穷大,这样Softmax就会把这些值变成零。
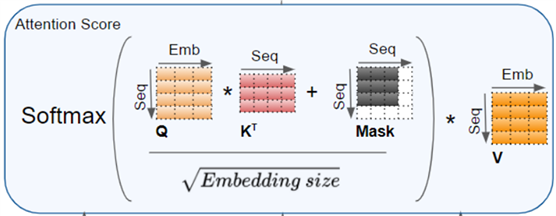
对 padding 掩码操作的图示:
Encoder-Decoder-attention 中的掩码操作也是这样:
2、
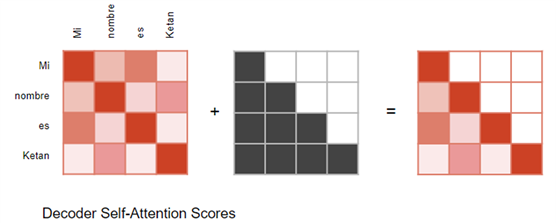
在 Decoder 中的 Self-attention 中:掩蔽的作用是,防止解码器在当前时间步预测时 ,"偷看 "目标句余下几个时间步的部分:
·
解码器处理源序列 source
sequence中的单词,并利用它们来预测目标序列中的单词。训练期间,这个过程是通过 Teacher
Forcing 进行的,完整的目标序列被作为解码器的输入。因此,在预测某个位置的词时,解码器可以使用该词之前的目标词以及该词之后的目标词。这使得解码器可以通过使用未来 "时间步 "的目标词来 "作弊"。
·
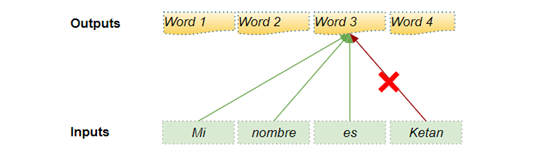
举例,如下图所示,当预测
"Word3 "时,解码器应该只参考目标词的前三个输入词,而不含第四个单词
"Ketan"。因此, Decoder 中的 Self-attention 掩码操作掩盖了序列中位于当前时间步之后的目标词。
·
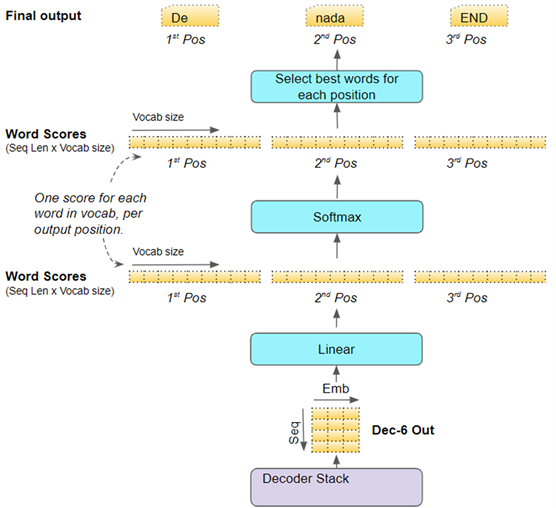
九、产生输出(Generate
Output)
解码器堆栈(Decoder stack)中的最后一个解码器(Decoder)将其输出传给输出组件,输出组件将其转换为最终目标句子。
1.
线性层将解码器向量投射到单词分数(Word Scores)中,目标词汇中的每个独特的单词在句子的每个位置都有一个分数值。例如,如果我们的最终输出句子有7个词,而目标西班牙语词汇有10000个独特的词,我们为这7个词中的每一个生成10000个分数值。分数值表示词汇中的每个词在句子的那个位置出现的可能性。
2.
Softmax 层将这些分数变成概率(加起来为1.0)。在每个位置,我们找到概率最高的单词索引(贪婪搜索),然后将该索引映射到词汇表中的相应单词。这些词就构成了 Transformer 的输出序列。
十、训练与损失函数(Training and Loss Function)
训练中使用交叉熵作为损失函数,比较生成的输出概率分布和目标序列。概率分布给出了每个词在该位置出现的概率。
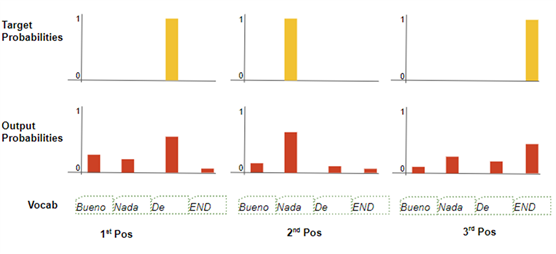
假设我们的目标词汇只包含四个词。我们的目标是产生一个与我们预期的目标序列 "De nada END "相符的概率分布。
这意味着第一个词位的概率分布中,"De
"的概率应该是1,而词汇中所有其他词的概率都是 0 。同样地,在第二和第三词位中,“nada” 和 “END”的概率应该都是 1,而词汇表中其他词的概率都是 0 。
像往常一样,对损失被计算梯度,通过反向传播来训练模型。
出自:https://mp.weixin.qq.com/s/takybSbBXkk1LC1TrUC6GQ
本文档由网友提供,仅限参考学习,如有不妥或产生版权问题,请联系我们及时删除。
客服请加微信:skillupvip